

智东西5月8日消息,据美国知名科技媒体VentureBeat报道,在近期测试中,一款新发布的大语言模型(LLM)似乎能“辨认”出自己正处于被评估状态,并对其处理信息的相关性作出评论。这引发了人们的猜想,这个反应可能是“元认知”的一个实例,即对自身思维过程的理解。这一大语言模型激发了关于AI自我意识潜力的讨论,但更值得关注的是,这说明随着规模变大,大模型可能会产生新的功能。伴随而来的还有新兴能力和成本的急剧上升,目前这些成本已达到“天文数字”。正如半导体行业只有少数几家有能力负担最新数十亿美元芯片制造厂的公司,AI领域也可能很快被仅有的几家大型科技巨头及其合作伙伴所主导,只有它们能够承担开发类似GPT-4和Claude 3等最新大语言模型的巨额费用。AI模型训练成本指数级增长:
下一个顶尖模型或需百亿美金!
随着最新模型训练成本的极速飙升,部分模型的能力已经达到甚至在某些情况下超过人类的水平。据斯坦福大学报告估计,最新的模型训练成本已逼近2亿美元。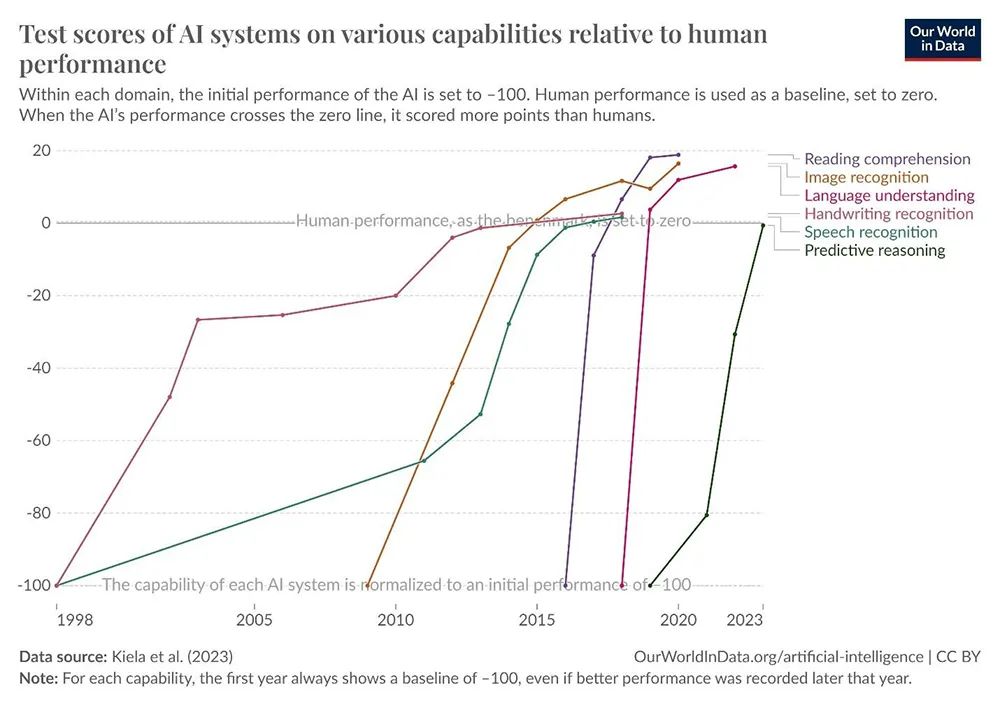
▲AI系统在与人类表现相关的各种能力上的测试分数。(图源:Our World in Data)
若这种指数级性能增长持续,AI能力不仅会快速进化,其成本也将呈指数级膨胀。知名美国大模型独角兽企业Anthropic拥有当前性能领先的旗舰级大模型Claude 3。与GPT-4一样,Claude 3是一款基础模型,通过在多元且丰富的数据集上进行预训练,形成了对语言、概念和模式的广泛理解。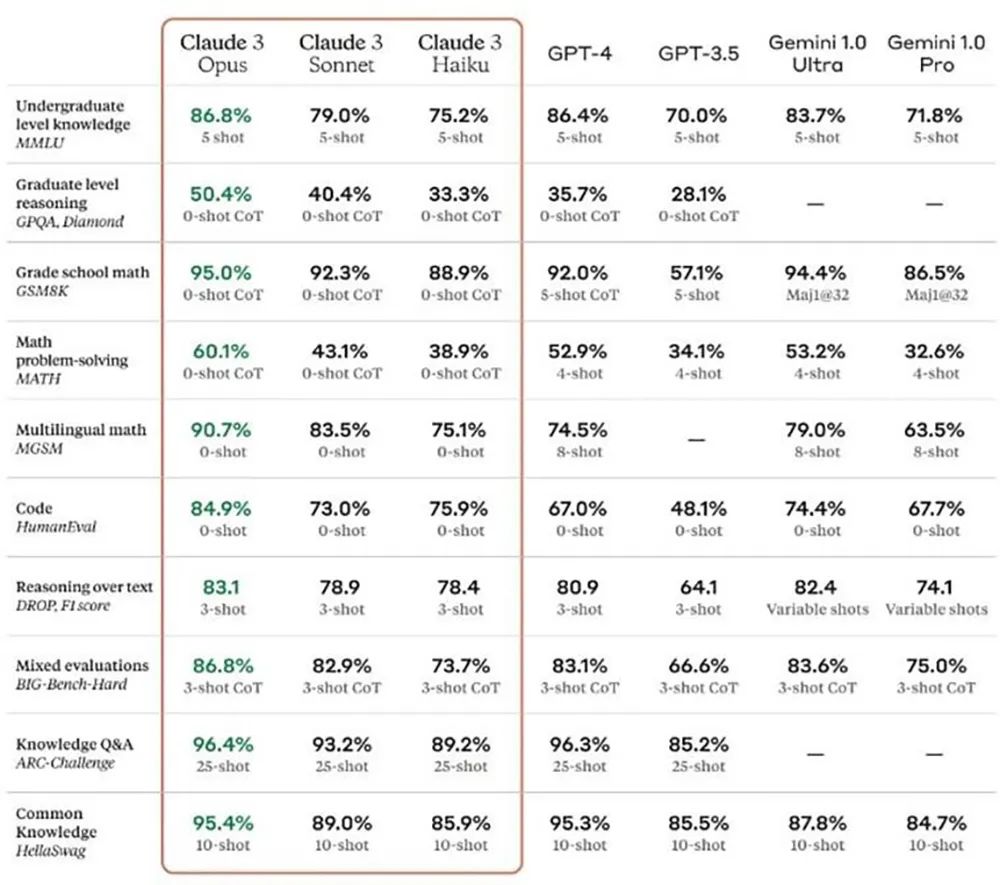
▲LLM基准性能。(图源:Anthropic)
近日,Anthropic公司联合创始人兼首席执行官Dario Amodei在一场公开讨论中透露,当前AI模型的训练成本正急剧攀升,以Claude 3模型为例,其训练费用已高达约1亿美元;正处于研发阶段并预计于2024年底或2025年初面世的新一代模型,其训练成本更是逼近10亿美元。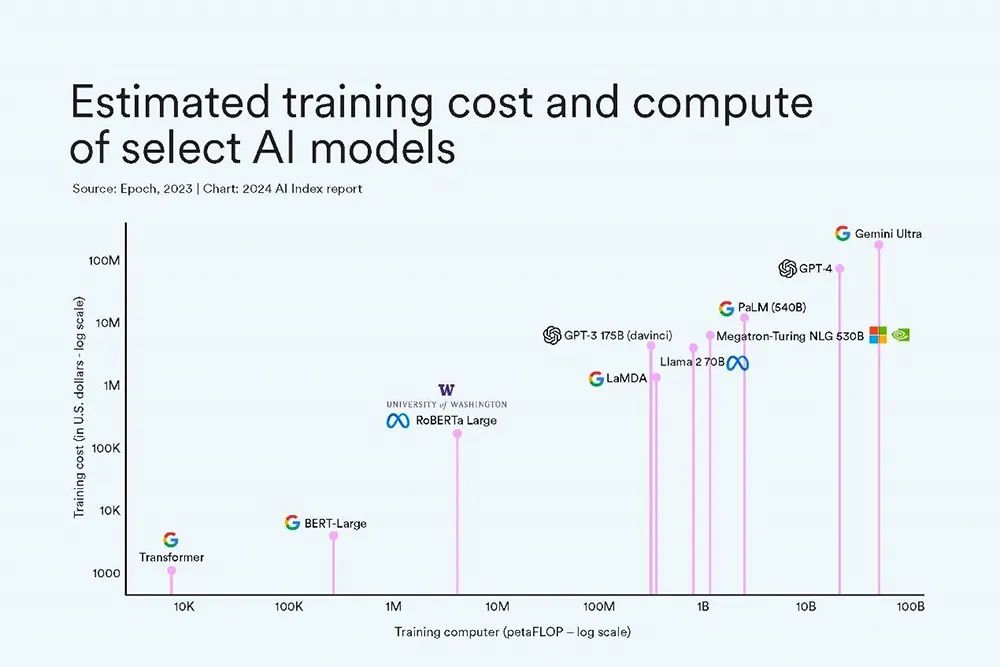
▲LLM训练成本随着模型的复杂程度而上升。(图源:Stanford 2024 AI Index Report)
面对这一成本飙升的现象,探究其背后的原因显得尤为重要。Amodei解释说,随着每一代模型复杂度的不断升级,它们所拥有的参数量级持续增加,这不仅使得模型能够处理更复杂的理解和查询任务,同时也对训练数据量和计算资源的需求提出了更高要求。据Amodei预测,到2025年或2026年,训练最新大语言模型的成本将达到50亿至100亿美元。仅极少数财力雄厚的大公司及其合作伙伴有能力构建这些基础模型。
随着技术的飞速发展,AI行业正沿着一条与半导体行业颇为相似的道路前行。回溯20世纪末,多数半导体企业均采取自设计、自建芯片的模式。彼时的半导体行业遵循着摩尔定律——即芯片性能呈指数级提升的概念,每一代新设备和晶圆厂的建造成本也随之水涨船高。面对高昂的成本压力,众多企业最终选择将产品制造外包。以AMD公司为例,该公司曾自主生产尖端半导体,但在2008年决定将其晶圆厂(简称fabs)剥离出去,以此来降低开支。由于巨额的资金成本,目前只有三家半导体公司正在使用最新的工艺节点技术建造先进的晶圆厂:台积电(TSMC)、英特尔(Intel)和三星(Samsung)。台积电最近透露,新建一座生产尖端半导体的晶圆厂成本高达200亿美元。包括苹果、英伟达、高通及AMD在内的多家公司,均选择将产品制造业务外包给这些顶尖晶圆厂。
在AI领域,这些成本增长带来的影响各不相同,因为并非所有应用场景都需要最新、最强大的大语言模型。半导体行业的情况亦是如此。例如,在计算机中,中央处理器(CPU)通常采用最新的高端半导体技术制造,而围绕其周围的内存或网络芯片则运行在较低速度下,这意味着它们无需采用最快或最强的技术来构建。若类比到AI领域,随着众多小型大语言模型替代品的涌现,如Mistral和Llama 3,它们有数十亿个参数,不像GPT-4被传有超万亿个参数。微软最近也发布了自己的小语言模型(SLM)Phi-3。据The Verge报道,Phi-3拥有38亿个参数,并且基于相对GPT-4等大语言模型更小的数据集进行训练。尽管可能无法完全媲美大型模型的效能,但小语言模型凭借其精简的体型和训练数据集,在成本控制方面展现出独特优势。这些小语言模型恰如计算机中的辅助芯片,为CPU提供高效支持,成为经济实惠的选择。对于无需跨多个数据域的完整知识应用场景,小语言模型可谓量身定制的理想工具。例如,企业可利用小语言模型针对特定内部数据和行业术语进行微调,以提供精准个性化的客户服务回复;或是通过特定行业或细分市场的数据进行训练,用于生成全面的和定制化的研究报告和答案。正如Forrester Research的资深AI分析师Rowan Curran所比喻:“并非时刻都需要跑车,有时一辆小型货车或皮卡车更为合适。未来的模型应用不会单一,而是根据不同需求选择最适宜的工具。”
过去越来越昂贵的成本导致仅有几家公司具备制造顶尖芯片的能力,类似的经济压力如今正塑造大语言模型研发的格局。这些不断攀升的成本可能将AI创新局限在少数几个主导企业手中,从而可能抑制创新与多样性。高昂的入门门槛可能会阻止初创公司和较小企业对AI发展的贡献。为了平衡这一趋势,业界需要探索小型、专业化的语言模型。它们如同庞杂系统中的重要组件,为各类细分应用提供关键高效的功能。推动开源及共同协作对于普及AI开发至关重要,这使得更广泛的参与者能够影响这一技术。通过营造包容开放的环境,未来AI技术有望为全球各个社区带来广泛的收益,并提供平等的创新机会。(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)
