

打通摩尔定律任督二脉的光网络技术,要扛起高算力的重担。苹果旗舰电脑芯片M1 Ultra、英伟达Grace CPU超级芯片、英特尔Ponte Vecchio GPU……想必会是高频答案。随着一颗颗明星芯片密集登场,蛰伏数年的多芯片封装,凭借宛如“芯片胶水”的先进封装技术将多颗芯片“粘”在一起,终于一朝红遍大江南北,成为业界公认的摩尔定律“续命良方”。
▲英特尔的Ponte Vecchio处理器
数据中心的底层算力基础设施有两大进化目标:提升算力,降低成本。叱咤信息技术产业57年的摩尔定律,凭借“每隔18~24个月芯片上晶体管数量翻番”的预言,长期被奉为指引算力飙涨的圭臬,驱动各类芯片遵循以低廉价格提供更强性能的经济路径成长。尽管工程师们竭力“续命”摩尔定律,但濒临2nm、1nm……晶体管尺寸的物理极限已近在眼前。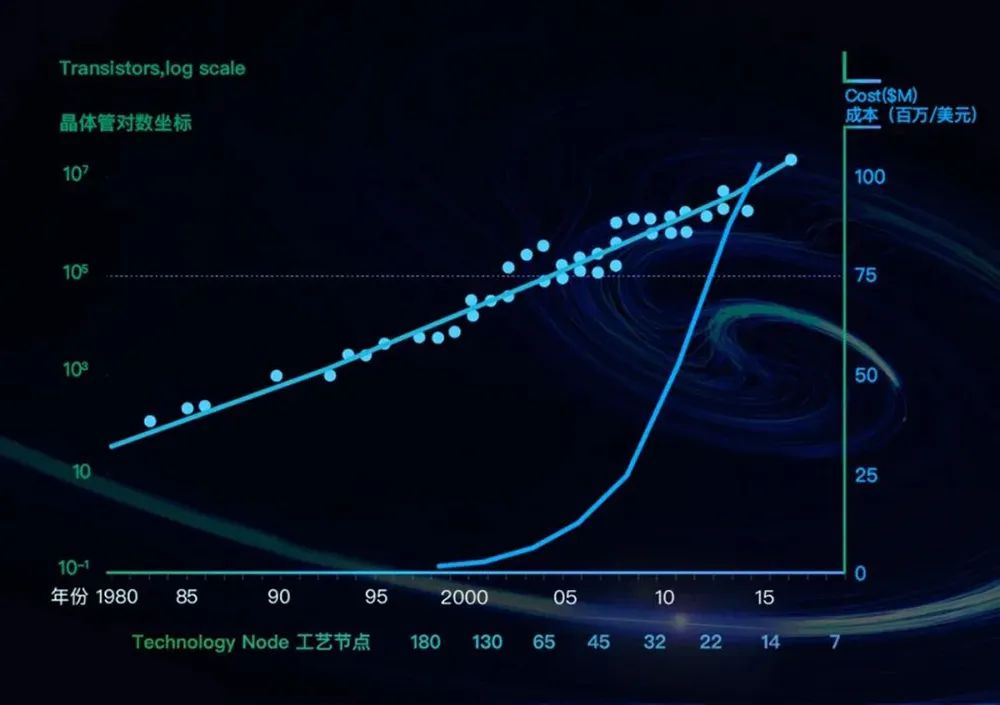
▲芯片晶体管规模与制造成本变化趋势(数据来源:美国DARPA)
挑战总是与机遇结伴,新的技术革命正在酝酿,新器件、新架构、新材料、先进封装、Chiplet等前沿技术正在开启未来之门。新的挑战也接踵而至。随着“拼装”芯片面积越来越大,基于铜互连的数据传输显得捉襟见肘。
科技的生命力在于,你永远无法预料,哪个技术会在历史长河中渐渐消亡,哪个技术又会因某个突破而大放异彩。积淀66年的人工智能(AI)技术,最近几年才迎来爆发,且发展势头日新月异,无论是工业界从“吸金猛兽”到泡沫破裂低谷期,还是学术圈涌起大模型与AIGC竞赛,变化之快都令人惊叹。据牛津大学经济学家Max Roser创立的在线数据分享平台Our World in Data披露,从2012年至今,顶尖AI算法用到的训练算力已从数百PFLOPS暴涨至数十亿PFLOPS。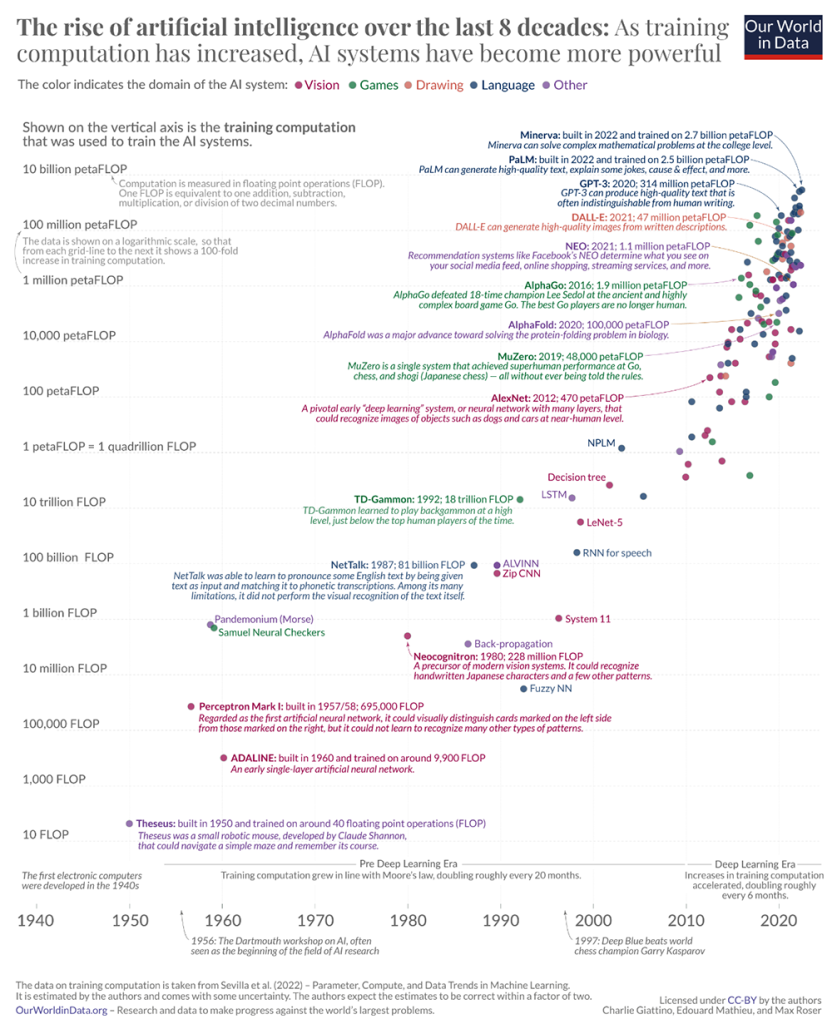
▲过去三年AI算法参数规模暴涨(图源:Our World in Data)
面对飙升的算力需求,传统数据中心算力基础设施的架构,多少有些撑不住了。第一扇门是提高单芯片算力,有两条路径司空见惯,一是迭代制造技术,二是优化架构设计。迭代制程工艺是为了持续缩小晶体管体积,以在同等面积的芯片里塞进更多晶体管,实现性能提升,但这条路正变得越来越难走。架构创新正呈百家争鸣之势态,以CPU、GPU为代表的通用芯片难以满足差异化场景的算力与能耗需求,促使异构计算大行其道。异构计算的本质是精细化分工,让不同架构的芯片各展其长,通过排兵布阵,使多类计算资源能够更大限度地发挥到实际场景中。这为特定领域架构(DSA)的繁荣提供了优渥土壤,并催生了光子芯片等创新品类。相比通用芯片,DSA芯片往往能提供更高的性能与能效。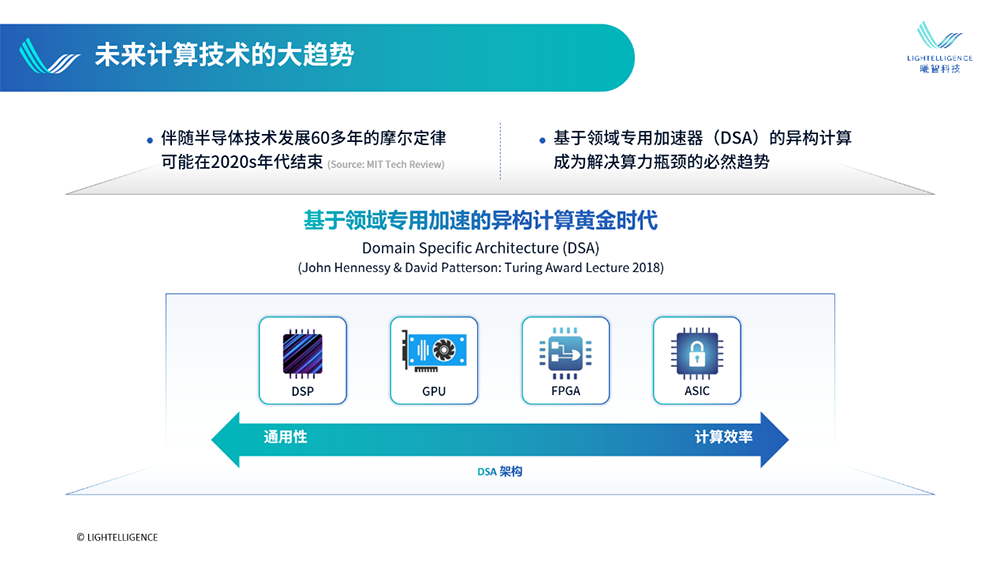
然而,仅是靠单芯片设计的优化,解决不了长期以来的芯片性能杀手——“内存墙”问题。内存容量与带宽的增速跟不上算力的增长。计算、存储单元之间的数据搬运,造成了大量不必要的功耗和延时,严重限制算力的发挥。为了解决这一痼疾,开启“实现单节点的算力提升”的第二扇门,业界探索出借助先进封装、绕过制造瓶颈的新思路。打破“内存墙”的常见解法,包括缩短通信距离、提高传输速率。前者将内存搬到离计算芯片更近的位置,后者提高内存带宽和采用更高速的互连方案,加快数据移动速度,从而提供单芯片设计难以支撑的大型计算任务算力需求。晶圆级计算和Chiplet是两大典例。晶圆级计算的基础思路是,在两个核心之间实现最快移动速率、最低能耗的办法,就是将它们放在同一块大硅片上来,实现高密度互连。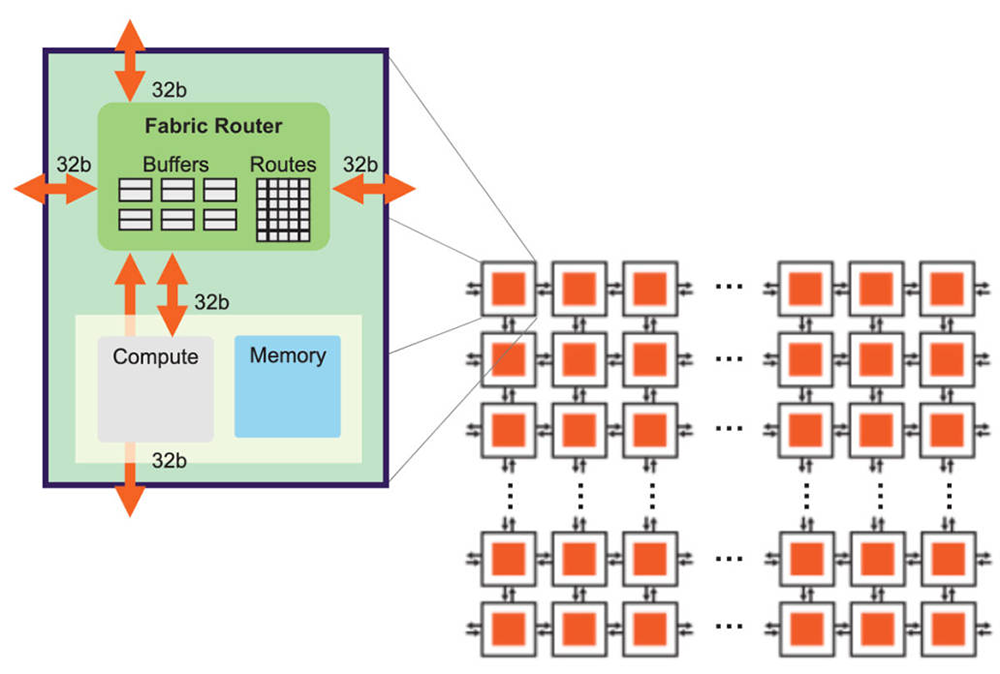
▲Cerebras晶圆级引擎(WSE)高带宽、低延迟的芯片结构
问题是芯片尺寸越大,制造良率越低,换言之制造成本会急剧上涨。晶圆级计算的解法是让一块晶圆级巨型芯片容纳足够多的冗余核心,来摊薄出现一定瑕疵故障几率的风险。Chiplet则巧妙地绕过了这个难题:将不同功能、不同工艺制成的小芯片模块及高带宽内存,用先进封装技术拼在一起,既避开了良率挑战,又能通过灵活组合,提供更高性价比的算力。
▲AMD第4代EPYC CPU Chiplet设计
但即便如此,数据中心仍然饱受数据传输带宽与延迟不高的困扰。受制于此,实际业务中发挥价值的算力资源远少于理论算力峰值,而那些多余的功耗、成本,都得由数据中心来买单。因此,提高每个节点的算力利用率,成为提高算力所需通过的第三扇门。业界正尝试从系统级设计思路出发,探索更有效的资源池化和网络互连,来提高服务器集群的算力利用率。在这之中,芯片内部互连、芯片与芯片之间的互连,都是影响整个系统数据传输带宽、延迟的关键。过去CPU、GPU等计算芯片和存储芯片被放在一块基板上,通过PCIe来连接。然而面对愈发庞大的工作负载需求,有限的PCIe带宽后继乏力。台积电主导了通过在硅中介层(interposer)铺设高密度铜导线来提高带宽的思路,已用到高带宽内存(HBM)设计中,被AI芯片公司广泛采用。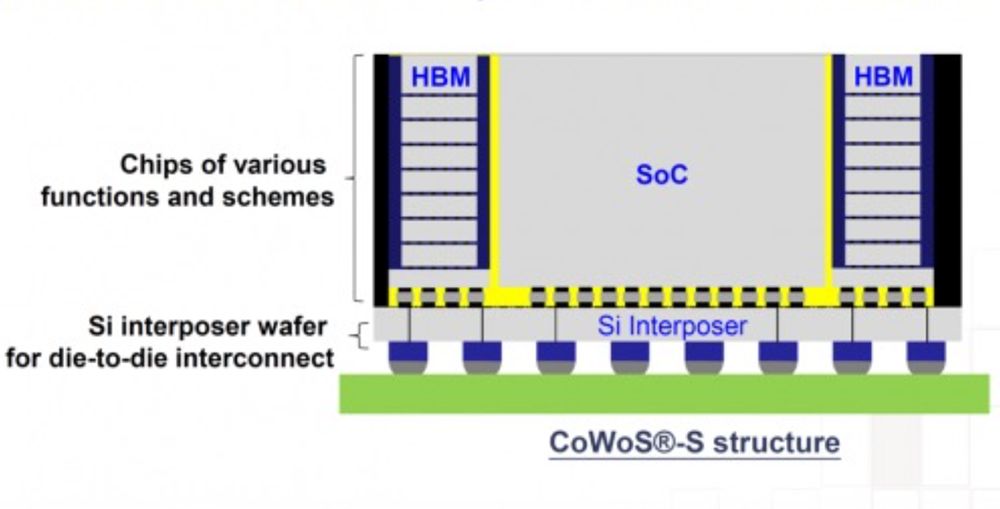
▲台积电CoWoS-S先进封装技术架构
但围绕传统铜互连的改良方法是治标不治本,芯片面积小尚可,随着需要搬运的数据越来越多,芯片面积越来越大,数据传输距离越来越长,也就越来越受到铜导线发热和带宽的限制。要满足下一代AI系统的性能、功率、带宽需求,需要新的互连方案。
当你上网查询资料、开视频会议,数据会通过光纤网络,传输至遥远的数据中心。等进入芯片内部,基于铜导线的互连开始负责将数据在计算单元、存储芯片之间来回搬运。但物理材料的局限性,使得铜互连仅适合近邻数据传输。随着晶圆级计算、Chiplet等大芯片设计方案日渐盛行,暴涨的算力需求驱动拼装的核心或Chiplet数量越来越多,芯片面积越来越大,而数据传输距离变长,铜互连的边际成本就会急剧上升,导致延迟、功耗增加,性能严重下降。此时,如果能将光子引入片上互连,也许能大幅提升计算单元与存储之间的通信效率。假如将芯片内的数据传输视作城市里的交通,铜互连好比骑单车,适合短途出行,跑长途就得面临速度有限、非常消耗体能等问题,光互连则像乘地铁,对于城市内较长距离的出行,是更高效且不费力的选择。相比铜互连,随着传输距离变长,光信号的损耗要比电信号低几个数量级。理想情况下,对超过1~2cm的数据传输,使用光作为传输介质更具优势,为解决带宽及容量瓶颈带来更多可能。2017年创立的曦智科技,是少有的片上光网络先行者。在上周五举办的第二届中国互连技术与产业大会上,它刚刚预告了世界上第一款基于片上光网络(oNOC)的计算产品。▲片上光网络可实现高效的计算/存储互连(图源:曦智科技)
在AI芯片领域,曦智科技是一家相当特立独行的创企,也是迄今全球融资规模最高的光子计算公司。2017年,一篇由曦智科技创始人兼CEO沈亦晨为第一作者和通信作者的光学AI计算论文登上顶级期刊《自然·光子学》的封面,从此掀开了集成光学替代电子计算芯片革命的扉页。
踏上商业化道路后,曦智科技团队逐渐意识到,光子计算带来的算力提升再大,内存带宽跟不上也是白搭,要满足数据中心飙涨的算力需求,还需进行一场“铜退光进”的技术革新。因此,他们研发了一款用于AI计算的片上光网络系统,目前已完成相关技术验证并流片,预计2023年向客户送样。
▲曦智科技首个基于片上光网络的计算芯片(图源:曦智科技)
如图,中间黑色部分是曦智自研的AI计算电芯片。曦智科技将一块集成硅光芯片和一块电子芯片进行垂直堆叠,用光波导替代铜导线,让片上光网络进行数据传输,使芯片之间的距离变得最小,理论上可实现比现有transceiver高1000倍以上的集成密度。其片上光网络系统由512个波导通道组成,单个波导通道的最长广播距离大概50mm,广播延时1ns,单通道频率4GHz,片上总带宽2Tbps。“这种设计之前在光通信行业是不存在的。”沈亦晨告诉智东西,以前光芯片和电芯片就像两幢楼,要进行通信,则需先下楼、走到另一幢楼、再上楼。而将电芯片堆叠在光芯片上,则像楼上楼下,只需搭乘楼内电梯,通信成本低很多。据他分享,相比传统光芯片与电芯片分开封装的方式,将电芯片堆叠在光芯片上的光电转换功耗和延迟成本会低得多。经实测,oNOC计算产品能在1ns内完成多个计算核之间All-to-AIl的数据广播,这将大幅提高了每一个计算核的算力利用率。尽管少数海外公司也在探索光电芯片垂直堆叠,但曦智科技联合创始人、CTO孟怀宇告诉智东西,片上互连系统需要大面积堆叠,从集成度的角度考虑,曦智科技已经做到在硅光芯片中集成上万个器件,这是已公开跑通的系统中绝无仅有的,技术壁垒很高,目前全球从工程上掌握片上光网络技术的企业可能不超3家。下一步,曦智科技计划优化oNOC技术的通用性,使其能与第三方电芯片适配,并将积极寻求与更多电芯片设计厂商的合作。除了提升芯片内部的带宽外,光网络也正拓展至更多服务器之间,酝酿一场改变数据中心通信效率的技术革命。
如果说片上光网络像穿梭于城市的地铁系统,那么芯片与芯片之间的通信则相当于更远距离的两座城市之间的交通。面对庞大的计算需求,传统数据中心架构日渐式微,从集中式走向分布式计算。分布式架构将计算、存储、网络、安全等资源分别组建成虚拟资源池,进行统一调配管理,实现资源集约化。这样一来,每颗计算芯片都能访问更大的存储资源,从而提高整体系统的算力利用率。传统数据中心中,数据在成百上万个服务器之间搬运。服务器中各芯片间的距离较短,此前主要通过铜导线传输数据。但正如前文的类比,铜导线更像骑单车,市内骑行尚有余力,跨市跨省的长途旅行就会很耗费时间和能量。如果想构建更大规模的可扩展系统,进一步提升资源池化能力,支撑起未来海量数据和计算任务对系统规模、带宽和功耗的需求,那么能支撑芯片从毫米到千米范围内通信的光网络,将是实现机架到机架传输的更理想选择。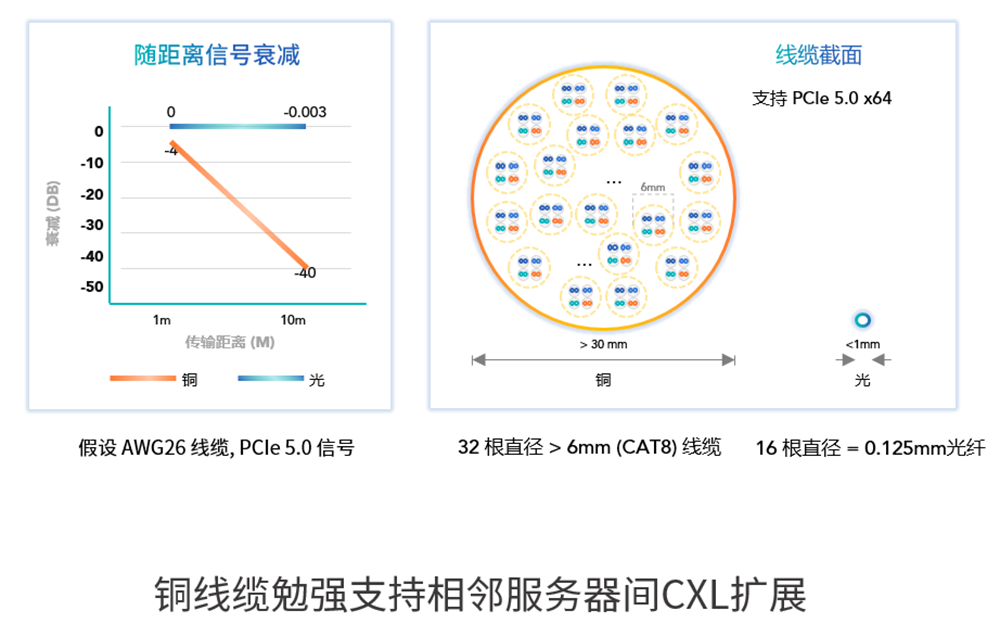
▲铜导线传输信号随距离衰减,与光纤线缆截面对比(图源:曦智科技)
“我们觉得CXL标准接口是一个最合适的未来接口。”沈亦晨认为,近年被主流芯片公司及数据中心公司争相推崇的CXL(Compute Express Link),将成为硬件资源解耦架构的主导协议。此前在数据中心分布式计算中,服务器内的多芯片连接常用PCIe,多服务器的连接常用以太网,在不同设备之间的通信开销较高,延迟要比出发点就是实现多芯片与内存高效互连的CXL差很多,令效率大打折扣。从一个机柜到另一个机柜,以太网的延迟大约在3μs至10μs级别。而CXL的缓存一致性远优于以太网,延迟大约在300ns以下,这样的架构才能满足计算解耦、内存共享等对延迟的苛刻要求。今年8月发布的CXL 3.0标准带来了更多改进,实现了内存共享和设备到设备的通信,让成百上千台服务器的互连和资源共享成为可能。内存成了独立可扩展的资源,能根据工作负载需求进行动态分配,通过这样提高资源利用率,数据中心将极大节省在存储上的开销。沈亦晨相信,CXL标准进一步通行,有望可重构解耦现有数据中心的结构。在他看来,第一阶段可能会是在一台服务器内的资源池化,铜导线尚能勉强支持将内存和计算单元连在一起的CXL扩展,但未来在超过2m以上距离的服务器之间用CXL实现资源池化,铜导线的成本会非常高昂,此时光提供了更大范围的高效可扩展性,基于光的CXL将走向主流。曦智科技正在探索片间光网络技术(oNET)的研发,用光纤实现更远距离的芯片与芯片之间的数据传输,也就是用光互连发挥出像英伟达NVLink互连技术这样的作用。这将为服务器之间的通信搭建起一条更高运力的通路。
▲硅光CXL可能的产品形态(图源:曦智科技)
从光电混合计算到片上网络、片间网络再到翻山跨海的远程通信,光子能够贯穿数据处理的整个旅途,优化数据中心的算力和成本。光电混合计算芯片PACE的成功验证了光子计算的优越性。如今,曦智科技以光子计算产品及解决方案为基础,延伸至光网络相关研发,让计算芯片间通信速度追上算力增长的脚步。而这些探索的终极目标,都是满足数据中心对更高算力、更低延时、更低功耗的需求。沈亦晨说:“未来的计算系统里,计算、存储和传输就像形成一个水桶的三块木板,变得越来越密不可分,如何利用大规模光电混合集成技术去优化这三块木板,增加全系统的算力一直是曦智科技的主要使命。同时,我们也需要更多公司能够加入到这个新型的生态建设里来,各自分工,才能加速整个行业的发展。”数字革命才刚刚开始,芯片创新充满无限可能。围绕光子计算与光网络的探索,终将在数据中心掀起新的飓风。
(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)