商用高性能计算处理器市场主要被NVIDIA、AMD和Intel3家公司长期占据,在面向E级计算 的 高 性 能 处 理 器 中,AMD 最 新 的Instinct MI250X处理器双精度浮点运算能力已经高达95.7TFlops,NVIDIA和Intel最新发布的高性能处理器峰值性能也均达到了数十 TFlops。本文主要分析和探讨国际上面向 E 级计算的先进高性能处理器的核心运算架构,包括 Fujitsu A64FX、NVIDIA H100、AMD MI250X 和 Intel PonteVecchio 4款高性能处理器,着重关注运算资源组织结构、数据和指令级并行方式、领域专用加速结构 DSA、支持数据类型和算力等方面,并总结和展望主流高性能处理器的运算架构研究发展现状和趋势,以期为国内自主研发面向后 E 级计算的高性能处理器提供技术参考和借鉴。
1、Fujitsu A64FX
Fujitsu A64FX 是由富士通(Fujitsu)在2018年发布的,主要用于构建日本原计划研发的首台 E级计算机 “后 京”(POST-K)[6],后 改 名 为 “富 岳”(Fugaku)并于2020年6月发布。目前,“富岳”超算在全球高性能计算机 TOP500榜单中排名第2,集成的 A64FX处理器芯片数量高达158976片,全机峰值性能为0.537212EFlops,Linpack实测性能为0.44201EFlops,效率为82.28%。

A64FX处理器结构框图如图1所示,分成4个处理核心存储组 CMG(CPU MemoryGroup),每个 CMG 包含13个同构核心、L2Cache和存储控制器,其中12个核心为计算核心,1个为辅助核心,用于运行操作系统和I/O 操作,全片共52个核心。每个 CMG 集成8GB 容量的 HBM2存储器,全片总容量为32GB,总带宽为 1024GB/s。片上还集成了 PCIe3.016x接口和富士通特有的TofuD互连网络接口与路由器,这些外接口与4个CMG 通过片上网络 NoC(NetworkonChip)实现互连和通信。
A64FX 处理器采用台积电7nm 工艺和 CoWoS封装实现,集成了87.86亿晶体管,最高运行频率为2.2GHz,峰值性能为3.3792TFlops,功耗为200W。
2、NVIDIA H100
NVIDIA 在 HPC 和 人 工 智 能 AI商用处理器市场占比非常高,一直是图形处理器 GPU领域的佼佼者。TOP500最新榜单排行前20的超算系统中有11台采用了 NVIDIA 的 GPU 实现。目前这些超算算力主要由前两代 GPU 产品 V100和A100提供。
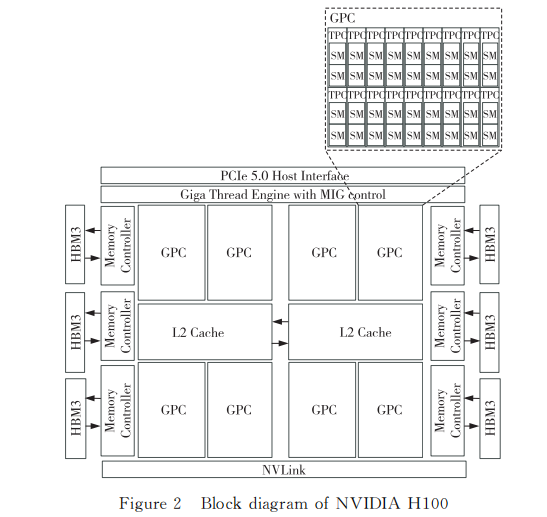
NVIDIA 于2022年3月发布了面向 HPC 和AI的最新款高性能处理器 H100GPU。该处理器采用 新 一 代 HOPPER 架 构,基 于 上 一 代 GPUA100的 Ampere架构主要进行了如下扩展:
- (1)集成第4代张量核心(TensorCore);
- (3)流多处理器 SM内 CUDA核 数 量 翻 倍;
- (5)新增 TMA引 擎,增 强 异 步 数 据 传 输 功 能;
- (6)定 制Transformer引 擎,以 加 速 Transformer 模 型 训练;
- (7)更新换代 HBM3、PCIe5.0和第4代 NVLink等存储和外接口。
H100的结 构 框 图如 图 2 所 示,全 片 实 际(非 GH100架构满配)集成了132个 SM,每2个SM 构成一个 TPC(TextureProcessingCluster),9个或8个 TPC构成一个 GPC,全片共8个 GPC。每个SM 包含128个 FP32(单精度浮点)CUDA核和 4 个 TensorCore,全片共 16896 个 CUDA核,528个 TensorCore。H100GPU 片上集成了50MB的L2Cache,5个16GB容量的 HBM3,存储总容量为80GB,总访存带 宽 为 3 TB/s。此 外,片 上 还 集 成 了 PCIe 5.0 16x和第 4 代 NVLink 外接口,支 持 与 CPU或 GPU 高速互连。H100GPU 采 用 台 积 电 为 NVIDIA 定 制 的4N 工艺和 CoWOS封装实现,全片集成了800亿个晶体管,运行频率为1.776GHz(根据双精度浮点峰值性能和全片集成运算部件数量推算得到),峰值性能为 60.0TFlops,TDP功耗为700 W。
3、AMD MI250X
为进一步加强在 HPC领域的影响力,AMD将旗下通用 GPUGP拆分成 RDNA(RadeonDNA)和 CDNA(ComputeDNA)架构,前者主要面向实时游戏和图形处理,后者主要面向 HPC应用。CDNA 架构目前已经发展到第2代 MI200,代表高性能处理器是 MI250X发布于2021年11月,并用于构建美国E级超算“前线”(Frontier)。“前 线”超 算 发 布 于 2022 年 5 月 30日,在全球高性能计算机 TOP500榜单中排名第1,集成的 MI250X 处理器芯片数量高达36992片,全机峰值性能为1.68565EFlops,Linpack实测性能为1.102EFlops,效率为65.38%。
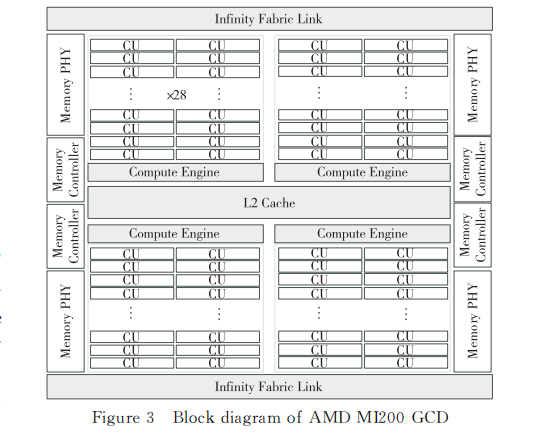
MI250X处理器采用 AMD 特有的先进3D封装技 术 集 成 2 个 MI200 GCD(GraphicsComputeDie),2个 GCD 间通过无尽互连IF(Infinit Fabric)接口直连实现高带宽通信。MI250X 处理y器中单个 GCD(非 MI200满配)结构框图如图3所示,包含4个计算引擎 CE(ComputeEngine),每个 CE内含27或28个计算单元 CU(ComputeUnit)。MI250X 处 理 器 全 片 2 个 GCD 共 220 个CU;集成了16 MB 的 L2Cache;8个16GB 容量的 HBM2E,总容量为128GB、总带宽为3.2TB/s;8路IFLink或者6路IFLink加PCIe4.0接口(2路IF接口可重构配置成 PCIE4.0接口),支持GPU 和 CPU 多种可扩展高速互连。
MI250X处理器采用台积电 N6工艺实现,全片集成了 582 亿个晶体管,运行频率最高为 1.7GHz,峰值性能为 95.7TFlops,是首个峰值性能接近 100 TFlops的 高 性 能 处 理 器,TDP 功 耗 为560 W。
4、Intel PonteVecchio
Intel一直致力于重新赢得 HPC 领域的高性能处理器领导者地位,其精心打造的面向 E 级计算的高性能处理器 PonteVecchio于2021年8月在Intel体系结构日上发布,2023年1季度已上市。PonteVecchio处理器将用于构建2台美国 E级计 算 机 “极 光”(Aurora)和 “酋 长 岩”(ElCaptain),并为其提供主要算力,预计“极光”的超算峰值性能为1.0EFlops、“酋长岩”的超算峰值性能为2.0EFlops。
PonteVecchio处理器采用 X HPC架构实现,结构框图如图4所示。
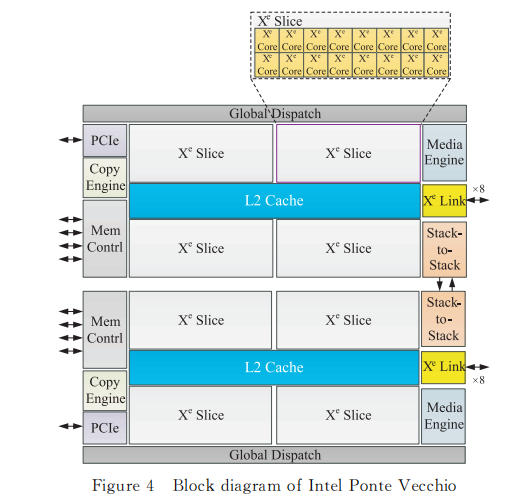
PonteVecchio处理器通过多种先进封装集成2个同构的 Stack,Stack 间通过高速直连接口互连;全片共8个 Slice,每个 Slice包含16个 X 核心,总计128个 X 核心;全片集成了144 MB的共享 L2Cache;8个 HBM2E,总带宽超过5TB/s;16路 X Link,支持多 CPU 间高速直连,总带宽超过2TB/s;此外还集成了 PCIe5.0接口。
PonteVecchio处理器采用 5 种先进工艺实现,包括台积电5nm、7nm 和Intel 7nm 等,全片多 达 47 个 Tile (Die),通 过 Foveros和 EMIB等多种先进封装技术集成。全片集成了超过1000亿个晶体管,运行频率为1.373GHz(根据单精度浮点峰值性能和全片集成运算部件数量推算得到),峰值性能超过45.0TFlops(双精度浮点与单精度浮点相同),功耗暂无官方数据。
5、小结
4款面向 E级计算的高性能处理器参数与对比统计信息如表1所示,4款处理器均采用台积电7nm 或更先进工艺,集成密度高、晶体管数目庞大,通过先进封装集成高带宽存储器 HBM 提供TB/s级访存带宽,并采用商用大容量存储颗粒。
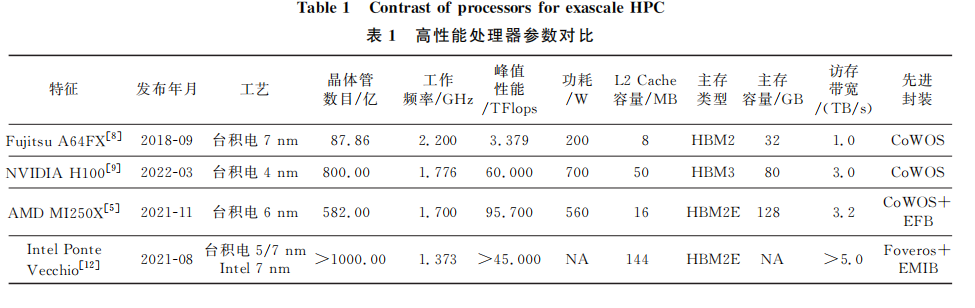
工作频 率 方 面,A64FX 的 较 高,达 到 了 2.2GHz,H100 和 MI250X 的 均 在 1.7 GHz 左 右,PonteVecchio的最低为1.373GHz;峰值性能方面,A64FX 是唯一峰值性能低于10.0TFlops的处理器,其他3款的均超过45.0TFlops,MI250X的甚 至 高 达 95.7 TFlops;功 耗 方 面,H100 和MI250X的均超过 500 W,PonteVecchio的无官方数据,预计也会超过500W。先进封装技术方面,均采用了2.5D 或3D 封装,MI250X 还通过 EFB封装集成了2个 GCD,而 PonteVecchio采用 Foveros+EMIB 封装集成超过47个 Die,并通过多种先进工艺分别实现了计算 Die、存储 Die和互连 Die。温馨提示:请购买过“架构师技术全店资料打包汇总(全)”的读者,在“架构师技术联盟”微店留言,凭购买记录获取<服务器基础知识全解(终极版)>PDF阅读版本,本店后续更新也会一如既往免费赠阅给购买过全店打包汇总的读者。
现在购买“架构师技术全店资料打包汇总(全)”随打包发送<服务器基础知识全解(终极版),182页>PDF阅读版本和可编辑PPT版本。现在下单最划算(活动优惠并享更新免费赠阅),后续价格会随资料增加上涨。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(39本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”包含服务器基础知识全解(终极版)pdf及ppt版本,后续可享全店内容更新“免费”赠阅,价格仅收239元(原总价399元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。