54百亿参数大模型进化树重磅更新!85页盘点LLM发展史,附最详细prompt技巧
新智元报道
新智元报道
【新智元导读】4月底火爆开发者社区的最全LLM综述又更新了!这次,LLM的进化树末端已经从GPT-4和Bard更新到了Vicuna和Falcon。
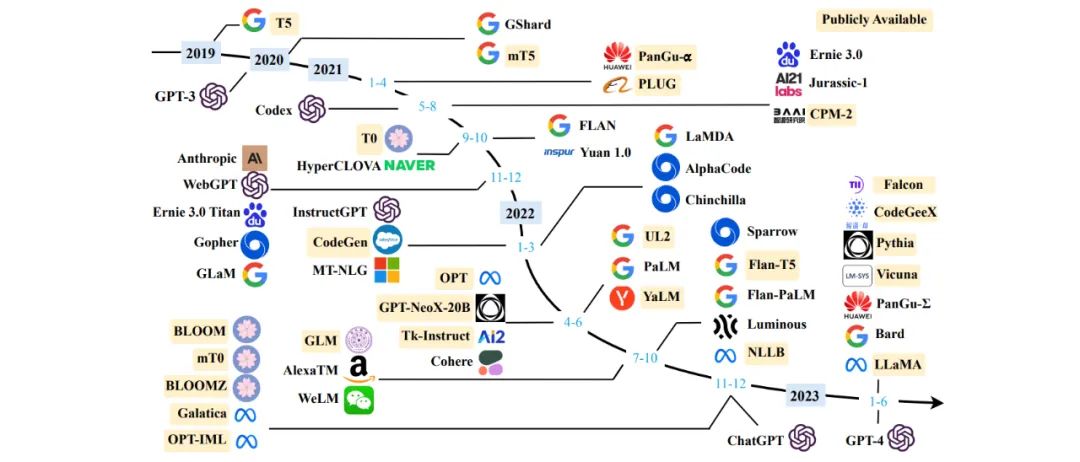
LLM大事记
LLM发展概述(arXiv上LLM相关论文数量的趋势)
LM研究发展阶段
LLM涌现的能力
LLM的关键技术
GPT系列模型的技术演进
LLaMA家族进化图
提示
复杂任务规划
实验
指令微调
能力评估
微信扫码关注该文公众号作者
戳这里提交新闻线索和高质量文章给我们。
来源: qq
点击查看作者最近其他文章