来源 | OSCHINA 社区
作者 | 腾讯云中间件
原文链接:https://my.oschina.net/u/4587289/blog/10089900
导语
本文主要介绍了 CKafka 在跨洋场景中遇到的一个地域间数据同步延时大的问题,跨地域延时问题比较典型,所以详细记录下来做个总结。
一、背景
为了满足客户跨地域容灾、冷备的诉求,消息队列 CKafka 通过连接器功能,提供了跨地域数据同步的能力,支持跨地域秒级准实时数据同步。
整体的架构图:
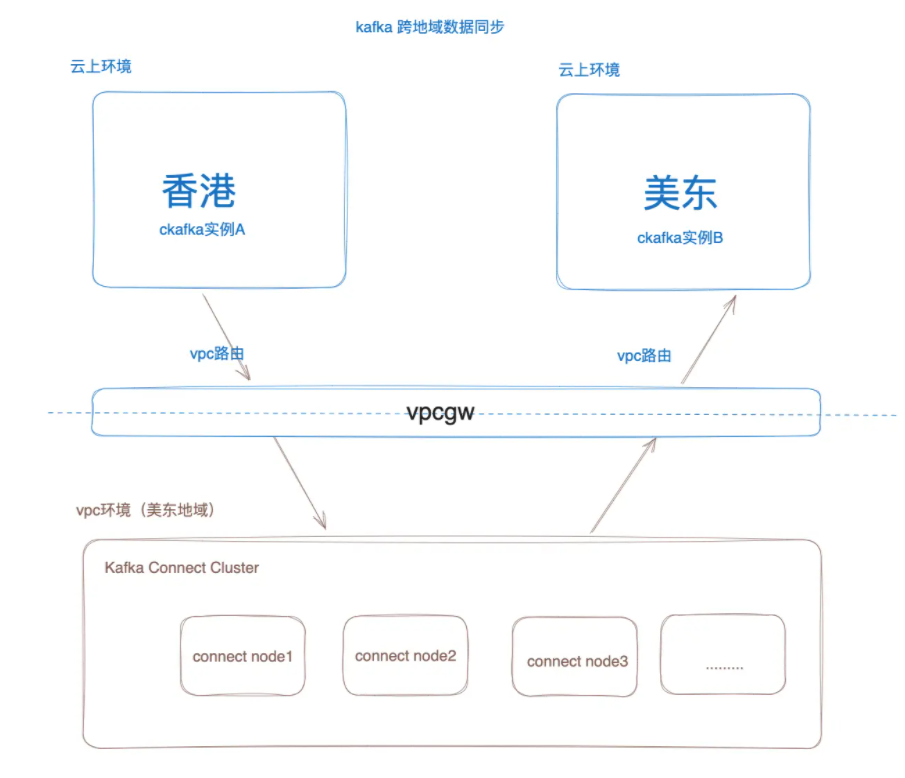
如上图所示,CKafka 跨地域数据同步能力,底层基于 Kafka Connect 集群实现,并通过 Vpcgw Privatelink 打通云上环境。
数据同步主要流程如下:
1. Connect 集群初始化 Connect Task,每个 Task 会新建多个 Worker ConsumerClient(具体多少取决于源实例的分区数)从源 CKafka 实例拉取数据。
2. Connect 集群从源实例拉取数据后,会启动 Producer 发送数据到目标 CKafka 实例。
在某个客户业务场景中,客户希望通过跨地域同步能力,把香港 CKafka 实例的数据同步到美东 CKafka 实例,在使用过程中引发了一个跨地域延时的诡异问题!
二、问题现象
客户在使用跨地域同步能力的时候,发现数据从香港 -> 美东同步数据的延时非常大,并且能明显的看到 Connect 作为 Consumer 去源实例(香港)消费拉取数据的消息堆积非常大。
消息堆积

根据过往的经验,我们国内地域的同步不会出现这么大的延时,为什么这次的跨地域会有这么大的延时呢?
三、问题分析
消息堆积常见的原因
Kafka 在生产消费过程中,出现消息堆积常见的原因主要有以下几点:
● Broker 集群负载过高:包括 CPU 高、内存高、磁盘 IO 高导致消费吞吐慢。
● 消费者处理能力不足:如果消费者的处理能力不足,无法及时消费消息,就会导致消息堆积。可以通过增加消费者的数量或者优化消费者的处理逻辑来解决该问题。
● 消费者异常退出:如果消费者异常退出,就会导致消息无法及时消费,从而在 Broker 中积累大量未消费的消息。可以通过监控消费者的状态和健康状况,及时发现并处理异常情况。
● 消费者提交偏移量失败:如果消费者提交偏移量失败,就会导致消息重复消费或者消息丢失,从而在 Broker 中积累大量未消费的消息。可以通过优化消费者的偏移量提交逻辑,或者使用 Kafka 的事务机制来保证偏移量的原子性和一致性。
● 网络故障或者 Broker 故障:如果网络故障或者 Broker 故障,就会导致消息无法及时传输或者存储,从而在 Broker 中积累大量未消费的消息。可以通过优化网络的稳定性和可靠性,或者增加 Broker 的数量和容错能力来解决该问题。
● 生产者发送消息速度过快:如果生产者发送消息速度过快,超过了消费者的处理能力,就会导致消息堆积。可以通过调整生产者的发送速度,或者增加消费者的数量来解决该问题。
基于以上原因,我们首先排查了 Connect 集群所有节点和源目标 CKafka 实例所有节点的负载,发现各项监控指标都很健康、集群负载很低,ConnectConsumer 消费能力也没有出现异常和性能瓶颈。
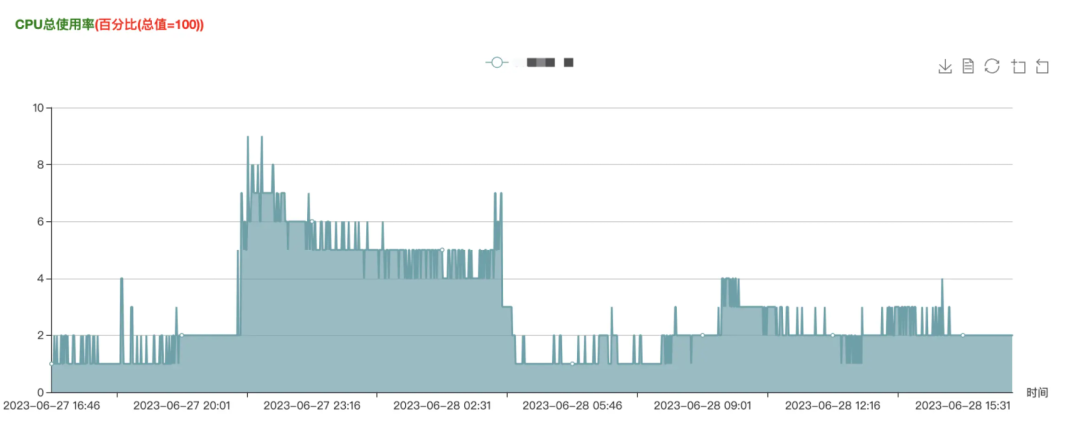
但是单次拉取消息的速率却很低,平均消费速度 325KB/s,这个是不符合预期的。

(注:上图中的 bytes-consumed-rate 指标代表每秒消费的字节数)
既然集群负载没有问题,于是我们进行了更深层的排查分析:
第一阶段分析:排查网络速率
消息延时大,我们首先想到的就是网络问题,所以立刻着手压测网络。通过 Iperf3 、Wget 探测网络速率。
Iperf3 压测,速度在 225Mbps 。
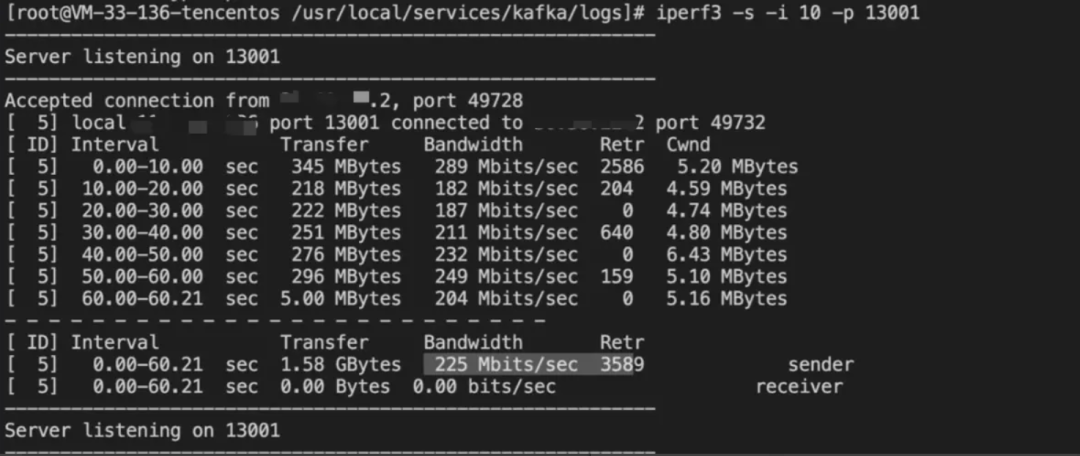
Wget 在 Connect 集群直连香港,下载速度在 20MB/s。

这两个测试说明:在同样环境下,网络传输速率并不低,可以达到 20MB/s。那既然网络带宽没问题,问题又会出在哪呢?
第二阶段分析:内核调参数
网络没有问题,那会不会是 Kafka 网络相关的应用程序参数、以及内核网络相关的参数设置的不合理呢?
1、我们首先进行了内核调参,跟网络相关的内核参数主要有:
系统默认值:
net.core.rmem_max=212992
net.core.wmem_max=212992
net.core.rmem_default=212992
net.core.wmem_default=212992
net.ipv4.tcp_rmem="4096 87380 67108864"
net.ipv4.tcp_wmem="4096 65536 67108864"
---------------------------------------------------------
调整内核参数:
sysctl -w net.core.rmem_max=51200000
sysctl -w net.core.wmem_max=51200000
sysctl -w net.core.rmem_default=2097152
sysctl -w net.core.wmem_default=2097152
sysctl -w net.ipv4.tcp_rmem="40960 873800 671088640"
sysctl -w net.ipv4.tcp_wmem="40960 655360 671088640"
调整TCP的拥塞算法为bbr:
sysctl -w net.ipv4.tcp_congestion_control=bbr
整体内核参数的值我们都调大了(尽管我们认为系统内核默认值也不小),同时我们还调整了 TCP 的拥塞算法。(参考资料:[[译] [论文] BBR:基于拥塞(而非丢包)的拥塞控制(ACM, 2017)]([译] [论文] BBR:基于拥塞(而非丢包)的拥塞控制(ACM, 2017)))因为这个延时发生在跨地域间且跨洋了,使用 BBR,可以获得显著的网络吞吐量的提升和延迟的降低。吞吐量的改善在远距离路径上尤为明显,比如跨太平洋的文件或者大数据的传输,尤其是在有轻微丢包的网络条件下。延迟的改善主要体现在最后一公里的路径上,而这一路径经常受到缓冲膨胀(Bufferbloat)的影响。所谓 “缓冲膨胀” 指的是网络设备或者系统不必要地设计了过大的缓冲区。当网络链路拥塞时,就会发生缓冲膨胀,从而导致数据包在这些超大缓冲区中长时间排队。在先进先出队列系统中,过大的缓冲区会导致更长的队列和更高的延迟,并且不会提高网络吞吐量。由于 BBR 并不会试图填满缓冲区,所以在避免缓冲区膨胀方面往往会有更好的表现。经过内核参数调整后,验证发现延时并没有很大的改善。2、在云产品技术服务专家大佬的提醒下,确认连接的 Receive Buffer 设置过小,调内核参数才没有生效,怀疑是应用层进行了设置。于是我们调整了 Kafka 应用程序网络参数 Socket.Send.Buffer、Socket.Recevie.Buffer 的参数值:(1)把源目标 CKafka 实例 Broker 的 Socket.Send.Buffer.Bytes 参数从默认 64KB 调整为使用系统的 Socket Send Buffer。Kafka 内核关于 Socket Send Buffer 的代码:在 Kafka 中,TCP 发送缓冲区的大小由应用程序和操作系统共同决定。应用程序可以通过设置 Socket.Send.Buffer.Bytes 参数来控制 TCP 发送缓冲区的大小,操作系统也可以通过设置 TCP/IP 协议栈的参数来控制 TCP 发送缓冲区的大小。应用程序设置的 Socket.Send.Buffer.Bytes 参数会影响 TCP 发送缓冲区的大小,但是操作系统也会对 TCP 发送缓冲区的大小进行限制。如果应用程序设置的 Socket.Send.Buffer.Bytes 参数超过了操作系统的限制,那么 TCP 发送缓冲区的大小就会被限制在操作系统的限制范围内。如果应用程序设置的 Socket.Send.Buffer.Bytes=-1 ,那么 TCP 发送缓冲区的大小就会默认使用操作系统的 TCP 发送缓冲区的大小。需要注意的是,TCP 发送缓冲区的大小会影响网络的吞吐量和延迟时间。如果 TCP 发送缓冲区的大小过小,会导致网络的吞吐量和性能下降;如果 TCP 发送缓冲区的大小过大,会导致网络的延迟时间增加。因此,需要根据实际情况进行调整,以达到最优的性能和可靠性。(2)把客户端 Connect Consumer 的 Receive.Buffer.Bytes 参数从默认 64KB 调整为使用系统的 Socket Receive Buffer。把客户端 Max.Partition.Fetch.Bytes 这个分区最大拉取大小调整到了 5MB。调整后,我们迅速和客户协调时间重启集群,验证这个调参。调整完后的效果明显:单连接的平均速度从 300KB/s 提升到了 2MB/s 以上:可以看到调大 Kafka 的 Socket 接收、发送参数后,效果确实很明显,同步数率上来了。当我们以为延时问题解决了的时候,问题又出现了!第三阶段分析:深挖根因
上面第二阶段的 Kafka 调参应用到客户集群,观察一天后,客户反馈集群整体延时有所好转,但是部分分区延时还是很大。我们也观测到大概一半分区的同步速率依然很低。(注:上图中的 Bytes-Consumed-Rate 指标 代表每秒消费的字节数)我们首先通过运营后台确定了消费速率低的 Partition 对应的 ConsumerGroupID,通过这个 ConsumerGroupID 抓包定位对应的慢速 TCP 连接。从上可以看到 Server 发送一段数据之后,会暂停一段时间,大约一个 RTT 再继续发送。统计每个发送间隔之间的数据包的总大小,大概 64KB。这基本能说明 TCP 的发送窗口被限制在 64KB。但是,通过抓包其他速度正常的连接发现并没有这种限制。一般来说,TCP 发送窗口的实际大小是跟 Window Scale 有关的,这个只能在连接建立的时候确认。【Tips】:TCP Window Scale, TCP 的窗口缩放因子。(参考资料:How to determine TCP initial window size and scaling option? Which factors affect the determination? - Red Hat Customer Portal)在传统的 TCP 协议中,TCP 窗口大小的最大值只能达到 64KB,这限制了 TCP 协议的传输速度和效率。为了解决这个问题,TCP Window Scale 机制被引入到 TCP 协议中。TCP 窗口大小 = (接收端窗口大小) * (2 ^ TCP Window Scale 选项的值)需要注意的是,TCP Window Scale 机制需要在 TCP 三次握手连接建立时进行协商,以确定 TCP 窗口大小的扩展方式和参数。为了抓取建连的情况,我们尝试重启单个 Partition 的消费任务,但是发现,只要一重启,消费的速度就能恢复,窗口的大小就不会出现瓶颈。为了复现问题,我们模拟构造了客户的使用场景,进行了整体的场景复现。最终确认只有在任务全量重启的时候才会出现这个问题。在任务重启过程中,我们进行了服务端的整体抓包。定位到了正常连接和异常连接,对比了建连的过程,最终确认了慢速的连接中 Window Scale 确实没有生效!从上图可以看出,慢速连接中,Server 在返回 Syn/Ack 包的时候,没有 "WS=2",说明并没有开启 Window Scale 选项,进而导致整个连接的发送窗口被限制在了 64KB,吞吐就上不去了。Client 返回最后一个 Ack 的时候,也明确显示了 "no window scaling used"。(3)为什么 Window Scale 概率性不生效?到这一步,我们就需要解释为什么 Server 端发送 Syn/Ack 的时候会概率性地不开 Window Scale 呢?这里,计算组大佬给出了一个相似的 Case 提供我们学习:kubernetes - 深度复盘 - 重启 etcd 引发的异常 - 个人文章 - SegmentFault 思否 从中可以得到一个信息:看起来是 SYN Cookie 生效的情况下,对方没有传递 Timestamp 选项过来(实际上,按照 SYN Cookie 的原理,发送给对端的回包中,会保存有编码进 Tsval 字段低 6 位的选项信息),就会调用 Tcp_Clear_Options, 清空窗口放大因子等选项。我们从系统日志里面,我们也能观察到在任务整体重启的时候确实触发了 SYN Flood。(4)为什么服务端没收到 Tsval (TCP 的 Timestamp Value) 呢?上面有介绍过我们的数据同步时经过了公司内部的一个 VPCGW,我们分别在 Client 和 Server 上分别抓包,最终确认是 VPCGW 把 Client 发出的 Tsval 吞了。同时也跟 VPCGW 的研发同学确认,在 NAT 环境下,不转发 Timestamp 是预期行为,主要为了解决特殊情况下的丢包问题,NAT 环境下 tcp_timestamps 问题_centos nat tcp_timestamps_清风徐来 918 的博客 - CSDN 博客。不过这个问题在新内核中,已经不存在,所以可以排期提供开放 Timestamp 的能力。根因定位
Connect Consumer 批量启动,触发了大量新建 TCP 连接,短时间的大量新建连接触发了 SYN Cookie 保护检查逻辑。但是因为客户端没有发送 Timestamp 选项传过来,造成了服务端把窗口放大因子清除,最终造成连接的发送窗口最大 64KB,在大延迟的场景下影响了传输性能。四、我们的解决方案
● 规避方案:我们调整了 Connect Woker 初始化的并发度,降低 TCP 初始化建连的速度,保证不会触发 SYN Cookie, 来保证后续数据同步的性能。● 最终方案:推动 VPCGW 打开 TCP Timestamp 的能力。五、总结
问题表面是跨地域数据同步请求慢的问题,但是一路深挖下来确实一个非常底层的网络问题。这个问题的发生比较罕见,因为这个问题发生的条件比较复杂,主要是跨地域存在网络延时、同时大量的 TCP 建连、加上 VPCGW 路由传输过程中吃掉了 TCP Timestamp 参数, 叠加起来导致了这个问题。
点这里 ↓↓↓ 记得 关注✔ 标星⭐ 哦