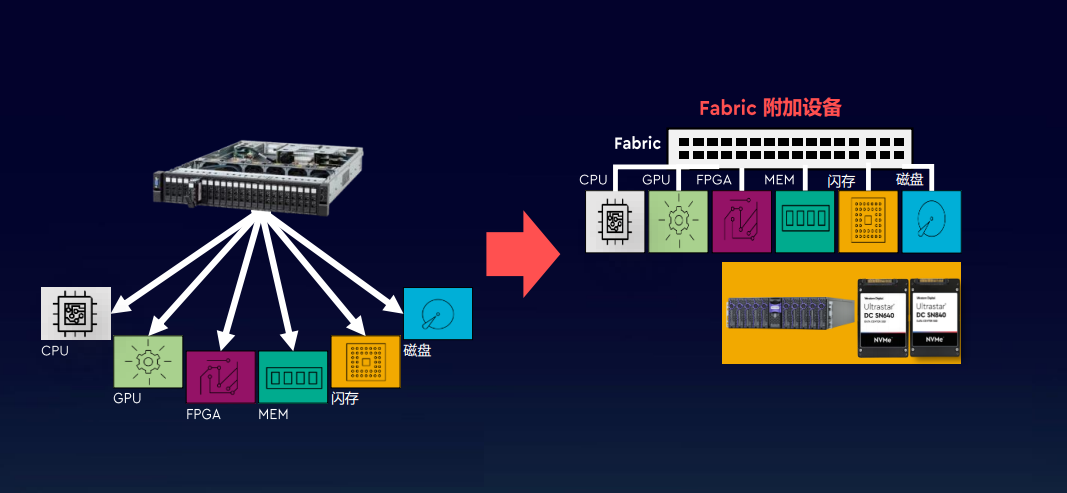
处理器、内存发展速度不均衡,“存储墙”如今成为数据计算一大障碍。随着近几年云计算和人工智能应用的发展,面对计算中心的数据洪流,数据搬运慢、搬运能耗大等问题成为了计算的关键瓶颈。在过去二十年,处理器性能速度提升远超内存性能提升,长期下来,不均衡的发展速度造成了当前的存储速度严重滞后于处理器的计算速度。本文来自“存储专题:新应用发轫,存力升级大势所趋”,覆盖存储市场分析;存储行业激荡六十载回顾;AI & 汽车电子发轫,新应用激发新动能;以及在存力升级大势所趋,新兴技术应运而生。
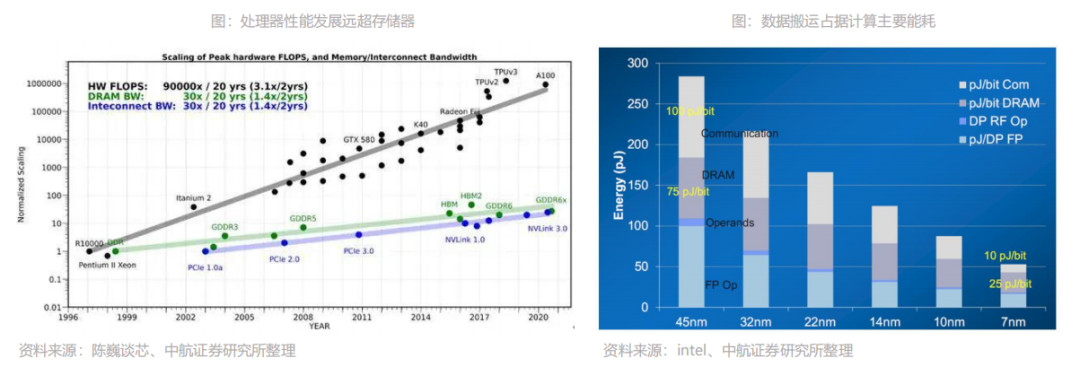
在传统计算机的设定里,存储模块是为计算服务的,因此设计上会考虑存储与计算的分离与优先级。从处理单元外的存储器提取数据,搬运时间往往是运算时间的成百上千倍,整个过程的无用能耗大概在60%-90%之间,能效非常低,“存储墙”成为了数据计算应用的一大障碍。
1、消除冯诺依曼计算架构瓶颈,存算一体应运而生
人工智能应用兴起,“存储墙”下存算一体技术应运而生。应用发展至今,人工智能的出现驱动了计算型存储/存算一体/存内计算的发展。人工智能算法的访存密集(大数据需求)和计算密集(低精度规整运算)的特征和为计算型存储/存算一体/存内计算的实现提供了有力的条件。如今,存储和计算不得不整体考虑,以最佳的配合方式为数据采集、传输和处理服务。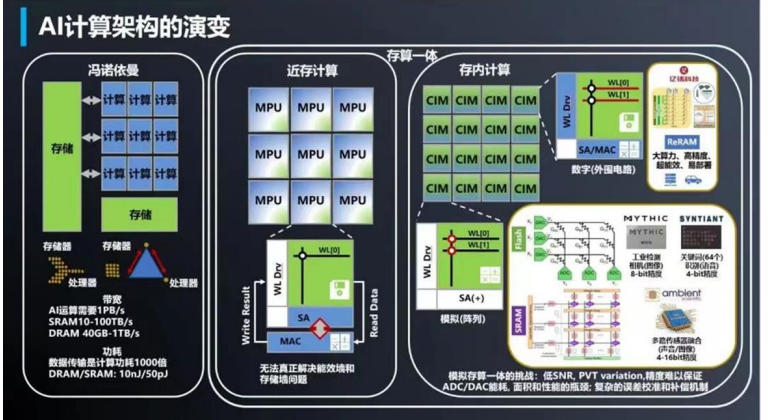
存算一体(Computing in Memory)是在存储器中嵌入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算。存算一体技术直接利用存储器进行数据处理或计算,从而把数据存储与计算融合在同一个芯片的同一片区之中,可以彻底消除冯诺依曼计算架构瓶颈。存算一体的优势是打破存储墙,消除不必要的数据搬移延迟和功耗,并使用存储单元提升算力,成百上千倍的提高计算效率,降低成本。存算一体有近内存计算(NMC)、存储级内存(SCM)、近存储计算(NSC)及存内计算(IMC)等技术方向。近内存计算(NMC):“捆绑”缓存+内存,通常会选用3D封装,利用TSV(硅通孔技术)实现垂直通信,但成本高,不同型号的芯片带还要匹配大小,进行预设计和流片。在以上工作的基础之上,还要考虑通用性问题,它适用于AI,机器学习和数据中心等规模型应用需求。另一种是2.5D封装,主流技术是HBM(高带宽内存),与平面板级连线不同,加入了interposer这种特殊有机材料(线宽,节点间距优于电路板)作为中间转接层,它像一个有底座的硅芯片,CPU周边增加很多“凹槽”,连接多个HBM(DRAM芯片)堆栈实现高密度和高带宽。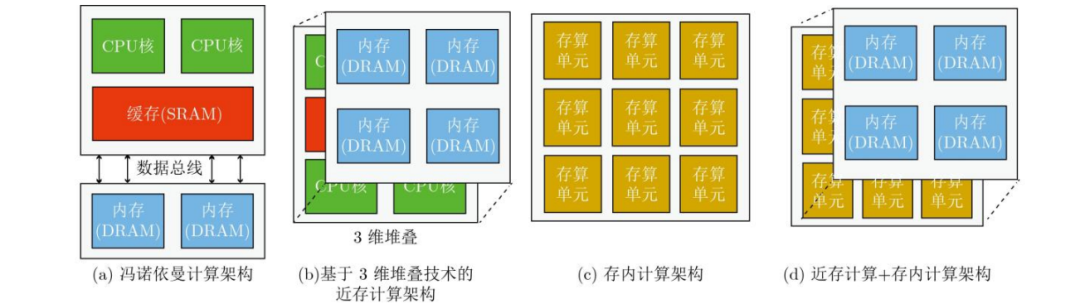
存储级内存(SCM):常见的是由英特尔和美光推出的3D Xpoint,基于相变存储技术,速度介于SSD和内存之间,目前可以和DRAM配合使用,适用于规模型应用场景。近存储计算(NSC):将SSD控制器加上计算功能,或者让拥有计算模块的FPGA来处理数据并且充当闪存控制器,不通过CPU进行读取计算,而是直连存储器和计算,以此提升计算效率。存内计算(IMC):利用存储器的单元模拟特性做计算。CPU是二进制逻辑计算,而存内计算则是利用存储器内电阻特性进行计算,不只是用来区分电阻高低,而是通过电阻值来区分多种状态,仅仅用一个晶体管就可以完成一次乘法计算过程。
2、成熟存储介质、新型存储介质齐发展
存算一体有Flash、SRAM、DRAM等成熟存储介质,同时ReRAM、MRAM等新型存储介质也在快速发展。根据存储介质的不同,存内计算芯片可分为基于传统存储器和基于新型非易失性存储器两种。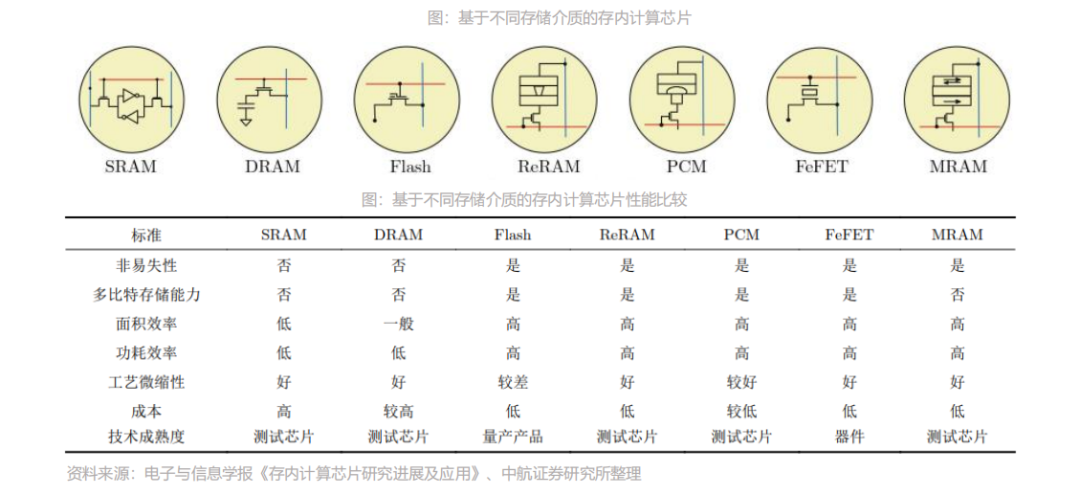
传统存储器包括SRAM,DRAM和Flash等;新型非易失性存储器包括ReRAM,PCM,FeFET,MRAM等。其中,距离产业化较近的是基于NOR Flash和基于SRAM的存内计算芯片。
3、HBM:HBM技术下,DRAM由2D转为3D
HBM(High Bandwidth Memory)即高带宽存储器,按照JEDEC的分类,HBM属于GDDR内存的一种,其通过使用先进的封装方法(如TSV硅通孔技术)垂直堆叠多个DRAM,并与GPU封装在一起。业界希望通过增加存储器带宽解决大数据时代下的“内存墙”问题,HBM便应运而生。存储器带宽是指单位时间内可以传输的数据量,要想增加带宽,最简单的方法是增加数据传输线路的数量。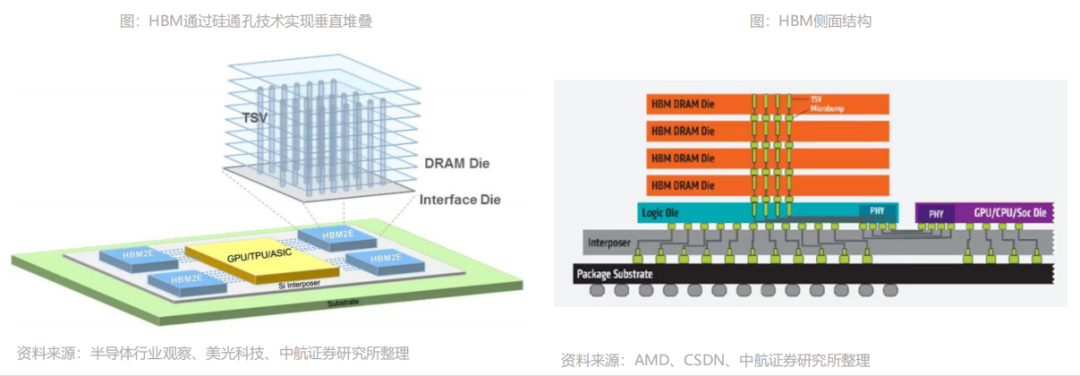
据悉,典型的DRAM芯片中,每个芯片有八个DQ数据输入/输出引脚,组成DIMM模组单元之后,共有64个DQ引脚。而HBM通过系统级封装(SIP)和硅通孔(TSV)技术,拥有多达1024个数据引脚,可显著提升数据传输速度。HBM技术之下,DRAM芯片从2D转变为3D,可以在很小的物理空间里实现高容量、高带宽、低延时与低功耗,因而HBM被业界视为新一代内存解决方案。
4、HBM:较传统GDDR带宽、功耗等性能优势明显
更高速、更高带宽:最新的HBM3的带宽最高可以达到819 GB/s,而最新的GDDR6的带宽最高只有96GB/s,CPU和硬件处理单元的常用外挂存储设备DDR4的带宽更是只有HBM的1/10。更高位宽:采用3D堆叠技术之后,其下方互联的触点数量远远多于DDR内存连接到CPU的线路数量。从传输位宽的角度来看,4层DRAM裸片高度的HBM内存总共就是1024 bit位宽。很多GPU、CPU周围都有4片这样的HBM内存,则总共位宽就是4096bit。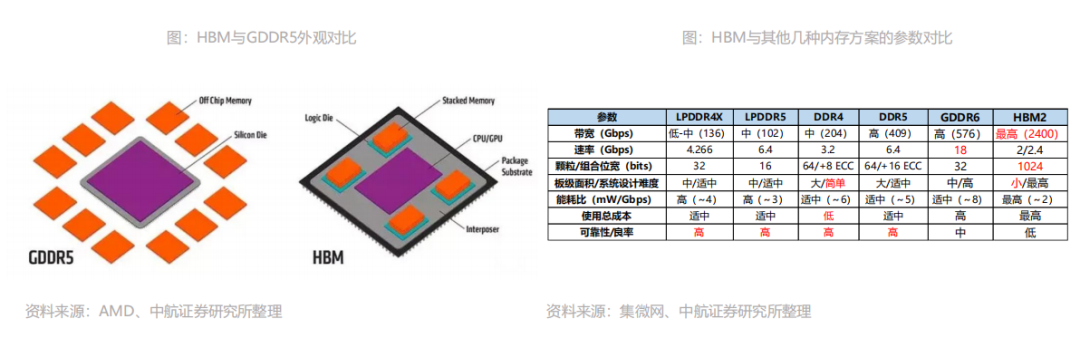
更低功耗:HBM 重新调整内存的功耗效率,使每瓦带宽比GDDR5高出3倍多,即功耗降低3倍多。更小外形:GDDR作为独立封装,在PCB上围绕在处理器的周围,而HBM则排布在硅中阶层(Silicon Interposer)上并和GPU封装在一起,面积一下子缩小了很多,比如HBM2比GDDR5节省了94%的表面积。HBM发展至今第四代性能不断突破。自2014年首款硅通孔HBM产品问世至今,HBM技术已经发展至第四代,分别是:HBM(第一代)、HBM2(第二代)、HBM2E(第三代)、HBM3(第四代),HBM芯片容量从1GB升级至24GB,带宽从128GB/s提升至819GB/s,数据传输速率也从1Gbps提高至6.4Gbps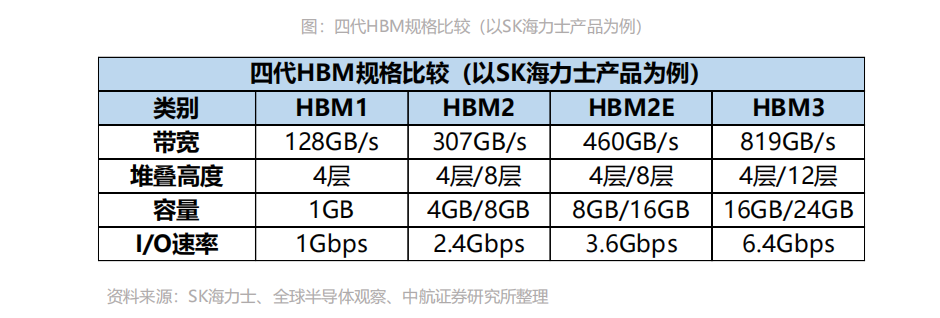
AIGC浪潮下AI服务器采购量增长,催生HBM需求量今年增近六成。2023年爆款AIGC应用带动AI服务器成长热潮,大型云端企业纷纷积极布局,包含Microsoft、Google、AWS、字节跳动、百度等企业陆续采购高端AI服务器,以持续训练及优化其AI分析模型。TrendForce预估今年AI服务器出货量年增率可望达15.4%,2023~2027年AI服务器出货量年复合成长率约12.2%。高端AI服务器需采用的高端AI芯片,相较于一般服务器而言,AI服务器多增加GPGPU的使用,以NVIDIA A100 80GB配置4或8张计算,HBM用量约为320~640GB。未来在AI模型逐渐复杂化的趋势下,将推升2023-2024年高带宽存储器(HBM)的需求。TrendForce预估2023年全球HBM需求量将年增近六成,来到2.9亿GB,2024年将再成长三成。根据Mordor Intelligence,2020年高带宽内存市场价值为 10.682 亿美元,预计到2026年将达到40.885亿美元,在2021-2026年预测期间的复合年增长率为25.4%。在近期的业绩会上,SK海力士表示目前其HBM的销量占比还不足营收1%,但今年销售额占比有望成长到10%,同时预计在明年应用于AI服务器的HBM和DDR5的销量将翻一番。HBM价值量显著敢于标准DRAM,成为新利润增长点。芯片咨询公司 SemiAnalysis 表示,HBM的价格大约是标准DRAM芯片的五倍,为制造商带来了更大的总利润。目前,HBM占全球内存收入的比例不到5%,但SemiAnalysis预计到2026年将占到总收入的20%以上。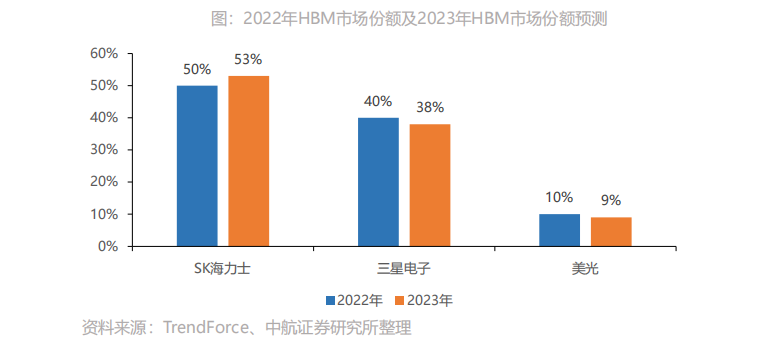
SK海力士首席财务官Kim Woo-hyun 在4月份的财报电话会议上表示预计2023年HBM收入将同比增长50%以上。
5、CXL:PCIe应对海量数据面临瓶颈
PCI-Express简称PCIE,是一种高速串行计算机扩展总线标准,主要用于扩充计算机系统总线数据吞吐量以及提高设备通信速度。PCIE本质上是一种全双工的的连接总线,传输数据量的大小由通道数lane决定的。一般,1个连接通道lane称为X1,每个通道lane由两对数据线组成,一对发送,一对接收,每对数据线包含两根差分线。即X1只有1个lane,4根数据线,每个时钟每个方向1bit数据传输,依次类推。CPU通过主板上的PCIe插槽及PCIe协议与加速器沟通,实现上下之间的接口以协调数据的传送,并在高时钟频率下保持高性能。即使每代PCIe性能升级,但面对海量数据仍有压力。每一代PCIe的吞吐量都翻番,2019年5月底公布的PCIe 5.0,其以32Gb/s的单通道带宽与32GT/s每通道数据传输速率,满足了现今绝大多数的需求。但应对数据TB级增长、异构计算大行其道的当下,PCIe在内存使用效率、延迟和数据吞吐量等方面,已经面临压力。
6、CXL:PCIe技术乏力,CXL旨在解决内存墙和IO墙问题
PCIe技术逐渐乏力,CXL旨在解决存储墙和IO墙问题。现代处理器性能的不断提升,而内存与算力之间的技术发展差距却不断增大。在过去的20多年中,处理器的性能以每年大约55%速度快速提升,而内存性能的提升速度则只有每年10%左右。面临摩尔定律的压力,当代内存容量扩展速度逐年减缓,成本却愈发高昂。随着大数据AI、机器学习等应用爆发,英特尔二十年前开创的PCIe(PCI Express)技术逐渐乏力,内存墙和IO墙成为两个不可逾越的瓶颈,基于PCI-e协议的CXL技术便在此环境下出现。存储墙:现代计算系统通常采取高速缓存(SRAM)、主存(DRAM)、外部存储(NAND Flash)的三级存储结构。每当应用开始工作时,就需要不断地在内存中来回传输信息。SRAM响应时间通常在纳秒级,DRAM则一般为100纳秒量级,NAND Flash更是高达100微秒级,当数据在这三级存储间传输时,后级的响应时间及传输带宽都将拖累整体的性能,形成“存储墙”。IO墙:以AI为例,AI模型的大小基本上每两年上升一个数量级,内存中的数据可以较快访问,但超出内存后数据就需要放在外部存储里,用网络IO来访问数据。IO方式的访问会使得访问速度严重下降,当数据量过于庞大内存容量不够时,IO也不可避免地会成为应用的瓶颈。
7、CXL:具有极高兼容性和内存一致性的全新互联技术标准
CXL作为一种全新的互联技术标准,具有极高兼容性和内存一致性。CXL全称为Compute Express Link,2019年英特尔推出了CXL技术,其能够让CPU与GPU、FPGA或其他加速器之间实现高速高效的互联,从而满足高性能异构计算的要求,并且其维护CPU内存空间和连接设备内存之间的一致性。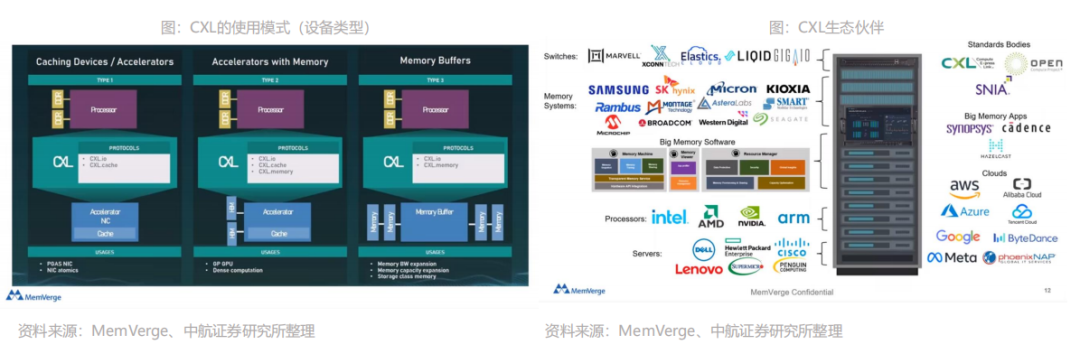
CXL硬件加软件的生态环境里,已经涌现了一大批公司。CXL联盟于2019年3月由创始成员阿里巴巴集团、思科系统、戴尔易安信、Meta、谷歌、惠普企业(HPE)、华为、英特尔公司和微软组成。此后,AMD、NVIDIA、三星、Arm、瑞萨、IBM、Keysight、Synopsys、Marvell等以各种身份加入。2021、2022年Gen-Z技术和OpenCAPI技术相继加入,CXL联盟一统I/O互连标准。
8、CXL:1.1/2.0/3.0三代标准,从单机到多层交互
CXL是基于 PCIe 5.0发展而来,过去四年时间CXL已经发表了1.0/1.1、2.0、3.0三个不同的版本。CXL 1.1:2019年,CXL的第一个版本CXL 1.1问世了。它主要定义的标准是如何直接连接一台服务器里计算器件和内存器件,它主要的场景是对内存的容量和带宽进行扩展,即Memory Expansion。CXL 2.0:下图中H1到H4到Hn指不同Host,它可以通过CXL Switch连接多个设备, D1到D4到Dn指的是不同的内存,也是通CXLSwitch连到上层的主机里。CXL 2.0不仅解决单机设备的问题,更是使Memory Pooling成为可能。这套框架下,可以跨系统设备实现共享内存池,大大提高内存的使用率,增加灵活性,同时降低内存的使用成本。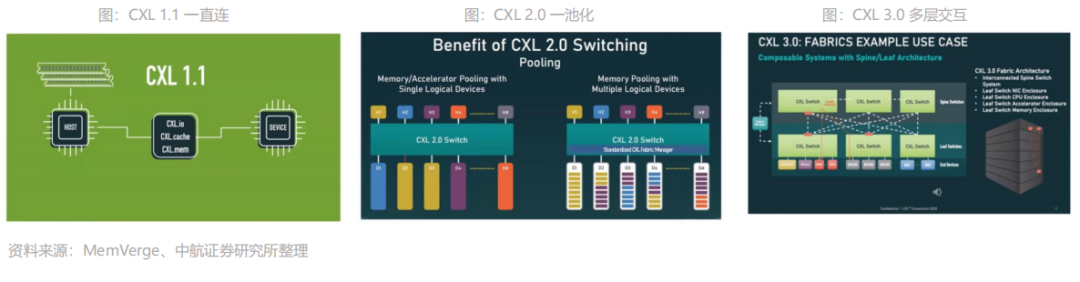
CXL 3.0:2022年8月份发布的新标准,在CXL 2.0基础上增加了一些重要功能,它可以使得多个Switch互相连接,可以使得上百个服务器互联并共享内存。除了多层交互以外,CXL 3.0还多Memory sharing的能力,突破了某一个物理内存只能属于某一台服务器的限制,在硬件上实现了多机共同访问同样内存地址的能力。技术路线图明确,至少2023年H2才有CXL 1.0/1.1的产品落地。已经有不少公司宣布将支持CXL,包括AMD、英特尔的下一代服务器芯片,内存厂商三星、海力士、美光均宣布了支持CXL的内存产品,但真正的产品仍需至少2023年H2才能推出。2024年上半年,CXL1.1和CXL 2.0的产品可能会有落地产品,CXL 3.0的落地还需要更长时间。本文来自“存储专题:新应用发轫,存力升级大势所趋”,覆盖存储市场分析;存储行业激荡六十载回顾;AI & 汽车电子发轫,新应用激发新动能;以及在存力升级大势所趋,新兴技术应运而生。
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。推荐阅读
2、随着电子书数量增加及内容更新,价格会随之增加,所以现在下单最划算,购买后续可享全店内容更新“免费”赠阅。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。