【新智元导读】人民大学最新研究,首次从「对比学习」的角度来理解上下文学习,或可提供自注意力机制的改进思路。
近些年来,基于Transformer的大语言模型表现出了惊人的In-context Learning (ICL)能力,我们只需要在查询问题前以 {问题,标签} 的形式增加少数示例,模型就可以学到该任务并输出较好的结果。然而,ICL背后的机理仍是一个开放的问题:在ICL的推理过程,模型的参数并没有得到显式的更新,模型如何根据示例样本输出相应的结果呢?近日,来自中国人民大学的学者提出了从对比学习的视角看待基于Transformer的ICL推理过程,文章指出基于注意力机制的ICL推理过程可以等价于一种对比学习的模式,为理解ICL提供了一种全新视角。
论文地址:https://arxiv.org/abs/2310.13220研究人员先利用核方法在常用的softmax注意力下建立了梯度下降和自注意机制之间的关系,而非线性注意力;
然后在无负样本对比学习的角度上,对ICL中的梯度下降过程进行分析,并讨论了可能的改进方式,即对自注意力层做进一步修改;
最后通过设计实验来支持文中提出的观点。
研究团队表示,这项工作是首次从对比学习的角度来理解ICL,可以通过参考对比学习的相关工作来促进模型的未来设计思路。
相较于有监督学习下的微调,大模型在ICL推理过程中并不需要显式的梯度更新,即可学习到示例样本中的信息并输出对于查询问题的答案,基于Transformer的大模型是如何实现这一点的呢?
一个自然且直观的想法是,模型虽然没有在学习上下文过程存在显式更新,但可能存在相应的隐式更新机理。在此背景下,许多工作开始从梯度下降的角度来思考大模型的ICL能力。然而,现有的工作或是基于Transformer线性注意力的假设,或是基于对模型参数特定的构造进行分析,实际应用中的模型并不一定符合上述的假设。(1)不依赖于权重参数构造方法以及线性注意力的假设,如何在更为广泛使用的softmax注意力设定下,对ICL的隐式更新机理进行分析?(2)这种隐式更新的具体过程,如损失函数以及训练数据,会具有什么样的形式?作者首先假设模型输入的token由若干示例样本的token以及最后的查询token组成,每个token由 {问题, 标签} 的embedding拼接而成,其中,查询token的标签部分设置为0,即
在注意力机制下,模型输出最后一个token并readout得到预测的标签结果
进一步,作者应用核方法,将注意力矩阵的每一项看作映射函数的内积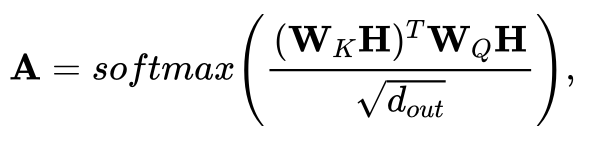
在此基础上,作者建立了基于Transformer注意力机制的推理过程与在参考模型上进行梯度下降之间的对应关系。在参考模型的梯度下降过程中,示例样本与查询的token分别提供了训练集以及测试输入的相关信息,模型在类似余弦相似度的损失函数下进行训练,参考模型最后输出测试输入所对应的输出。作者指出参考模型的该输出会与注意力机制下的推理输出严格等价,即参考模型在对应数据集以及余弦相似损失上进行一步随机梯度下降后,得到的测试输出会与注意力机制下得到的输出是严格相等的。
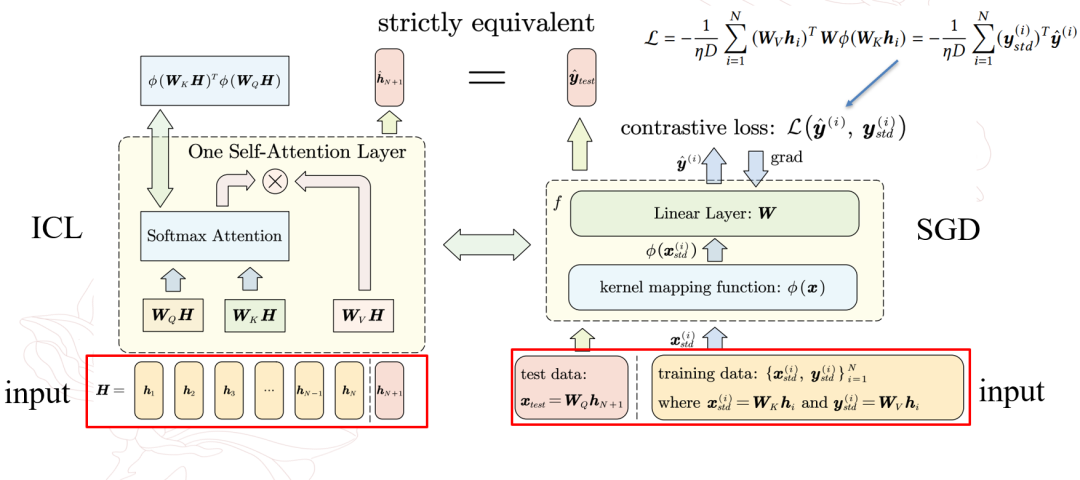
进一步,作者发现这一对应的梯度下降过程类似于无负样本的对比学习模式,其中,注意力机制中的K,V映射可以看作为一种「数据增强」。而参考模型则是相当于需要学习潜在表征的encoder,其将映射后的K向量先投影到高维空间学习深层表征,然后再映射回原来的空间与V向量进行对比损失的计算,以使得两者的尽可能的相似。
基于此,作者从对比学习的角度对注意力机制作出改进,作者分别从正则化的损失函数、数据增强以及增加负样本三个方面来进行考虑。正则化的损失函数
作者指出在对比损失中增加正则,相当于在原有注意力机制上添加特殊的支路。数据增强
作者认为原有的线性映射作为数据增强或不利于学习潜在表征,对于特定数据类型所设计的数据增强方式或许更为有效,相应地,作者给出了对模型进行修改的框架。增加负样本
此外,作者还从增加负样本的角度,给出了ICL对比学习模式以及相应注意力机制的改进。实验部分中,作者在线性回归任务上设计了仿真实验,说明了注意力机制下的推理过程与参考模型上进行梯度下降过程的等价性,即单层注意力机制下得到的推理结果,严格等价于参考模型在对比损失loss上进行一步梯度下降后的测试输出。
在实验中,作者还选取了正随机特征作为映射函数,来作为对注意力机制的近似,并考察了不同随机特征维度对注意力矩阵以及输出近似效果的影响,说明了该映射函数的有效性。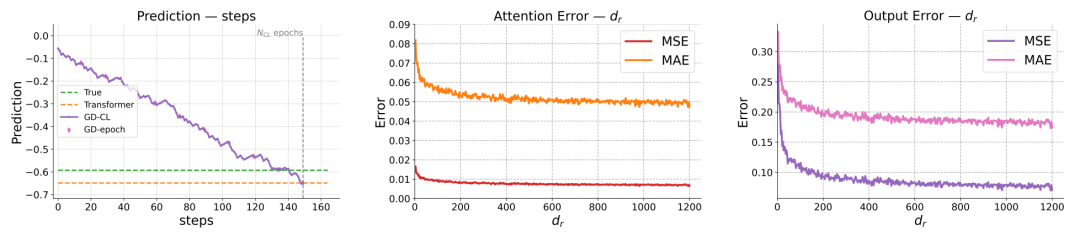
作者还展示了近似得到的注意力矩阵以及输出与实际结果的对比,说明了二者在模式上的基本一致。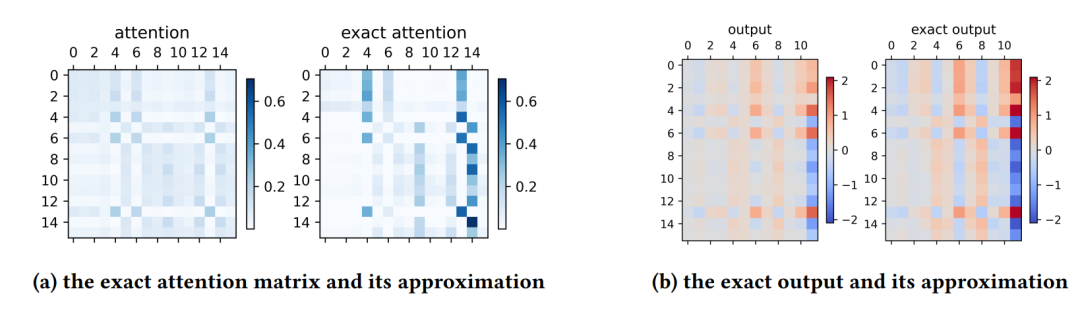
实验图2
最后,作者进一步探究了根据对比学习视角对注意力机制改进后的表现效果,发现选择合适的改进方式不仅可以加速模型训练的收敛速度,还可以最终取得更好的效果,这说明了未来从对比学习视角进行模型结构设计与改进的潜力。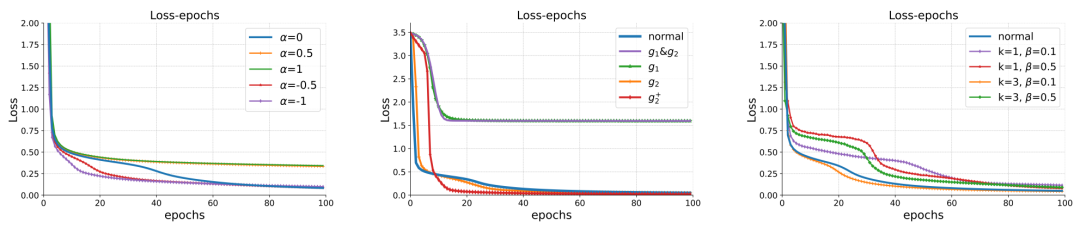
实验图3
作者在不依赖于线性注意力假设以及权重构造的方法下,探究了ICL的隐式更新机理,建立了softmax注意力机制推理过程与梯度下降的等价关系,并进一步提出了从对比学习的视角下看待注意力机制推理过程的新框架。
但是,作者也指出了该工作目前仍存在一定的缺陷:文章目前只考虑了softmax自注意力机制下的前向推理,层归一化,FFN模块以及decoder等Transforomer其余结构对推理过程的影响仍有待进一步的研究;从对比学习视角出发对模型结构进行进一步的改进,在诸多实际应用任务上的表现仍有待进一步探索。https://arxiv.org/abs/2310.13220