随着大语言模型的快速发展,其长度外推能力(length extrapolating)正日益受到研究者的关注。尽管这在 Transformer 诞生之初,被视为天然具备的能力,但随着相关研究的深入,现实远非如此。传统的 Transformer 架构在训练长度之外无一例外表现出糟糕的推理性能。研究人员逐渐意识到这一缺陷可能与位置编码(position encoding)有关,由此展开了绝对位置编码到相对位置编码的过渡,并产生了一系列相关的优化工作,其中较为代表性的,例如:旋转位置编码(RoPE)(Su et al., 2021)、Alibi (Press et al., 2021)、Xpos (Sun et al., 2022) 等,以及近期 meta 研发的位置插值(PI)(Chen et al., 2023),reddit 网友给出的 NTK-aware Scaled RoPE (bloc97, 2023),都在试图让模型真正具备理想中的外推能力。然而,当研究人员全力将目光放在位置编码这一众矢之的上时,却忽视了 Transformer 中另一个重量级角色 --self-attention 本身。蚂蚁人工智能团队最新研究表明,这一被忽视的角色,极有可能成为扭转局势的关键。Transformer 糟糕的外推性能,除了位置编码外,self-attention 本身仍有诸多未解之谜。基于此发现,蚂蚁人工智能团队自研了新一代注意力机制,在实现长度外推的同时,模型在具体任务上的表现同样出色。
论文地址:https://arxiv.org/abs/2309.08646
Github仓库:https://github.com/codefuse-ai/Collinear-Constrained-Attention
ModelScope:https://modelscope.cn/models/codefuse-ai/Collinear-Constrained-Attention/summary
HuggingFace:敬请期待
长度外推 (Length Extrapolating)长度外推是指大语言模型在处理比其训练数据中更长的文本时的能力。在训练大型语言模型时,通常有一个最大的序列长度,超过这个长度的文本需要被截断或分割。但在实际应用中,用户可能会给模型提供比训练时更长的文本作为输入,如果模型欠缺长度外推能力或者外推能力不佳,这将导致模型产生无法预期的输出,进而影响模型实际应用效果。(Vaswani et al., 2017) 于 2017 年提出的 multi-head self-attention,作为如今大语言模型的内核,对于推动人工智能领域的发展起到了举足轻重的作用。这里以下图 1 给出形象化的描述,这项工作本身已经被广泛认可,这里不再进行赘述。初次接触大语言模型,对这项工作不甚了解的读者可以前往原论文获取更多细节 (Vaswani et al., 2017)。
图1. 多头注意力机制示意图,引自(Vaswani, et al., 2017)。
由于 self-attention 机制本身并不直接处理序列中的位置信息,因此引入位置编码成为必要。由于传统的 Transformer 中的位置编码方式由于其外推能力不佳,如今已经很少使用,本文不再深入探讨传统的 Transformer 中的编码方法,对于需要了解更多相关知识的读者,可以前往原论文查阅详情 (Vaswani et al., 2017)。在这里,我们将重点介绍目前非常流行的旋转位置编码(RoPE)(Su et al., 2021),值得一提的是,Meta 的 LLaMa 系列模型 (Touvron et al., 2023a) 均采用了此种编码方式。RoPE 从建模美学的角度来说,是一种十分优雅的结构,通过将位置信息融入 query 和 key 的旋转之中,来实现相对位置的表达。
图2. 旋转位置编码结构,引自(Su et al., 2021)。
位置插值 (Position Interpolation)尽管 RoPE 相比绝对位置编码的外推性能要优秀不少,但仍然无法达到日新月异的应用需求。为此研究人员相继提出了各种改进措施,以 PI (Chen et al., 2023) 和 NTK-aware Scaled RoPE (bloc97, 2023) 为典型代表。但要想取得理想效果,位置插值仍然离不开微调,实验表明,即使是宣称无需微调便可外推的 NTK-aware Scaled RoPE,在传统 attention 架构下,至多只能达到 4~8 倍的外推长度,且很难保障良好的语言建模性能和长程依赖能力。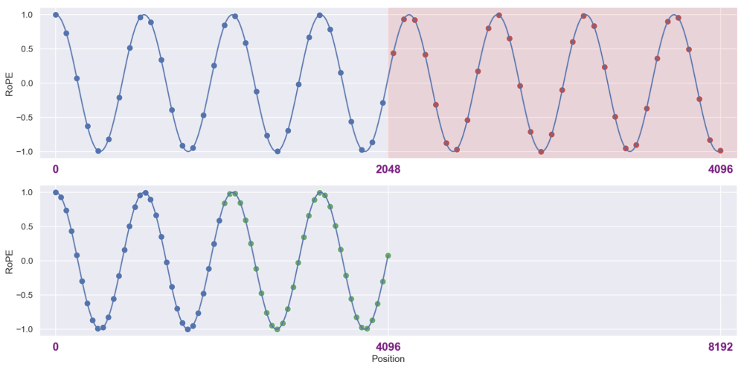
图3. 位置插值示意图,引自(Chen et al., 2023)。
过去的研究主要集中在位置编码上,所有相关研究工作均默认 self-attention 机制已经被完美实现。然而,蚂蚁人工智能团队近期发现了一个久被忽视的关键:要从根本上解决 Transformer 模型的外推性能问题,self-attention 机制同样需要重新考量。
图4. CoCA 模型架构,引自(Zhu et al., 2023)。
RoPE 与 self-attention 的异常行为在 Transformer 模型中,self-attention 的核心思想是计算 query(q)和 key(k)之间的关系。注意力机制使用这些关系来决定模型应该 “关注” 输入序列中的哪些部分。考虑输入 和
和 ,分别代表输入序列中的m个和第n个位置索引对应的 token,其 query 和 key 分别为
,分别代表输入序列中的m个和第n个位置索引对应的 token,其 query 和 key 分别为 和
和 。它们之间的注意力可以表示为一个函数
。它们之间的注意力可以表示为一个函数 ,如果应用 RoPE,则可以进一步简化为仅依赖于m和n相对位置的函数
,如果应用 RoPE,则可以进一步简化为仅依赖于m和n相对位置的函数 。
。
从数学角度看,可以解释为 组复数(
组复数( ,其中d为 hidden dimension 维度,省略位置索引m,n)经过旋转后的内积之和。这在直觉上是有意义的,因为位置距离可以建模为一种序,并且两个复数的内积随着旋转角度
,其中d为 hidden dimension 维度,省略位置索引m,n)经过旋转后的内积之和。这在直觉上是有意义的,因为位置距离可以建模为一种序,并且两个复数的内积随着旋转角度  的变化而变化,以图 5 为例,其中
的变化而变化,以图 5 为例,其中 ,
, 为
为 和
和 的初始夹角。
的初始夹角。
为了便于理解,我们首先考虑双向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如图 5 所示,对于 组复数中的任意一组
组复数中的任意一组 ,
, ,它们分别具有位置索引m和n。不失一般性,我们假设复平面上有一个小于
,它们分别具有位置索引m和n。不失一般性,我们假设复平面上有一个小于 的角度
的角度 逆时针从
逆时针从 旋转到
旋转到 ,那么它们的位置关系有两种可能的情况(不考虑 =,因为它是平凡的)。
,那么它们的位置关系有两种可能的情况(不考虑 =,因为它是平凡的)。
- 正常保序关系:当
 时,如图 5 右侧所示。注意力分数随着位置距离的增加而降低(直到它们相对角度超出,超出的这部分在原论文附录中进行了讨论 (Zhu et al., 2023))。
时,如图 5 右侧所示。注意力分数随着位置距离的增加而降低(直到它们相对角度超出,超出的这部分在原论文附录中进行了讨论 (Zhu et al., 2023))。 - 异常行为:然而,当
 时,如图 5 左侧所示,异常行为打乱了
时,如图 5 左侧所示,异常行为打乱了 个最邻近的 token 的序。当
个最邻近的 token 的序。当 时,
时, 和
和 之间的相对角度将随着
之间的相对角度将随着 的增大而减小,这意味着最接近的 token 可能会获得较小的注意力分数。(我们在这里使用 “可能”,因为注意力分数是
的增大而减小,这意味着最接近的 token 可能会获得较小的注意力分数。(我们在这里使用 “可能”,因为注意力分数是 个内积的总和,也许其中一个是微不足道的。但是,后续实验证实了这一重要性。)并且,无论应用 PI 还是 NTK-aware Scaled RoPE,均无法消除这一影响。
个内积的总和,也许其中一个是微不足道的。但是,后续实验证实了这一重要性。)并且,无论应用 PI 还是 NTK-aware Scaled RoPE,均无法消除这一影响。

图5.双向模型中的序被破坏,引自(Zhu et al., 2023)。
对于因果模型来说,虽然m总是大于n,但问题同样存在。如图 6 所示,对于某些j,当存在小于 的角度
的角度 从
从 逆时针旋转到
逆时针旋转到 时,而不是从到
时,而不是从到 。
。

图6.因果模型中的序被破坏,引自(Zhu et al., 2023)。基于以上 RoPE 与 self-attention 的异常行为分析,要从根本上解决这个问题,仅从位置编码入手很显然是药不对症,根本的解决方法是让 self-attention 中的 query 和 key 初始夹角为 0,这是论文中共线约束(Collinear Constrained Attention)的由来。详细的推导和公式,这里不进行一一展开,读者可以阅读原文进行深入理解。- 稳定的远程衰减特性:CoCA 相对于 RoPE 显示出了更为稳定的远程衰减特性。
- 显存瓶颈与解决方案:CoCA 有引入显存瓶颈的风险,但论文给出了十分高效的解决方案,使得 CoCA 的计算和空间复杂度几乎与最初版本的 self-attention 无异,这是十分重要的特性,使得 CoCA 的实用性十分优异。
- 无缝集成:CoCA 可以与当前已知的插值手段(论文中实验了 NTK-aware Scaled RoPE)无缝集成,且在无需微调的情况下取得了远超原始 attention 结构的性能,这意味着使用 CoCA 训练的模型,天然就拥有近乎无限的外推能力,这是大语言模型梦寐以求的特性。
论文比较了 CoCA 与 RoPE (Su et al., 2021)、 ALibi (Press et al., 2021) 在外推性能上的差异,取得了令人振奋的结果。相应模型记为:- Origin:原始 attention 结构,位置编码方式为 RoPE
- ALibi:原始 attention 结构,位置编码方式为 ALibi
论文评估了 CoCA 和 Origin、ALibi 模型的长文本语言建模能力。该评估使用了 100 个文档,每个文档至少拥有 8,192 个 token,这些文档随机采样于 PG-19 数据集 (Rae et al., 2019)。所有 3 个模型的训练长度均为 512,模型大小为 350M。图 7 说明了一个值得注意的趋势:当推理长度超出其训练长度,Origin 模型的困惑度迅速偏离(>1000)。相比之下,CoCA 模型能够维持低困惑度,即使是在其训练长度的 16 倍时,困惑度没有出现发散趋势。NTK-aware Scaled RoPE (bloc97, 2023) 作为一种无需微调的外推方法,论文中允许在实验中应用该方法,但即使在 Origin 模型上应用了动态 NTK 方法,其困惑度仍然远高于 CoCA。ALibi 在困惑度上的表现最好,而 CoCA 在应用动态 NTK 方法后,可以取得与 ALibi 相近的结果。
图7.滑动窗口困惑度测试结果,引自(Zhu et al., 2023)。困惑度是衡量语言模型预测下一个 token 的熟练程度的指标。然而,它并不能完全代表一个理想的模型。因为虽然局部注意力在困惑度上表现出色,但它在捕获长程依赖性方面往往表现不佳。为了深入评估这一问题,论文采用 (Mohtashami & Jaggi, 2023) 提出的密钥检索综合评估任务评估了 CoCA 和 Origin、ALibi 模型。在此任务中,有一个隐藏在长文档中的随机密钥需要被识别和检索。如图 8 所示,像 ALibi 这一类具有一定局部假设的模型,尽管在困惑度任务上表现良好,但在捕捉长程依赖时具备无法弥补的劣势,在外推 1 倍长度时,准确率就开始迅速下降,最终下跌至 10% 以下。相比之下,即使测试序列长度扩展到原始训练长度的 16 倍,CoCA 也始终表现出很高的准确性,在 16 倍外推长度时仍然超过 60%。比 Origin 模型整体高出 20%,而比 ALibi 整体高出 50% 以上。
图8.随机密钥识别检索性能曲线,引自(Zhu et al., 2023)。由于在实验中应用了动态 NTK 方法,论文针对 Origin 和 CoCA 模型在动态 NTK 方法下的 scaling factor 超参数稳定性进行了深入探讨。如图 9 所示,Origin 模型在不同 scaling factor 下存在剧烈波动(200~800),而 CoCA 模型则处于相对稳定的区间(60~70)。更进一步,从 Table 4 中的明细数据可以看出,CoCA 模型最差的困惑度表现仍然比 Origin 模型最好的困惑度表现要好 50% 以上。在 Passkey 实验中,Origin 和 CoCA 模型表现出了与困惑度实验中类似的特性,CoCA 模型在不同的 scaling factor 均有较高的准确率,而 Origin 模型在 scaling factor=8 时,准确率下跌至了 20% 以下。更进一步,从 Table 5 的明细数据可以看出,Origin 模型即使在表现最好的 scaling factor=2 时,仍然与 CoCA 模型有 5%~10% 的准确率差距。同时,Origin 模型在 scaling factor=2 时困惑度表现却是糟糕的,这从侧面反映了原始的 attention 结构在长度外推时很难同时保证困惑度和捕捉长程依赖两方面的性能,而 CoCA 做到了这一点。
图9. Origin model 和 CoCA 在不同 scaling factor 的困惑度,引自(Zhu et al., 2023)
图10. Origin 模型和 CoCA 在不同 scaling factor 的通行密钥准确性,引自(Zhu et al., 2023)
如同 PI (Chen et al., 2023) 论文所探究的一样,大语言模型在长度外推中的失败与注意力得分的异常值(通常是非常大的值)直接相关。论文进一步探讨了这一现象,这一现象也从侧面说明了为什么 CoCA 模型在长度外推中的表现要优于传统 attention 结构。实验使用了 PG-19 数据集 (Rae et al., 2019) 中的一个随机片段,长度为 1951 个 token,大约是模型训练长度的 4 倍。如图 11 所示,其中 (a1) 是 Origin 和 CoCA 模型在不使用动态 NTK 方法时的各层注意力得分,(b1) 是使用动态 NTK 方法后的得分,low layers 表示模型的第 6、12、18 层,last layer 表示第 24 层,(a2) 是 (a1) 在最后 500 个 token 的放大版本,(b2) 同理。- 从 (a1) 和 (b1) 可以发现,Origin 模型的注意力得分存在少量异常值,数值比 CoCA 模型注意力得分大 10~20 倍。
- 由于这些异常值影响了观察效果,(a2) 局部放大了最后 500 个 token,可以看到 Origin 模型的 last layer 注意力得分几乎为 0,这说明 Origin 模型在长度外推时,发生了关注邻近 token 的失效。
- 从 (b2) 可以看出,当应用动态 NTK 方法后,Origin 模型在邻近 token 处的注意力得分变得异常大,这一异常现象与前文论证的 RoPE 与 self-attention 的异常行为息息相关,Origin 模型在邻近 token 处可能存在着严重的过拟合。
图11. 外推中的注意力得分,引自(Zhu et al., 2023)在论文之外,我们使用相同的数据(120B token),相同的模型规模(1.3B),相同训练配置,基于 CoCA 和 Origin 模型进一步评测了 human eval 上的表现,与 Origin 模型对比如下:- 跟 Origin 模型比起来,两者水平相当,CoCA 并没有因为外推能力而导致模型表达能力产生损失。
- Origin 模型在 python、java 的表现比其他语言好很多,在 go 上表现较差,CoCA 的表现相对平衡,这与训练语料中 go 的语料较少有关,说明 CoCA 可能有潜在的小样本学习能力。
| python | java | cpp | js | go | AVG |
CoCA | 6.71% | 6.1% | 3.66% | 4.27% | 6.1% | 5.37% |
Origin | 7.32% | 5.49% | 5.49% | 5.49% | 1.83% | 5.12% |
在这项工作中,蚂蚁人工智能团队发现了 RoPE 和注意力矩阵之间的某种异常行为,该异常导致注意力机制与位置编码的相互作用产生紊乱,特别是在包含关键信息的最近位置的 token。为了从根本上解决这个问题,论文引入了一种新的自注意力框架,称为共线约束注意力(CoCA)。论文提供的数学证据展示了该方法的优越特性,例如更强的远程衰减形式,以及实际应用的计算和空间效率。实验结果证实,CoCA 在长文本语言建模和长程依赖捕获方面都具有出色的性能。此外,CoCA 能够与现有的外推、插值技术以及其他为传统 Transformer 模型设计的优化方法无缝集成。这种适应性表明 CoCA 有潜力演变成 Transformer 模型的增强版本。Shiyi Zhu, Jing Ye, Wei Jiang, Qi Zhang, Yifan Wu, and Jianguo Li. Cure the headache of transformers via collinear constrained attention, 2023.Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. ArXiv, abs/2104.09864, 2021. URL https://api.semanticscholar.org/CorpusID:233307138.Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. ArXiv, abs/2108.12409, 2021. URL https://api.semanticscholar.org/CorpusID:237347130.Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and FuruWei. A length-extrapolatable transformer. ArXiv, abs/2212.10554, 2022. URL https://api.semanticscholar.org/CorpusID:254877252.Shouyuan Chen, ShermanWong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. ArXiv, abs/2306.15595, 2023. URL https://api.semanticscholar.org/CorpusID:259262376.bloc97. Ntk-aware scaled rope allows llama models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation, 2023. URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_modes_to_have/.Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, TimothÅLee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023a. URL https://api.semanticscholar.org/CorpusID:257219404.Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian CantÅLon Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S.Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b. URL https://api.semanticscholar.org/CorpusID:259950998.Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv, abs/1810.04805, 2019. URL https://api.semanticscholar.org/CorpusID:52967399.Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Annual Meeting of the Association for Computational Linguistics, 2021. URL https://api.semanticscholar.org/CorpusID:247519241.Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. ArXiv, abs/1911.05507, 2019. URL https://api.semanticscholar.org/CorpusID:207930593.Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers. ArXiv, abs/2305.16300, 2023. URL https://api.semanticscholar.org/CorpusID:258887482.DevOpsGPT 是我们发起的一个针对 DevOps 领域大模型相关的开源项目,主要分为三个模块。本文介绍的 DevOps-Eval 是其中的评测模块,其目标是构建 DevOps 领域 LLM 行业标准评测。此外,还有 DevOps-Model、DevOps-ChatBot 两个模块,分别为 DevOps 领域专属大模型和 DevOps 领域智能助手。我们的目标是在 DevOps 领域,包含开发、测试、运维、监控等场景,真正地结合大模型来提升效率、成本节约。我们期望相关从业者一起贡献自己的才智,来让 “天下没有难做的 coder”,我们也会定期分享对于 LLM4DevOps 领域的经验 & 尝试。(1)ChatBot - 开箱即用的 DevOps 智能助手:https://github.com/codefuse-ai/codefuse-chatbot(2)Eval - DevOps 领域 LLM 行业标准评测:https://github.com/codefuse-ai/codefuse-devops-eval(3)Model - DevOps 领域专属大模型:https://github.com/codefuse-ai/CodeFuse-DevOps-Model(4)CoCA - 蚂蚁自研新一代 transformer:https://github.com/codefuse-ai/Collinear-Constrained-Attention
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]