在科学研究及其应用中,科学文献分析的重要性不言而喻,它使研究人员得以在前人的基础上进行进一步的探索。然而,随着科学的快速迭代发展,科学文献的数量急剧增加,使得深入分析文献的难度和所需的时间大幅提升。为了提高信息检索的效率,SciFinder 和 Reaxys 等专业的科学文献数据库应运而生。然而它们的作用仅限于普通的检索,缺乏信息提取和知识理解的能力,用户仍需阅读和分析检索到的文档,以提取确切答案。大型语言模型如 ChatGPT 的出现,标志着自然语言处理演进的重要里程碑。这些模型彻底改变了从文档中提取文本信息的方式,能够利用提取的内容直接获得答案。尽管它们在提取文本方面表现出色,但现有的大模型主要设计用于文本提取,常常难以理解科学文献中固有的多模态内容,如表格、图表、分子结构、化学反应等。为了应对这一挑战,深势科技此前推出了 Uni-Finder 的产品内测,一款先进的文献和专利信息处理的引擎产品。继该产品发布后,我们持续致力于优化产品背后的核心算法——Uni-SMART(Universal Science Multimodal Analysis and Research Transformer),这是一个为深入理解多模态科学文献而设计的创新模型。同时,我们设计了 SciAssess (SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis),一个跨领域、高质量的科学文献分析能力评测方案,旨在全面、客观地评估 Uni-SMART 的能力。目前,Uni-SMART 和 SciAssess 的最新技术报告已在 ArXiv 公开。其中,Uni-SMART 被 HuggingFace 官方的 Daily Papers 收录,且短短几小时便冲上了榜上第一名!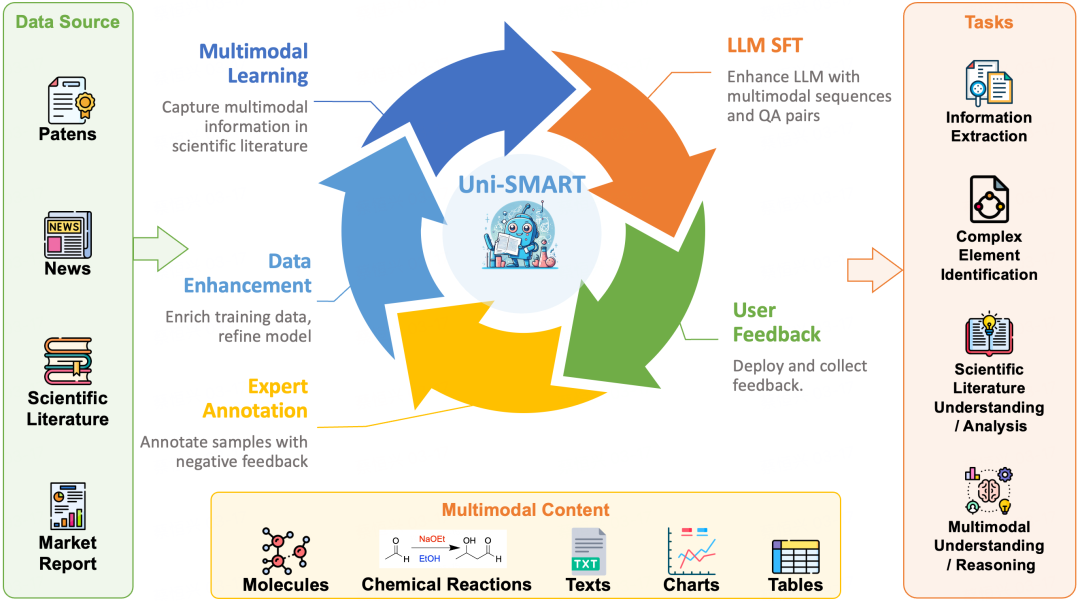
Uni-SMART 使用了广泛的科学文献数据源,包括专利、科学出版物、新闻文章、市场报告等。并采用了主动学习(Active learning)的方法来不断增强模型的能力:
1. 多模态学习 (Multimodal Learning):在初始阶段,模型通过较少的多模态数据进行训练,以识别和提取科学文献中的各种信息元素,并将这些信息以序列化的形式进行输出,该序列化结果中包含了文本和多模态信息。2. 大模型有监督微调 (LLM SFT):利用上一步产生的序列化输出以及对应的 QA 对,对大模型进行有监督微调,增强大模型处理和理解多模态信息的能力。3. 用户反馈 (User Feedback):经过 SFT 增强的大模型部署到实际应用中,期间,我们从明确给予同意的内部用户中收集反馈。收到正反馈的样本将被筛选并随后进入数据增强环节,而收到负反馈的样本则需经过专家标注后进入到数据增强环节中。4. 专家标注 (Expert Annotation):获得负反馈的样本会由内部的领域专家进行细致的标注,确保模型能够从这些错误中学习并改进,半自动化工具将在这个过程中提供帮助以提高标注效率。负反馈的案例通常分为两类:一类是多模态识别错误导致的,第二类是大模型的理解或推理错误导致的。通过细致的错误类型分析,从而促进更有针对性的改进。5. 数据增强 (Data Enhancement):将专家标注后的数据,以及部分正反馈的样本增加到模型的训练数据中,实现数据集的不断扩充。不断重复这一迭代过程,以此来优化 Uni-SMART 的整体性能。这种循环迭代的流水线显著提升了 Uni-SMART 在各种任务中的表现,如信息提取、复杂元素识别、科学文献理解和分析,以及多模态元素的理解和推理等。
我们设计了一个专门评测科学文献理解的评估方法 SciAssess,旨在对 LLM 在文献理解的能力进行全面、客观、科学的评估。评测的数据包含了广泛的学科,包括化学、材料、药物发现等,并在每个学科中挑选了各自有代表性的任务。我们使用 SciAssess,将 Uni-SMART 和其他主流的大型语言模型进行了横向对比,定量评估他们在科学文献多模态元素理解的能力。
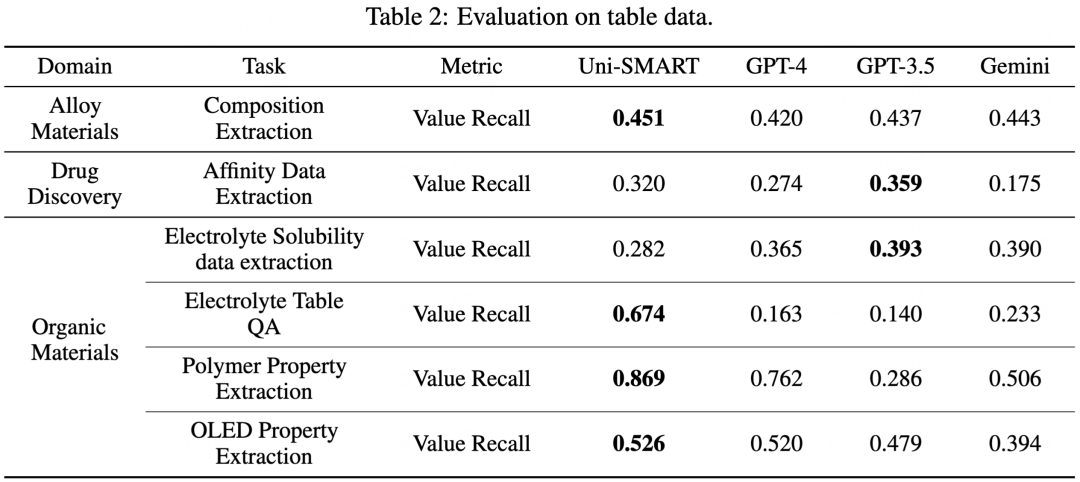
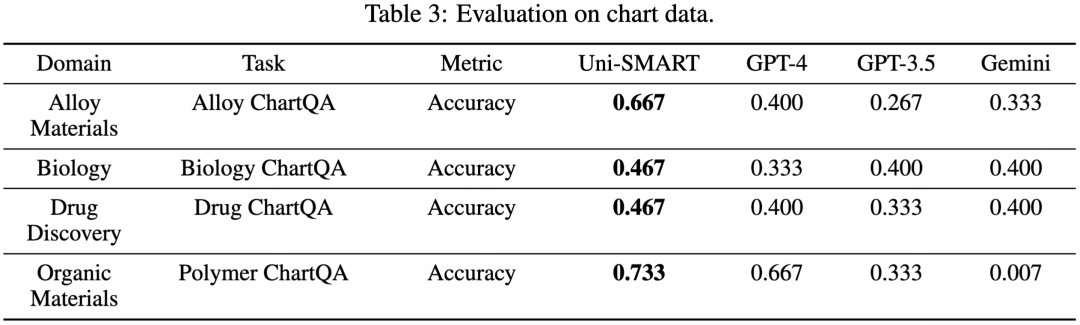
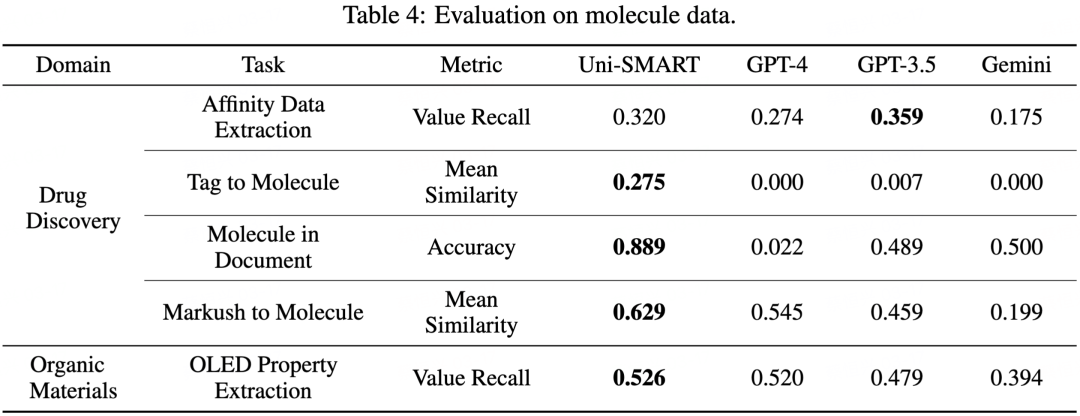
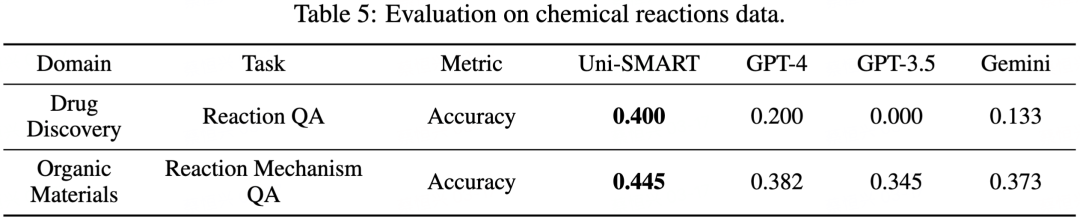
从上述评估结果可以看出,Uni-SMART 在处理包含表格、图表、分子结构以及化学反应式等多模态元素任务中,相较于其他主流大模型如 GPT-4、GPT-3.5 以及 Gemini,展现出了显著的优势。在绝大多数的评估任务中,Uni-SMART 都处于领先地位。这些结果不仅证明了 Uni-SMART 在理解科学文献多模态元素方面的卓越性能,也展现了它在处理专业科学内容方面的强大能力。通过 Uni-SMART,我们可以期待在科学文献的深度理解和应用上实现更大的突破,加速科学发现的过程。1. 专利侵权判定

在研究和工业领域,正确理解和应用专利信息变得日益重要。尤其是在化学和药物开发领域,准确判断一个化合物是否受现有专利保护对于避免潜在的专利侵权至关重要。在这个案例中,我们利用 Uni-SMART 分析特定化合物是否受某一篇专利所保护。如图所示,通过考虑分子的骨架和取代基等多种因素,模型正确地判断出该化合物是否属于该专利的保护范围,展示了其强大的跨模态信息处理能力。2. 温度控制图解析
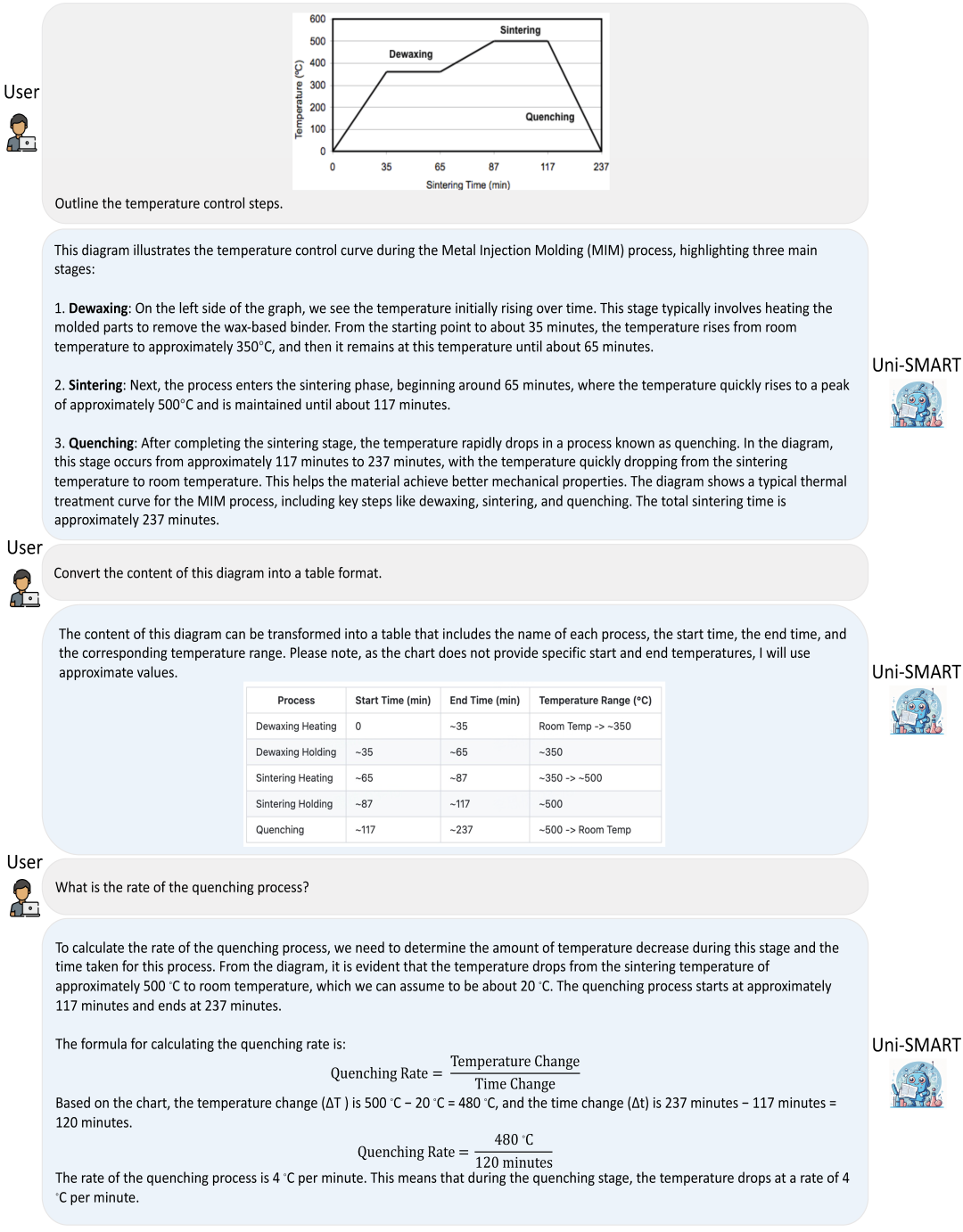
在科学文献中,图表是传递复杂数据和实验结果的关键工具,理解图表的信息对于深入理解文章细节起着至关重要的作用。在这个案例中,我们利用 Uni-SMART 对金属注射成型温控曲线进行分析。如图所示,Uni-SMART 准确地描述了曲线的变化过程,精准地识别出其中的关键数据点,并按照用户指示将这些信息转换成了表格的格式。此外,在淬火率的计算过程中,模型还展示出了强大的数学计算和逻辑推理能力。https://uni-smart.dp.tech/
https://arxiv.org/abs/2403.10301https://uni-finder.dp.tech/https://arxiv.org/abs/2403.01976https://github.com/sci-assess/SciAssess#小程序://Bohrium/z7YFPNP8wlQt5e深势科技是“AI for Science”科学研究范式的引领者和践行者,致力于运用人工智能和多尺度的模拟仿真算法,结合先进计算手段求解重要科学问题,为人类文明最基础的生物医药、能源、材料和信息科学与工程研究打造新一代微尺度工业设计和仿真平台。我们开创性地提出了「多尺度建模+机器学习+高性能计算」的革命性科学研究新范式,并推出了Bohrium®科研云平台、Hermite®药物计算设计平台、RiDYMO®难成药靶标研发平台及 Piloteye®电池设计自动化平台等工业设计与仿真基础设施,颠覆了现有研发模式,打造“计算引导实验、实验优化设计”的全新范式。深势科技是国家高新技术企业、国家专精特新“小巨人”企业,总部位于北京,并在上海、深圳等城市布局研发中心。科研技术团队由中国科学院院士领衔,汇集了超百位数学、物理、化学、生物、材料、计算机等多个领域的优秀青年科学家和工程师,其中公司的博士及博士后占比超过35%。核心成员获得过2020年全球计算机高性能计算领域的最高奖项“戈登贝尔奖”,相关工作当选2020年中国十大科技进展和全球AI领域十大技术突破。
点击“阅读原文”了解更多