

首个中文原生DiT架构,中文原生文生图大模型来了!智东西5月15日报道,腾讯文生图负责人芦清林周二宣布腾讯混元文生图大模型全面开源。该模型已在Hugging Face平台及Github上发布,包含模型权重、推理代码、模型算法等完整模型,与腾讯混元文生图产品最新版本完全一致,基于腾讯海量应用场景训练,可供企业与个人开发者免费商用。
这是业内首个中文原生的DiT架构文生图开源模型,支持中英文双语输入及理解,参数量15亿。跟其他业界开源模型对比,混元DiT在多个维度上无短板,并在美学和清晰度维度上具有一定优势。其综合指标在所有开源和闭源算法中排名第三,实现开源版本中的SOTA。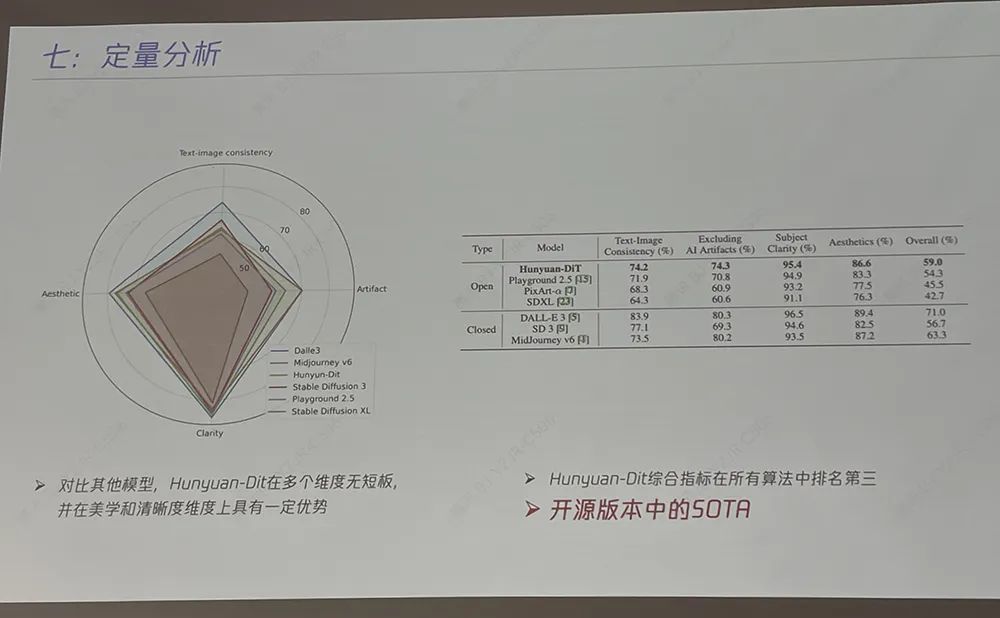
评测数据显示,腾讯混元文生图模型效果远超开源的Stable Diffusion模型及其他开源文生图模型,是目前效果最好的开源文生图模型;整体能力属于国际领先水平。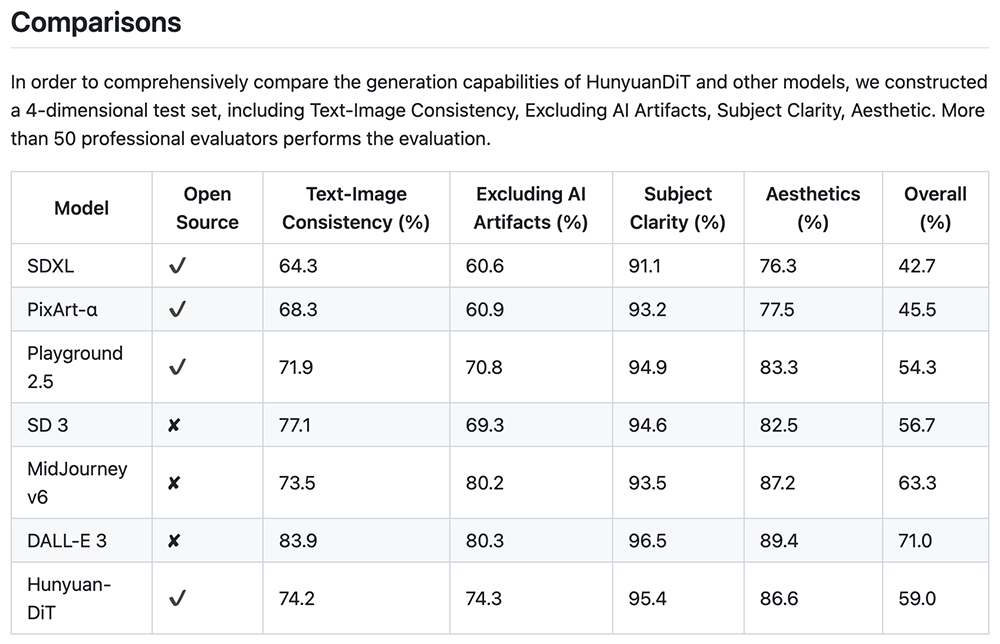
升级后的混元文生图大模型采用了与Sora、Stable Diffusion 3一致的DiT架构,可支持文生图,也可作为视频等多模态视觉生成的基础。混元文生图整体模型主要由3个部分组成:a)多模态大语言模型,支持用户文本改写以及多轮绘画;b)双语文本编码器,构建中英文双语CLIP理解文本,同时具备双语生成能力;c)生成模型,从U-Net升级为DiT,采用隐空间模型,生成多分辨率的图像,确保图像整体的稳定结构。GitHub项目页面建议使用具有32GB内存的GPU运行模型,以获得更好的生成质量。
在芦清林看来,此前开源与闭源文生图模型的差距逐渐拉大,他希望腾讯混元文生图大模型的开源后能够将差距缩小。腾讯混元已面向社会全面开放,企业级用户或开发者可通过腾讯云使用腾讯混元大模型,个人用户可通过网页端与小程序体现腾讯混元的能力。官网:http://dit.hunyuan.tencent.com/
代码:https://github.com/Tencent/HunyuanDiT
模型:https://huggingface.co/Tencent-Hunyuan/HunyuanDi
论文:
https://tencent.github.io/HunyuanDiT/asset/Hunyuan_DiT_Tech_Report_05140553.pdf
过去,视觉生成扩散模型主要基于U-Net架构,但随着参数量提升,基于Transformer架构的扩散模型(DiT)展现出了更好的扩展性。U-Net只懂图片,遇到难题易卡壳,而Transfomer能懂不同模态信息,参数/数据量越多越厉害。DiT是结合扩散模型和Transformer架构的创新技术,有高扩展和低损失的优势,更易扩展,有助于提升模型的生成质量及效率。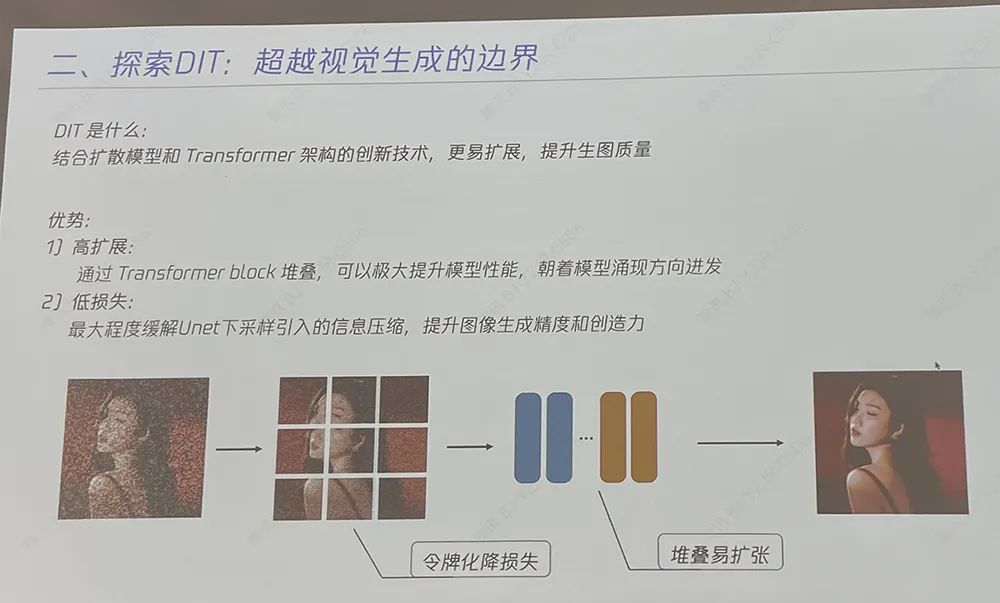
该架构通过Transformer block堆叠,可极大提升模型性能,并最大程度缓解U-Net下采样引入的信息压缩,提升图像生成精度和创造力。据腾讯文生图负责人芦清林分享,在原始DiT架构之上,混元DiT有三大升级:一是强大建模能力,将文生图架构从自研U-Net架构升级为更大参数的DiT模型,提升图像质量和扩展能力,让DiT架构具备了长文本理解能力,支持最长256个字符的图片生成指令;同时利用多模态大语言模型,对简单/抽象的用户指令文本进行强化,转写成更丰富/具象的画面文本描述,最终提升文生图的生成效果。二是增加中文原生的理解能力,自主训练中文原生文本编码器,让中文语义理解能力更强,对中文新概念学习速度更快,对中文认知更深刻,同时让模型更细致地分辨不同粒度文本信息。三是增强多轮对话能力,与自研大语言模型结合,让模型具备上下文连贯的理解能力,同时通过技术手段控制同一话题与主体下图片主体的一致性。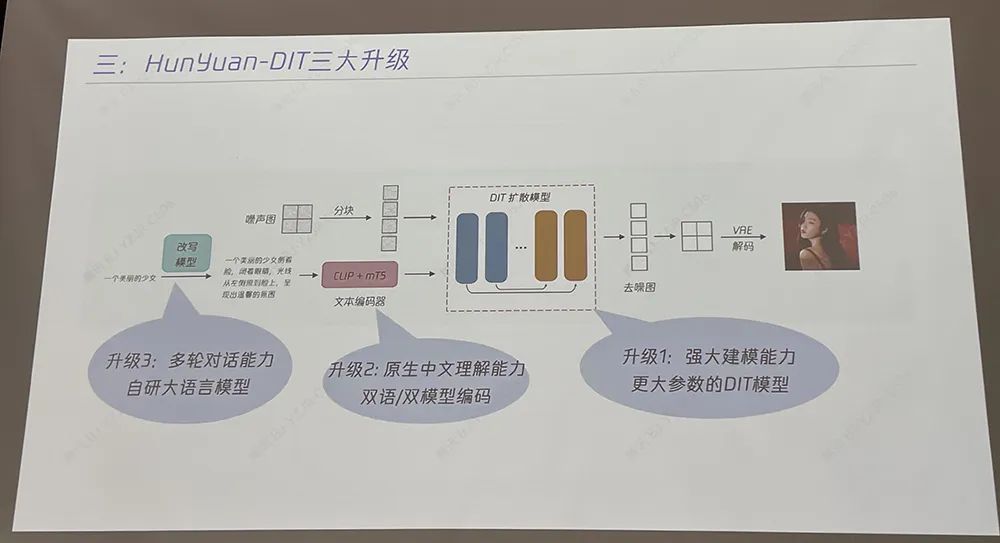
学术界去年提出基础DiT架构,混元DiT在此之上进一步升级,有更强语义编码,针对更长、更复杂的文本能理解得更准确,原生中英双语支持,尺寸更易扩展。
混元DiT架构具备更稳定的训练过程,通过优化模型结构,支持数十亿参数和1024分辨率的模型稳定训练。它还拥有更好的生态兼容性,可灵活支持ControlNet、LoRA、IP-Adapter、Photomaker等Stable Diffusion社区的插件。同时,该架构支持输出多分辨率图像,提升不同分辨率生成图像的质量,包括1:1、4:3、2:4、16:9、9:16等多种分辨率,支持768~1280分辨率图像生成。混元文生图是首个中文原生的DiT模型,具备中英文双语理解及生成能力,在古诗词、俚语、传统建筑、中华美食等中国元素生成上表现出色。通过语言编码器升级,混元DiT架构对中文的认知更加深刻,相比核心数据集以英文为主的Stable Diffusion等主流开源模型,能更好理解中国的语言、美食、文化、习俗、地标等。比如在生成昆曲艺术家表演的图像时,混元文生图在理解昆曲艺术方面明显比其他国外主流文生图模型更准确。
升级的混元文生图能更细致地分辨不同信息。其训练方式是把数据做成正负样本,对比学习损失,让模型学会什么是对、什么是错,做到理解和表达更细致的属性。比如输入一段涉及大量细节描述的文字,混元文生图能够精细理解文字要求,生成符合各种细节的图像。
混元文生图在算法层面创新实现了多轮生图和对话能力,可在一张初始生成图片的基础上通过自然语言描述进行调整,达到更满意的效果。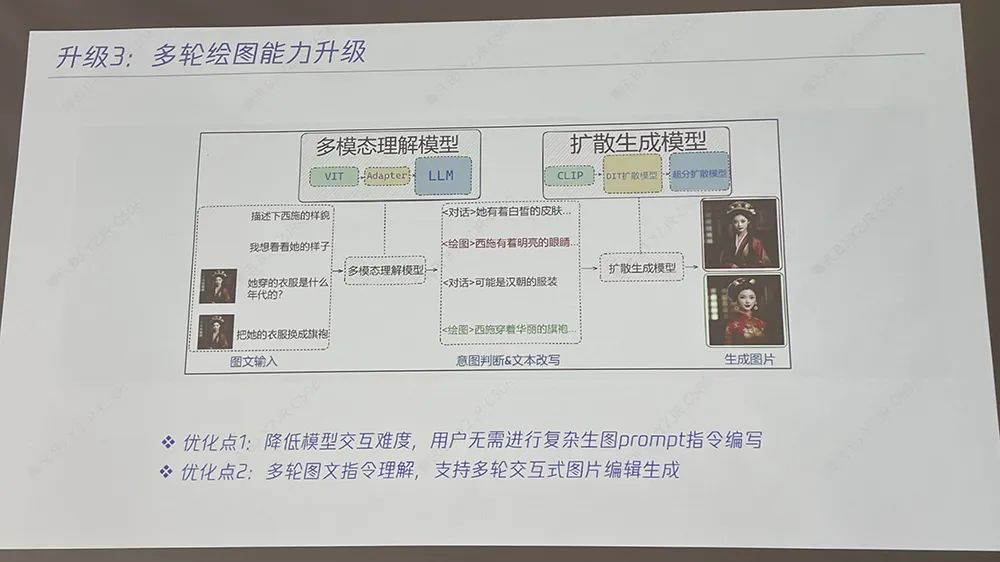
比如起初输入指令“生成一朵长在森林中的白色玫瑰”,再要求“改成百合花”、“改成粉色”、“改成动漫风格”;起初输入指令“画一只色彩斑斓的折纸小狐狸折纸”,再要求“把背景换成沙漠”、“把狐狸换成小狗”。
模型交互难度进一步降低,用户无需进行复杂生图提示词指令编写。混元文生图能实现多轮图文指令理解,支持多轮交互式图片编辑生成,支持十轮以上的对话。
腾讯混元团队认为基于Transformer架构的扩散模型(如DiT)具有更大的可扩展性,很可能成为文生图、生视频、生3D等多模态视觉生成的统一架构。2023年7月起,业界研究DiT的团队还不多,当时混元文生图就明确了基于DiT架构的模型方向,并启动了长达半年的研发、优化、打磨。今年年初,混元文生图大模型已全面升级为DiT架构,并在多个评测维度超越了基于U-Net的文生图模型。数据显示,在通用场景下,基于DiT视觉生成模型的文生图效果,相比前代视觉生成整体效果提升20%,画面真实感、质感与细节、空间构图等全面提升,并在细粒度、多轮对话等场景下效果提升明显。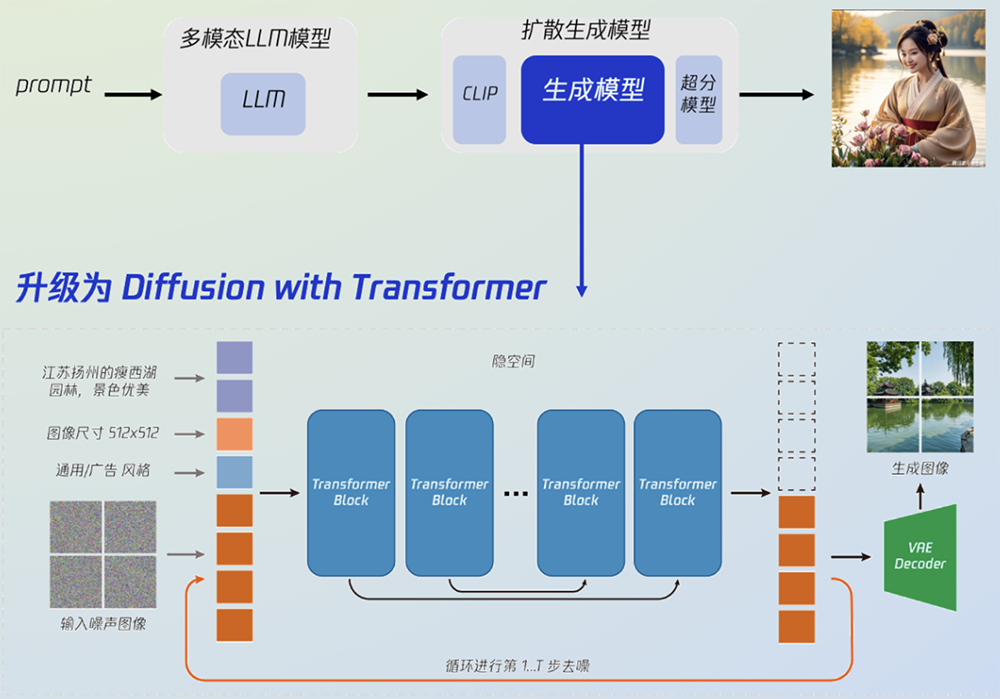
这里面存在极大难点:首先,Transformer架构本身并不具备用户语言生图能力;其次,DiT本身对算力和数据量要求极高,文生图领域缺乏高质量的图片描述与图像样本训练数据。腾讯混元团队在算法层面优化了模型的长文本理解能力,能够支持最多256个字符的内容输入(业界主流是77个),从零开始训练,做到全链路自研,在模型算法、训练数据集与工程加速多个层面进行了系统化的创新研发。针对文生图训练数据缺乏、普遍质量不高的问题,腾讯混元团队通过优化图片描述能力、样本评估机制等提升文生图训练数据的规模和质量,同时利用多模态大语言模型强化与丰富用户指令文本,从而提升最终文生图效果。混元文生图大模型基于腾讯自研的Angel机器学习平台进行训练,大幅提升了训练效率。为了更好地提升模型训练与运行效率,提升算力资源利用率,团队为该模型构建专属工程加速工具库。
为什么选择在这个节点开源?在媒体交流环节,芦清林谈到这主要出于两点考虑,一是在业界投入DiT研发的时间早,经历长时间的打磨,成熟度达到开源条件;二是看到业界需要开源中文原生DiT文生图模型。过去业界文生图大多基于Stable Diffusion,开源社区有数量庞大的开发者和创作者,基于Stable Diffusion精调出了丰富的垂直场景模型,同时衍生出大量国内外模型分享与流通社区。主要的文生图开源社区依然主要基于U-Net架构模型进行开发,仍未有比较先进的DiT架构充分开源。而无论Stable Diffusion 3还是Sora都采用DiT架构来构建下一代图像/视频生成能力。开源社区缺乏先进/成熟的DiT架构开源利用,业界也难以快速吸收学术界大模型前沿技术。中文原生的DiT文生图架构同样是缺失的。在中文场景,很多团队基于翻译+英文开源Stable Diffusion模型,导致在中文特有的场景、人物、事物上表现比较差。还有一些团队基于少量的中文数据在一些特殊的场景做了微调,让模型去适配某个特殊的领域或者风格。但直接用英文预训练的模型+中文小数据微调也存在对中文理解不足和不通用的问题。即使国外有些论文公开,这些架构更多偏英文,对中文理解差,而且没在大众中做验证,在中文应用场景受限。由中文翻译成英文可能会导致出图有歧义,比如中文“一只很热的狗在餐厅”翻译成英文“A very hot dog in the restaurant”就变味了,会生成“一盘热狗(hot dog)”图。
而开源DiT研发成果,意味着全球个人和企业开发者都能直接都能直接用上了最先进的架构,不用自己重新研发和训练,大大降低了AI使用门槛,也节省了人力物力。基于腾讯此次开源的文生图模型,开发者及企业无需重头训练,即可直接用于推理,并可基于混元文生图打造专属的AI绘画应用及服务,能够节约大量人力及算力。透明公开的算法也让模型的安全性和可靠性得到保障。基于开放的混元文生图基础模型,还有利于在以Stable Diffusion等为主的英文开源社区之外丰富以中文为主的文生图开源生态,形成更多样的原生插件,推动中文文生图技术研发和应用。腾讯已开源超170个优质项目,均来源于腾讯真实业务场景,覆盖微信、腾讯云、腾讯游戏、腾讯AI、腾讯安全等核心业务板块,目前在Github上已累计获得超47万开发者关注及点赞。
此前的开源生态、数据集均以英文为主,建设中文原生的文生图开源模型、中文的文生图开源生态,是十分必要的。此次把最新一代模型完整开源出来,腾讯混元团队希望与行业共享在文生图领域的实践经验和研究成果,丰富中文文生图开源生态,共建下一代视觉生成开源生态,推动大模型行业加速发展。芦清林分享说,混元文生图的后续优化方向包括提升技术能力和在更广泛的场景中应用。腾讯混元文生图能力已广泛被用于素材创作、商品合成、游戏出图等多项业务及场景中。今年初,腾讯广告基于腾讯混元大模型发布了一站式AI广告创意平台腾讯广告妙思。《央视新闻》《新华日报》等20余家媒体也已经将腾讯混元文生图用于新闻内容生产。据芦清林透露,目前混元文生图大模型的参数规模是15亿,同时团队已经在探索参数量更大的模型。他坦言模型在写中文文字的效果上还没做到非常成熟,等做好后也会拿出来分享。
(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)
