【新智元导读】深度神经网络有多种规模和架构,大家普遍认为这会影响到模型学习到的抽象表示。然而,UCL两位学者发表在ICML 2024上第一篇论文指出,如果模型的架构足够灵活,某些网络行为在不同架构间是广泛存在的。
自从AI跨入大模型时代以来,Scaling Law几乎成为了一个共识。

论文地址:https://arxiv.org/abs/2001.08361
OpenAI的研究人员在2020年的这篇论文中提出,模型的性能与三方面的指标呈幂律关系:参数量N、数据集规模D以及训练算力C。除了这三方面外,在合理范围内,超参数的选择和模型的宽度、深度等因素对性能的影响很小。而且,这种幂律关系的存在没有对模型架构做出任何规定。换言之,我们可以认为Scaling Law几乎适用于任何模型架构。此外2021年发表的一篇神经科学领域的论文似乎也从另一个角度触碰到了这个现象。
论文地址:https://www.frontiersin.org/journals/computational-neuroscience/articles/10.3389/fncom.2021.625804/full他们发现,为视觉任务设计的AlexNet、VGG、ResNet等网络,即使有较大的结构差异,但在同一数据集上进行训练后,似乎能学习到非常相似的语义,比如对象类别的层次关系。但这背后的原因究竟是什么?如果超越表层经验,在本质层面上,各种网络架构究竟在多大程度上相似?UCL的两位研究者在今年发表了一篇论文,从神经网络学习到的抽象表示方面切入,试图回答这个问题。
论文地址:https://arxiv.org/abs/2402.09142他们推导出了一种理论,能够有效地概括复杂、大型模型架构中的表征学习动态,发现了其中「丰富」且「惰性」的特征。在模型足够灵活时,某些网络行为就能在不同架构中广泛存在。
通用近似定理(universal approximation theorem)指出,给定足够参数,非线性神经网络可以学习并逼近任意平滑函数。受到这个定理的启发,论文首先假定:从输入到隐藏表示的编码映射,以及从隐藏表示到输出的解码映射,都是任意平滑函数。因此,在忽略网络架构的细节时,可以用以下方法对函数动态进行建模:训练神经网络的过程可以被视为平滑函数 在特定数据集𝒟上的优化,不断改变网络参数𝜃以最小化MSE损失函数:由于我们对研究表征空间的动态过程感兴趣,因此函数𝑓𝜃可以被拆分为两个平滑映射的组合:编码映射ℎ𝜃:𝑋→𝐻,以及解码映射𝑦𝜃:𝐻→𝑌,此时方程(1)中的损失函数可以写作:接下来,使用梯度下降规则更新参数𝜃的过程可以写作:方程(4)虽然足够准确,但问题在于它显式地依赖于网络参数𝜃,足够通用的数学表达需要忽略这种实现细节。理想情况下,如果神经网络的表达能力足够丰富,对损失函数𝐿的优化,应该可以直接表达为关于两个映射ℎ𝜃和𝑦𝜃的函数。然而,如何从数学层面实现这一点仍不清楚。因此,我们先从更简单的情况入手——不考虑整个数据集,而是两个数据点。训练期间,由于映射函数ℎ𝜃和𝑦𝜃的变化,不同数据点的表示会在隐藏空间中𝐻移动,彼此靠近或交互。
在特定数据集𝒟上的优化,不断改变网络参数𝜃以最小化MSE损失函数:由于我们对研究表征空间的动态过程感兴趣,因此函数𝑓𝜃可以被拆分为两个平滑映射的组合:编码映射ℎ𝜃:𝑋→𝐻,以及解码映射𝑦𝜃:𝐻→𝑌,此时方程(1)中的损失函数可以写作:接下来,使用梯度下降规则更新参数𝜃的过程可以写作:方程(4)虽然足够准确,但问题在于它显式地依赖于网络参数𝜃,足够通用的数学表达需要忽略这种实现细节。理想情况下,如果神经网络的表达能力足够丰富,对损失函数𝐿的优化,应该可以直接表达为关于两个映射ℎ𝜃和𝑦𝜃的函数。然而,如何从数学层面实现这一点仍不清楚。因此,我们先从更简单的情况入手——不考虑整个数据集,而是两个数据点。训练期间,由于映射函数ℎ𝜃和𝑦𝜃的变化,不同数据点的表示会在隐藏空间中𝐻移动,彼此靠近或交互。比如,对于数据集中的两点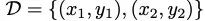 ,如果ℎ𝜃(𝑥1)和ℎ𝜃(𝑥2)足够接近且ℎ𝜃和𝑦𝜃是平滑函数,那么可以利用两点的均值,对这两个映射函数进行线性近似:
,如果ℎ𝜃(𝑥1)和ℎ𝜃(𝑥2)足够接近且ℎ𝜃和𝑦𝜃是平滑函数,那么可以利用两点的均值,对这两个映射函数进行线性近似:
假定神经网络有足够的表达性和自由度,线性化参数𝐷ℎ、𝐷𝑦和 可以得到有效优化,那么梯度下降的过程就可以表示为:方程(6)就描述了论文主要的建模假设,旨在作为大型复杂架构体系的等效理论,不受具体参数化方法的约束。图1是上述建模过程的可视化表达,为了简化问题,假设两个数据点在隐藏空间中只会靠近或远离,但不发生旋转。其中我们关心的主要指标是隐藏空间中的距离‖𝑑ℎ‖,可以让我们得知模型学习到的表征结构,以及模型输出的距离‖𝑑𝑦‖,有助于建模损失曲线。此外,还引入了一个外部变量𝑤控制表征速度,或者可以被看作输出对齐,表示预测输出与真实输出的角度差异。其中,神经网络的实现细节已经被抽象化表达为两个常量:1/𝜏ℎ和1/𝜏𝑦,表示有效学习率。
可以得到有效优化,那么梯度下降的过程就可以表示为:方程(6)就描述了论文主要的建模假设,旨在作为大型复杂架构体系的等效理论,不受具体参数化方法的约束。图1是上述建模过程的可视化表达,为了简化问题,假设两个数据点在隐藏空间中只会靠近或远离,但不发生旋转。其中我们关心的主要指标是隐藏空间中的距离‖𝑑ℎ‖,可以让我们得知模型学习到的表征结构,以及模型输出的距离‖𝑑𝑦‖,有助于建模损失曲线。此外,还引入了一个外部变量𝑤控制表征速度,或者可以被看作输出对齐,表示预测输出与真实输出的角度差异。其中,神经网络的实现细节已经被抽象化表达为两个常量:1/𝜏ℎ和1/𝜏𝑦,表示有效学习率。
建模完成后,论文在两点数据集上训练了不同架构的神经网络,并将实际的学习动态与等效理论的数值解进行比较,结果如图2所示。
默认结构指20层网络、每层500个神经元,使用leaky ReLU
可以看到,虽然只有两个常数需要拟合,但是刚才描述的等效性理论依旧可以较好地拟合各种神经网络的实际情况。相同的方程可以准确描述多种复杂模型和架构在训练中的动态变化,这似乎可以说明,如果模型具有足够的表现力,最终都会收敛到共同的网络行为。放到MNIST这样更大的数据集上,跟踪两个数据点的学习动态,等效理论依旧成立。网络架构包括4个全连接层,每层包括100个神经元并采用leaky ReLU激活函数
然而值得注意的是,当初始权重逐渐增大时(图3),‖𝑑ℎ‖、‖𝑑𝑦‖和𝑤三个变量的变化模式会发生更改。因为初始权重较大时,两个数据点在训练开始时就会相距较远,因此公式(5)进行的线性近似就不再成立,上述理论模型失效。
从平滑约束以及上述的等效理论中,我们可以总结出神经网络表征结构方面的规律吗?根据公式(7)可以推导出,存在唯一的固定点,也就是两个数据点最终的表征距离:如果初始权重很大,最终的表征距离将收敛于𝐴high,数值取决于数据输入和随机初始化;反之,初始权重较小时则收敛于𝐴low,取决于数据的输入和输出结构。随机机制和结构化机制之间的这种分离进一步验证了之前论文提出的,深度神经网络学习过程中的「丰富性」和「惰性」,尤其是考虑到初始权重的尺度会成为一个关键因素。如果初始权重较大,训练开始时,隐藏空间中的两个数据点就会相距很远,因此网络的灵活性允许解码器自由地为每个数据点单独学习正确的输出,而不需要显著调整表征结构。因此,最终学习到的模式类似于初始化时已经存在的结构。相反,权重较小时,两个数据点的位置更靠近,由于平滑度限制,编码映射函数必须根据目标输出进行调整,将两个数据点的表示进行移动以适应数据。因此我们会看到,权重较小时,表征学习会呈现结构化效果(图5)。将神经网络的任务换为拟合异或函数(XOR)可以更直观地展现这一点。初始化权重较小时,模型明显学习到了异或函数的结构化特征。右侧只有2层的神经网络中,出现了理论和实验之间的较大偏差,说明上述理论中模型高表达力假设的重要性
这篇论文的主要贡献在于引入了一种等效理论,能够表达不同神经网络架构中动态学习过程的通用部分,并且已经展现出结构化的表征。由于建模过程的平滑度限制、对数据点交互的简化,这种理论仍无法成为描述深度神经网络训练过程的通用模型。然而,这项研究最可贵之处在于,它表明了表征学习所需的一些要素可能已经包含在梯度下降的过程中,而不仅仅是来自于特定模型架构所包含的归纳偏置。此外,该理论还强调了初始权重的尺度是最终形成表征结构的关键因素。未来工作中,我们仍需要找到一种方法,将等效理论扩展到能处理更大、更复杂的数据集,而不仅仅是对两个数据点的交互进行建模。同时,许多模型架构确实引入了影响表示学习的归纳偏差,可能与建模的表征效应发生潜在的相互作用。https://arxiv.org/abs/2402.09142
