从深度学习到深度造假,人工智能开始玩残人类

从深度学习到深度造假,人工智能开始玩残人类
解滨, CISSP, CISA
人工智能(AI)是不是可以用来杀人?这个问题最近有了答案。答案是:AI不但可以用来杀人,而且杀人的办法都找好了。
我经常写点“动态分析”之类的“小报告”,作为 cybersecurity threat intelligence briefing 的一部分。通常我也就是写点黑客小打小闹那一类的事。上个星期我讲的那件事跟人工智能有关,是一起最近在医学界和信息世界发生的大事。人类第一次把人工智能(AI)直接进行一项临床试验,没有事先做动物试验。而这项试验不是检验某项新药或新技术的疗效,而是证明某项新技术可以用来杀人。此事千真万确。
这项新技术说出来大家并不陌生,这就是“Deep Learning”,也就是AI中的“深度学习”的意思。你以为这项试验是深度学习如何去治病吗?错!恰恰相反,这是深度学习如何去造假,让医生出错,以至于通过医生的手把病人给杀了。听上去这是很坏的一件事,但这也是人工智能(AI)的一个新的应用。
这个新技术的概念不难理解。各位都知道,如今在医院里使用的MRI和CT都是计算机3D成像,靠计算机把2D扫描结果合成为3D图像。要读懂这些3D图像,需要牢固扎实的专业知识和丰富的临床经验,任何疏忽都有可能导致误诊或漏珍,可能造成病人死亡。所以呢,十几年前就有专家们苦思冥想,试图依靠AI 来辅助读片,以提高精准率,减少误读。这方面已经大有斩获,例如这一篇去年发表的论文
:https://www.ncbi.nlm.nih.gov/pubmed/29777175 。虽然进展可观,但那距离真正的临床普及应用还有相当的距离。N年前我给老东家MD安德森打工时曾经做过针对IBM Watson(IBM设计制造的一种智能机器)在医学上应用的系统的信息安全评估。那个投资十亿美元的玩意儿直到今天也还基本上在扯淡。
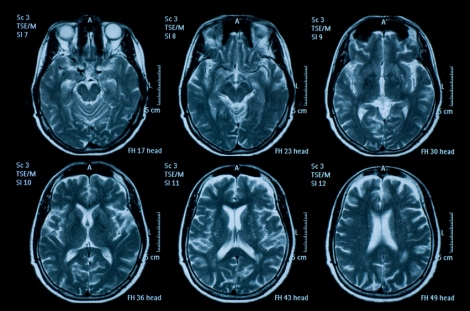
或许是受到来自某种邪恶势力的灵感的启发,有人转而一想,玛的老子辛辛苦苦干点正事总是不成,那干脆整点歪门邪道好了。说做就做!在使用AI辅助诊断还起色不大的同时,用AI在医学领域进行捣乱破坏的研究却风生水起,进展迅猛。这不,就在2019年4月3日,一篇惊世骇俗的论文出笼了。三名以色列的研究人员应用AI中的一个重要算法“深度学习”,成功地训练了一组恶意代码去偷看医院放射科网络(PACS - 图片存档和通信系统)中的新生成的MRI或CT图像。如果在图像中显示病人根本就木有患癌症,这恶意代码就自作主张地弄个癌症放到那图像中去。那么如果那些初始图像表明病人已经患了癌症呢?这一组恶意代码就自动地、神不知鬼不觉地把癌症从图像中给抹去。这样一来,本来没啥事的病人,被医生诊断为身患癌症,然后开始进行昂贵和痛苦的治疗,去治愈那根本就不存在的癌症。而那些已经患有癌症的病人,会被医生诊断为“十分健康”,而不采取任何治疗措施,直至他们一命呜呼。

这不是害人吗?这岂止是害人,简直是伤天害理!
这一划时代的研究成果于4月3日发表在一个学术期刊上,其链接在这里:
https://arxiv.org/pdf/1901.03597.pdf
这三位以色列学者治学十分严谨。他们把接受试验的专家们分为两组。第一组专家,让他们看的图像包括造假过的图像和没有经过造假的图像,不告诉这一组经验丰富的放射专家这些图像已经鱼龙混杂了。结果是,对于那些被植入虚假癌症的图像,专家们被欺诈的比例是99.2%。对于那些癌症被抹去的图像,欺诈成功率是95.8% (the attack had an average success rate of 99.2% for cancer injection and 95.8% for cancer removal)。另一组具有同样资历的专家们,他们被事先告知他们阅读的图像中有些已经被造假,然后让他们去从那些鱼龙混杂的图像中鉴别真伪。结果呢?那些专家们也是蒙查查,大体上还是无法有效地识别那些假货,尽管他们个个都是读片高手[knowledge of the attack did not significantly affect cancer removal (90% from 95.8%). However, the success of the cancer injection was affected (70% from 99.2%).]。
因为事先知道有假,有的专家们还使用了他们的AI软件进行辅助读片。结果这些AI读片软件也被同样是使用AI技术的造假代码给懵了:无法识别出那些深度造假的图像,其效率甚至还不如人工!
好的AI居然被坏的AI给打败了!什么叫邪门呢?这就是!
这件事情很快就在美国医学界的许多IT工作者中掀起轩然大波。如果这样的恶意代码被植入各大医院的放射科网络,那么就意味着将会有成千上万,甚至上百万的病人被误诊,乃至于死亡。这岂止是恶意代码,这简直就是一场大规模恶意屠杀!
至此,AI开创了一个令人不敢想象的新的功能:玩残人类。
人工智能(AI)的起源,可以追朔到希腊古代的神話传说中,技艺高超的工匠可以人工造人,并为其赋予智能或意识。用金属打造一个人型机器并不难,难的是给这个机器人安装一个具有人类智慧的大脑。上个世纪40年计算机的发明使一批科学家开始严肃地探讨构造一个电子大脑的可能性。八十年代,AI蓬勃发展,但课题局限在人机对话,翻译语言,图像解释,机器推理等方面。当年有些课题早已完成。我们今天使用的谷歌翻译以及各种翻译机就是其中一例,其中“深度学习”是关键算法之一。过去十年中,得益于大数据和计算机技术的快速发展,AI日趋成熟,开始渗透到越来越多的领域,如生态学模型训练、经济数据分析、疾病预测、新药研发等。其中一个重要的领域“深度学习”极大地推动了图像和视频处理、文本分析、语音识别等问题的研究进程。
就跟人类的任何发明既可以造福于人类也可以用于危害人类那样,或早或晚,或多或少, 新的技术不可避免地会被应用到不道德甚至罪恶的领域。炸药被用来制造杀人的枪炮, 核能被首先用来制造杀人的原子弹,化工产品被用于制造化学武器,计算机代码被用来制造计算机病毒,这都是典型的例子。但把AI用于犯罪,一直到两年前还是仅限于纸上谈兵,没有任何设计方案出笼。一年半以前,一个划时代的历史性转折终于到来,发生在您无法想象的一个领域。
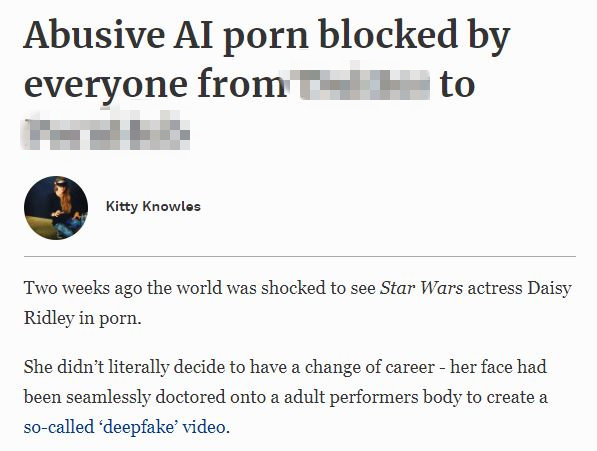
在2017年12月的某一天,在一个叫做“Reddit”的网站上,一个匿名作者上载了一个色情视频,这个视频的女主角是Daisy Ridley,她是知名的英国影视演员,《星球大战》的女主角。几个小时后这个色情视频就在网上炸开了锅。人们几乎不相信这位驰名欧美影坛的正妹居然会出演一个A片。但没有谁可以看出这个A片是伪造的,里面的女主角无论是声音还是造型或表情都跟Daisy Ridley一模一样,让人无可挑剔 - 就是她!惊恐之余,当人们看了这个视频的作者的笔名后,都会心地笑了:“Deepfakes”。这个笔名是“深度造假”的意思。这是从“Deep Learning”(深度学习)衍生过来的一个新词。这个以假乱真的视频的制作,就是充分使用了“深度学习”的一个新算法。虽然这一造假技术到了炉火纯青的水准,但由于其“产品”毕竟还是个假货,所以作者还算有点良心,把笔名冠之以“深度造假”。

上面这是Daisy Ridley在《星球大战》里的剧照

这是假的Daisy Ridley在那个色情片中一开始做自我介绍
几个星期后,“Deepfakes”这个新词便风靡欧美色情影视产业。为了满足各位“爱好者”的需求,一个月后第一个根据这个造假术设计的造假软件“FakeApp”正式出版。这大大降低了deepfake的使用门槛。这个软件让用户很轻松地自制换脸视频,即使你没有任何人工智能方面的知识。欧美的知名影视明星和歌星,例如Emma Watson, Katy Perry, Taylor Swift,Scarlett Johansson,统统都被色情技术控们使用深度造假的技术搬上了A片,“消费者”们直呼过瘾,争相先睹为快,一时间好评如潮。

这是Kety Perry被用“Deepfakes”造假的画面
不久一批深度造假色情网站如雨后春笋般建立起来。每当“消费者”们质疑那些深度造假的视频的真实性时,网站站主们都捶胸顿足地表示其来源“绝对可靠”,“这是那些大V们手下的技工们偷拍,然后不小心泄漏出来,本网站忍痛花重金购买,廉价呈现给各位,赔本赚吆喝”云云。与此同时,传统的色情网站门庭冷落。正牌的,循规蹈矩的色情网站受到Deepfake video的严重威胁,生意骤减,老牌色棍们对于这一波利用最新AI技术造假之辈嗤之以鼻,痛斥其之为“new breed of sexual abuse”。老牌色情网站纷纷联合起来抵制那些Deepfake videos,以保证A片的“纯洁性和真实性”。甚至就连那些跟色情视频八杆子打不到半点关系的大牌社交网站如推特、脸书也开始加盟抵制 Deepfake videos。
一年多过去了,人们对于 Deepfake video的新鲜劲大不如前(是不是能造假的脸都被造光了?)。然而人们对于 Deepfakes 这件事本身的热情却日渐高涨。根据本人的观察,几乎在所有的深度学习可以涉足的领域,深度造假都可以大显身手,有时甚至可以青出于蓝。本文一开始讲的这件事就是一个很好的例子。当deep learning在医学辅助诊断方面还在一筹莫展的时候, deepfakes 在医学领域里已经红杏出墙,花枝招展了!
说起来确实有点尴尬,AI的这项重大突破居然来自于一个肮脏的、令人不齿的角落。但那不过是深度学习的一个应用,其算法都是一样的。一样技术,只有用起来才能发展和改进。谁说坏的初衷就一定不可能带来好的结果呢?
Deepfakes这一技术即可用来做好事也可用来做坏事。这一技术可以让那些因ALS(肌萎缩侧索硬化)或癌症等疾病失去声音的人恢复演讲。自动驾驶软件首先可以在虚拟环境中接受培训。好莱坞可以用这种技术摄制高度惊险或美若仙境的大片,而不用担心高昂的成本。一些已经过世的知名演员如麦克杰克逊可以被重新搬上银幕,唱出新歌。这种技术使用在人机对话里,可以逼真地模仿某位知名人士的语音回答用户的问题。坏人可以用Deepfakes 伪造视频,制造假癌症和隐瞒真癌症,打造出以假乱真的新闻图片和视频新闻,涂改谷歌地图,把拿电子显微镜图片给修改掉,甚至把GPS的数据给涂改掉。骗子和政治极端分子将使用这种深度学习算法生成数不清的虚假信息(例如伪造某位政治人物的性丑闻,私房话,“通俄”录音等等)。通常社交网络有选择地传播最吸引眼球的内容,这些深度造假系统输出的内容将演变为最受欢迎的,并被广泛分享出去。实际上,很多种新的Deepfakes造假产品可能已经被研发出来了,只是你我还不知道而已。或许在明年的大选中就会有一批“新产品”面世。
说到这里,您是不是想知道究竟什么是“深度学习”呢?请注意本文前面引用的那篇论文的标题是:“CT-GAN: Malicious Tampering of 3D Medical Imagery using Deep Learning”。这里的第一个关键词是“GAN”,这是Generative Adversarial Network的缩写。这个算法是深度学习领域里革命性的突破。这是GAN之父Ian Goodfellow 于2014年发明的。GAN翻译成中文就是“对抗生成网络。”

GAN
GAN 是AI里面“非监督式学习”的一种算法,其基本原理是它有两个模型:一个生成网络G(Generator),一个判别网络D(Discriminator)。判别网络的任务是判断生成网给定图像是否看起来‘自然’,换句话说,是否像是人为(机器)生成的。而生成网络的任务是,生成看起来‘自然’的图像,要求与原始数据分布尽可能一致。为了便于您对GAN的过程做一个简要的了解,我虚构了下面这段不大恰当的对话来简要地示范一下:
太太:喂,老公,你看我长的像不像范冰冰?
老公:滚!
太太:老公你又在外面泡上哪个妞了,干嘛对我这么凶嘛?
老公:我谁都没有泡。不是我打击你的积极性,太太你实在不像范冰冰,差太远了。当然,尽管如此,你老公我也是爱你的,谁叫你老公这么没用,不是那个谁呢?
太太:哼!那我整容去!
三个月后,鼻梁整容好了。
太太:老公,现在我像不像范冰冰了?
老公:有进步但还有差距。就说你下巴,有范冰冰的下巴那么尖吗?跟一盘猪头肉似的。
太太:哼!
六个月后,下巴整容好了。
太太:老公你看,现在我跟范冰冰一模一样了吧?
老公:不行不行,横看竖看总觉得哪里就是不一样,我也说不出来。
太太:那你去好好看看范冰冰到底长的是啥样子嘛。
老公刚想敷衍,突然看见一则新闻:“我漂亮吗?美国脸盲男子不吭声被妻暴揍”,顿时吓出一身冷汗,怕自己脸盲被太太大人揍扁,于是赶紧下载了范冰冰的两个视频看了N遍,终于发现了太太的脸究竟为什么咋整都整不成范冰冰,然后跟太太提出了专家级的指导意见。
经过反反复复多次这样“校正”,终于在做完最后一个手术后的某一天,老公把太太一把抱在怀里:“太太我爱S你了”
……
上面这个过程,就是一个 GAN 训练的过程(大体就是这样,很多细节忽略了哈)。在这个虚拟的训练过程中,“太太”就是生成网络,“老公”就是判别网络。生成网络的目的是造样本,它的目的就是使得自己造样本的能力尽可能强,强到什么程度呢,你判别网络没法判断我是真样本还是假样本。判别网络的目的就是来识别一个样本,看看它是来自真样本集还是假样本集。生成网络从潜在空间(latent space)中随机采样作为输入,其输出结果需要尽量模仿训练集中的真实样本(“范冰冰”)。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本(真的范冰冰的玉照和视频)中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络(不断整容)。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实(太太整容整的跟真的范冰冰一模一样了)。

GANfather Ian Goodfellow
这个例子里,太太每整容一次,就相当于生成网每生成一个新的样本。老公作为判别网就判别一次,说那还不行。生成网络就不服了,说别瞧不起我,我也很牛叉,不信我再生成一个假样本给你看看。于是太太就再次整容,巧妙地包装,非要让老公(判别网)无法判断我是真范冰冰还是假范冰冰。就这样反复循环,直到最后判别不出区别来了。这叫“纳什平衡”(Nash equilibrium)。
在这个算法中,生成网跟判别网的目的是相反的:一个说我火眼金睛,能够判别你的真假;另一个说我魔高一丈,偏要让你判别不出真假。但判别网络也不是白吃干饭的,也在不断改进(上网下载范冰冰的视频做参照)。
GAN的强大之处就在于它模拟了真实世界中的过程。这种过程在真实世界中也是最优化的。无论你用它来进行仿真还是造假,这都是到目前为止最厉害的算法。
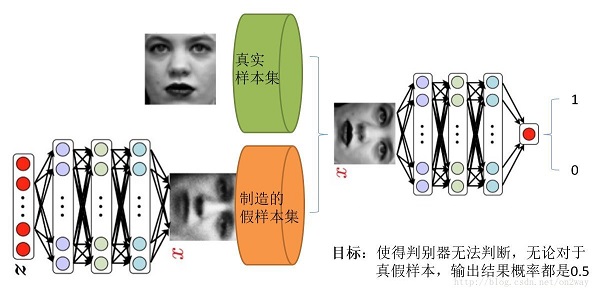
GAN的简要示意图
读者或许一开始阅读本文时就有一个大大的问号:那三个以色列学者是不是吃饱饭撑的,没事干居然去研究如何使用AI作案,干嘛不去做点正经八百的好事?这伤天害理的事情居然可以作为学术论文发表,给网上的坏蛋们通风报信。有人报案了吗?那三个家伙被抓起来了吗?那篇论文被撤了吗?我的答案是:那三位学者用他们的研究成果可能救了成千上万病人的命!利用AI作案,危害人类,这只是早晚的事。与其坐等坏人暗中发展AI武器,还不如及早把AI可能作案的途径都给找出来,及早预防。笔者至今还清楚地记得,2000年5月5日那一天, Love Bug worm在全球爆发,把人类打了个措手不及,导致五千万电脑里的文件被删除,成千上万个公司停产的那个场面。爱因斯坦在导出E = mc2这个公式后意识到原子弹的威力,他立即写信给罗斯福,提醒纳粹制造原子弹的可能性,建议美国赶在纳粹之前造出原子弹。幸亏爱因斯坦的提醒,盟军及时炸毁了纳粹的核试验装置。不然的话,人类历史将不会是今天这样。我们或许就不可能出生,或许在做法西斯占领军奴役下的亡国奴。
实际上,识别或防止深度造假的技术已经被发展出来,但要根据不同的种类采用不同的办法。识别Deepfake videos (深度造假视频),有一个诀窍,就是观察眨眼。人类一般每两秒到十秒之间要眨眼至少一次,而且是有规律的。但在深度造假的过程中,对眨眼的镜头是不进行深度学习的。这就造成那些深度造假视频里面的“假人”几乎不进行正常的眨眼。根据这个,设计一个程序,捕捉眨眼的瞬间,计算一下,就可以发现猫腻。这个方法是纽约大学奥本尼分校的三位华人学者发现的,这是他们的论文的链接:https://arxiv.org/pdf/1806.02877.pdf 。至于如何防止那三个以色列专家发明的方法对医学图像深度造假,其技术都已经是现成的,这就是“深度加密”:(1) 给每一个原始图像进行电子签名(digital signature)以防篡改,(2) 把放射科的网络统统给加密(end-to-end encryption), 以防偷看。完事。要防止卫星地图被非法篡改,可以使用同样的办法。不久的将来,视频和图片生成后,大多会进行电子签名和加密。谁先发明了能够放篡改和防造假的机器,谁就占领了先期市场。
虽然牛津字典还没有收入“Deepfakes”这个新词,虽然“Deepfakes”这个词在本文发布之前还没有被正式翻译成中文,但深度造假的概念实际上已经开始深入人心。估计半年后谷歌翻译就会把Deepfakes翻成“深度造假。” 现在有人将其翻译成“AI变脸”,这是不精确的。因为Deepfakes 应用的范围远不止变脸。
美国民主党有一个2020总统大选候选人(据说还是个“华人”),他认为人工智能(AI)终将导致大批工人失业,所以联邦政府应该发给每一个美国人每年1万2千美元的“universal basic income。” 杨总统把AI想得太简单了。
是的,AI确实可能导致某些人失业,但也将带来很多的就业机会呀!
不错,AI确实可以帮助人类解决许多难题,但也可能给人类带来新的危机。
对的,AI可以用来给人类看病,但也可以被用来杀人。
结论:AI可以用来干很多好事,也可以用来干很多坏事。并非只会让工人失业。
建议杨总统在兜售他的“AI造成大规模失业”这一理论之前花个至少半天的时间跟一位叫吴恩达(Andrew Ng)的华人专家好好请教一下究竟什么是AI,AI对我们社会今后的发展将会有哪些影响,等等。不要不懂装懂。

华人AI大牛吴恩达 Andrew Ng (不是Andrew Yang 的兄弟)
看看AI对于美国色情工业的大举入侵,那导致谁失业了吗?就说这三个以色列研究人员在Deepfakes的医学方面的最新应用,会导致谁失业吗?我怎么觉得刚好相反,job更加稳定了!
那么如何提前防止人类使用AI杀人呢?我们知道,在生物技术发展方面,各国都建立了道德委员会,设立了许多“禁区”,不许科学家们涉足。但在AI的发展方面,现在全世界没有任何一个道德委员会,今后也不会有。为什么会是这样呢?因为生物技术需要高额的投资和严格的工作场合,还有高度专业的技术。你没法在车库里进行克隆人的实验,普通人玩不起。但AI没有这些条件限制,任何一个高中生都可以在自家车库里用老爸算税的电脑来进行深度造假,低投资高效益(当然那个电脑必须有一个高级一点的GPU哈,不要跟我那台电脑上的那样滥)。人类可能没有任何东西能阻止即将到来的人工智能生成的内容。人工智能是把双刃剑。随着它的改进,它将能够模仿人类的行为。最终,它会变得和人非常像:善与恶的能力不相上下。
常言道,耳听为虚,眼见为实。美国人常说:The cameras don’t lie。有了Deepfakes,这两句话都不再生效了。AI已经把“眼见为实”打得没有招架之力了。
圣塔克拉拉大学法学院教授 Eric Goldman 说,我们最好为一个真假难辨的世界早做准备,但事实上,我们已经身处在这样一个世界中了。

理论物理学家霍金(Stephen Hawking)在五年前说过,人工智能目前的初步阶段已经证明非常有用。但他担心创造出媲美人类甚至超过人类的东西将要面对的后果。“它可能自行启动,以不断加快的速度重新设计自己。而人类局限于缓慢的生物进化过程,根本无法竞争,最终将被超越。” “人工智能的崛起是人类历史上最好的事情,也有可能是最糟糕的。” 他认为,“人工智能也有可能是人类文明史的终结,除非我们学会如何避免危险。”
把这一席话翻成通俗文字就是:人脑可以玩电脑,或许有一天,电脑也可以玩人脑,搞不好甚至玩残人脑,乃至于玩残人类!这就要看我们怎么玩了,嘿嘿。
这一天是不是已经开始了?
最后我郑重声明一下,本文的写作全部靠笔者的手工和人脑完成,没有使用任何AI,电脑只是用来阅读相关论文和打字的,不负责思维。要转载本文请联络本人:[email protected]。