
MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。论文名称:在知识蒸馏中发挥更大教师模型和更强训练策略的作用 Knowledge Distillation from A Stronger Teacher (NeurIPS 2022)
论文地址:
https://arxiv.org/pdf/2205.10536.pdf
在深度神经网络性能提升的过程中,模型通常会变得更深更宽。然而,由于计算和内存资源的限制,这种沉重的模型在实际应用中部署起来比较笨拙。知识蒸馏是指:通过在训练过程中蒸馏更大的模型 (教师) 的知识来提高小模型 (学生) 的性能。知识蒸馏的本质在于如何将知识从教师模型提炼到学生模型里面。最直观有效的方法是通过 Kullback-Leibler (KL) 散度[1]来匹配教师和学生之间的预测分数。一般来讲,KL 散度使得在训练过程中,可以用更有信息量的监督信息指导学生模型的训练,以期望获得更好的性能。题目中 "更强的教师模型",有两个含义:尺寸更大,数据增强策略更先进。获得更好的知识蒸馏性能的方式之一是尝试不同类型的教师模型 (比如说使用更大的教师模型或者更强的训练策略),作者在本文中认为:应该借助 "更强的教师模型" 进行知识蒸馏。而针对什么是 "更强的教师模型",作者推广实验给出了一些建议:- 除了扩大模型规模,还可以通过先进的训练策略,如标签平滑和数据增强 (label smoothing and data augmentation),以获得更强的教师模型。但是仅仅有这些是不够的。配备了更强的教师模型之后,学生模型在正常 KD 下的表现可能会下降,甚至性能还不如不用 KD。
- 当将教师和学生的训练策略转换为更强的训练策略时,教师和学生之间的差异往往会变得相当大。在这种情况下,通过 KL 散度来精确恢复预测可能具有挑战性,并导致 KD 的失败。
- 保留教师和学生模型之间的预测关系非常重要。在将知识从 teacher 传给 student 时,我们其实真正关心的是教师模型的偏好 (预测的相对 Rank),而不是去恢复其预测结果的绝对值。教师预测与学生预测之间的相关性有利于放松 KL 散度的精确匹配,提取内在关系 (intrinsic relations)。
令 和 分别代表教师和学生模型的输出, 式中, 为 Batch Size, 为通道数。原始的 KD Loss 可以写成:分别代表教师和学生模型的预测结果,是温度系数,控制 logit 值的 softness。综上,知识蒸馏的损失函数可以写成:式中, 是监督损失,一般是 Cross Entropy Loss。前面提到,当将教师和学生的训练策略转换为更强的训练策略时,教师和学生之间的差异往往会变得相当大。在这种情况下,通过 KL 散度来精确恢复预测可能具有挑战性,并导致 KD 的失败。如下图1所示,分别是为1和 为4时,使用训练策略 B1 和 B2 直接训练 ResNet18 和 ResNet50 的结果,结果标记为 (R18B1, R18B2, R50B1, R50B2),训练策略的详细说明如图2所示。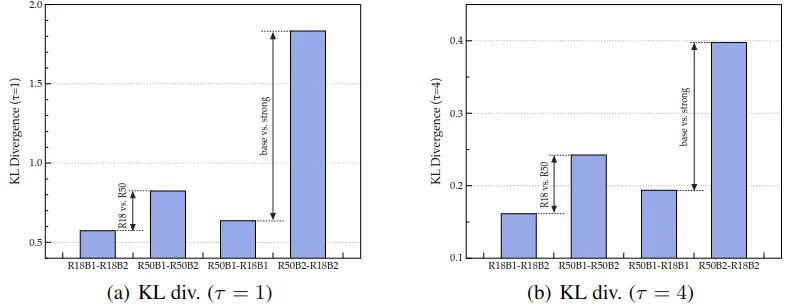 图1:ImageNet 验证集上的不同训练策略下的 ResNet 预测结果的差异 (KL 散度)
图1:ImageNet 验证集上的不同训练策略下的 ResNet 预测结果的差异 (KL 散度) 图2:详细的训练策略
图2:详细的训练策略- 与 ResNet-50 相比,ResNet-18 的输出在更强的训练策略下变化不大。这意味着学生模型的表征能力限制了其性能。同样的道理,当学生模型和教师模型的差异变得足够大时,使学生模型要完全匹配教师模型的输出往往具有挑战性。
- 当采用较强的策略训练师生模型时,师生之间的差异会更大。这说明当我们在更强的训练策略下采用 KD 时,KD 损失和常规分类损失的不一致会更严重,从而干扰学生的训练。
所以总的结论就是:当训练策略变得更强时,教师和学生差异拉大,传统的 KL 散度的精确匹配的模式 (即当且仅当教师和学生的输出完全相同时,损失达到最小值) 就显得过于苛刻。所以作者在本文的直觉是搞一种轻松的方式来匹配老师和学生之间的预测。希望在知识蒸馏的过程中,student 不用费劲地去匹配 teacher 的精确的输出结果,而是去匹配真正有用的东西。预测分数代表了一个模型对于所有类别的置信度,那么如果希望教师模型和学生模型的输出以一种更加轻松的方式匹配,作者认为只需要把各个类别输出置信度的关系匹配好就可以了,也就是去匹配教师模型预测结果的相对顺序。具体如下:也就是说, 在松弛匹配的要求下, 并不意味着 和 是完全相等的, 但是要注意映射 应是等值 (isotone) 的, 且不影响预测向量的语义信息和推理结果。因此,一个简单而有效的映射方式是正线性变换,它就满足松弛匹配的要求:式中, 是常数, 且有 。那要使得式4完全成立, 可以选择皮尔逊相关系数 (Pearson's distance):式6相当于是把 correlation 视为 relation,它舍弃了传统的 KL 散度的精确匹配的模式,而是采用一种较为松弛的模式,希望保持住每个实例教师和学生模型输出向量的线性相关关系。作者称这样的匹配为类间匹配 (inter-class relation),写成公式就是:除了类间的关系,作者还考虑到了单个样本中类内的关系。作者认为每个类的,多个实例的,预测分数也是有用的。举个例子, 我有三张图片, 里面的内容分别是 "猫", "狗", 和 "飞机", 它们对于 "猫" 这个类别的预测结果分别是 。那么, 猫图的对应 "猫" 类别的预测结果应该是最大的, 飞机那个图对应 "猫" 类别的预测结果应该是最小的。所以, 的关系也应当由教师模型传给学生。换个例子, 我有两张图片, 里面的内容分别是 "猫1", "猫2", 它们对于 "猫" 这个类别的预测结果分别是 。如果猫1图的对应 "猫" 类别的预测结果较大, 猫1图的对应 "猫" 类别的预测结果较小, 那么, 的关系也应当由教师模型传给学生。式中, 是超参数。作者通过类间匹配和类内匹配的方式,赋予了学生或多或少的自适应匹配教师网络输出的自由,从而在很大程度上提高了蒸馏性能。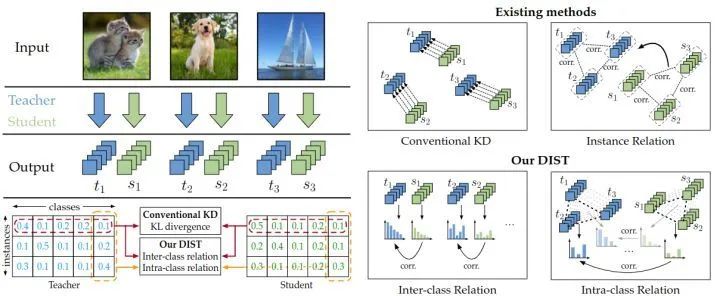 图3:DIST 方法的蒸馏策略
图3:DIST 方法的蒸馏策略import torch.nn as nn
def cosine_similarity(a, b, eps=1e-8):
return (a * b).sum(1) / (a.norm(dim=1) * b.norm(dim=1) + eps)
def pearson_correlation(a, b, eps=1e-8):
return cosine_similarity(a - a.mean(1).unsqueeze(1), b - b.mean(1).unsqueeze(1), eps)
def inter_class_relation(y_s, y_t):
return 1 - pearson_correlation(y_s, y_t).mean()
def intra_class_relation(y_s, y_t):
return inter_class_relation(y_s.transpose(0, 1), y_t.transpose(0, 1))
class DIST(nn.Module):
def __init__(self, beta, gamma):
super(DIST, self).__init__()
self.beta = beta
self.gamma = gamma
def forward(self, z_s, z_t):
y_s = z_s.softmax(dim=1)
y_t = z_t.softmax(dim=1)
inter_loss = inter_class_relation(y_s, y_t)
intra_loss = intra_class_relation(y_s, y_t)
kd_loss = self.beta * inter_loss + self.gamma * intra_loss
return kd_loss
根据前文的描述,**"更强的教师模型",有两个含义:尺寸更大,数据增强策略更先进**。因此作者先从第一个维度进行实验,换更强的教师模型,结果如下图4所示。当教师规模较大时,student 模型 ResNet-18 的表现甚至比中等规模的 teacher ResNet-50 更差。但是,DIST 在大 teacher 模型的情况下呈现上升趋势,并且与 KD 相比改进也变得更加显著,这表明 DIST 更好地处理了学生和大教师之间的巨大差异。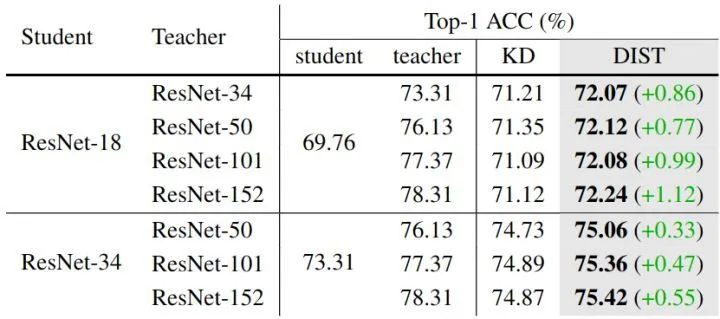 图4:更强的教师模型 ImageNet 实验结果最近,通过复杂的训练策略和强大的数据增强,ImageNet 上的模型性能得到了显著提高 (TIMM 在 ResNet-50 上达到了 80.4% 的精度,而基线策略 B1 仅获得 76.1% 的精度)。但是,目前大多数 KD 方法仍然在简单的训练设置下进行实验,作者进行了高级训练策略 KD 的实验,并将我们的方法与原始 KD 方法进行了比较。作者首先用强策略训练 ResNet-50,得到的准确率为 80.1%,如下图5所示。当学生模型使用 ResNet-18, ResNet-34,或者 MobileNetV2, EfficientNet-B0 时,DIST 都能达到最佳性能。DIST 在 Swin Transformer 上也能获得很好的效果。
图4:更强的教师模型 ImageNet 实验结果最近,通过复杂的训练策略和强大的数据增强,ImageNet 上的模型性能得到了显著提高 (TIMM 在 ResNet-50 上达到了 80.4% 的精度,而基线策略 B1 仅获得 76.1% 的精度)。但是,目前大多数 KD 方法仍然在简单的训练设置下进行实验,作者进行了高级训练策略 KD 的实验,并将我们的方法与原始 KD 方法进行了比较。作者首先用强策略训练 ResNet-50,得到的准确率为 80.1%,如下图5所示。当学生模型使用 ResNet-18, ResNet-34,或者 MobileNetV2, EfficientNet-B0 时,DIST 都能达到最佳性能。DIST 在 Swin Transformer 上也能获得很好的效果。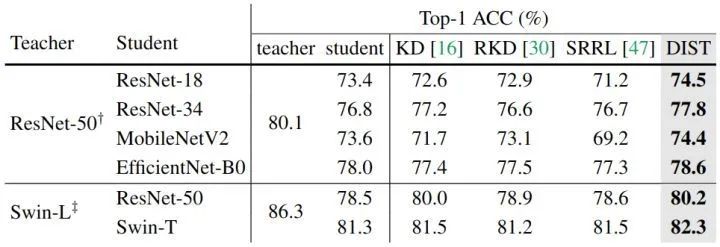 图5:更强的训练策略 ImageNet 实验结果作者使用 MS COCO 数据集,同时将 DIST 作为一种类别的额外的监督信号,ResNeXt-101 主干网络 + Cascade Mask R-CNN 检测头作为教师模型,ResNet-50 主干网络 + Faster R-CNN 检测头作为学生模型;ResNeXt-101 主干网络 + RetinaNet 检测头作为教师模型,ResNet-50 主干网络 + RetinaNet 检测头作为学生模型,结果如下图6所示。DIST 在 COCO 验证集上取得了很有竞争力的结果。为了进行比较,作者在与 DIST 相同的设置下训练原始 KD,通过简单地替换损失函数,显著优于原始 KD 方法。
图5:更强的训练策略 ImageNet 实验结果作者使用 MS COCO 数据集,同时将 DIST 作为一种类别的额外的监督信号,ResNeXt-101 主干网络 + Cascade Mask R-CNN 检测头作为教师模型,ResNet-50 主干网络 + Faster R-CNN 检测头作为学生模型;ResNeXt-101 主干网络 + RetinaNet 检测头作为教师模型,ResNet-50 主干网络 + RetinaNet 检测头作为学生模型,结果如下图6所示。DIST 在 COCO 验证集上取得了很有竞争力的结果。为了进行比较,作者在与 DIST 相同的设置下训练原始 KD,通过简单地替换损失函数,显著优于原始 KD 方法。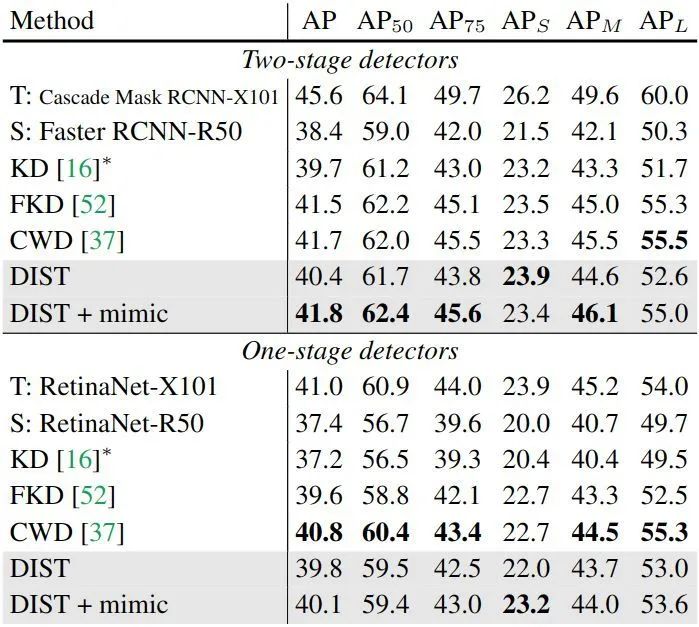 图6:COCO 目标检测实验结果作者还对语义分割这一具有挑战性的密集预测任务进行了实验,在 Cityscape 数据集上用 ResNet-18 骨干模型训练 DeepLabV3 和 PSPNet,对分类头的预测采用 DIST 蒸馏策略,教师模型使用 DeepLabV3 的 ResNet101 骨干模型。结果如下图如表7所示,仅在监督类预测的情况下,DIST 在语义分割任务上明显优于现有的知识蒸馏方法。DIST 比最近最先进的方法 CIRKD 在 PSPNet-R18 上的性能高出 1.58%,证明了 DIST 在关系建模方面的有效性。
图6:COCO 目标检测实验结果作者还对语义分割这一具有挑战性的密集预测任务进行了实验,在 Cityscape 数据集上用 ResNet-18 骨干模型训练 DeepLabV3 和 PSPNet,对分类头的预测采用 DIST 蒸馏策略,教师模型使用 DeepLabV3 的 ResNet101 骨干模型。结果如下图如表7所示,仅在监督类预测的情况下,DIST 在语义分割任务上明显优于现有的知识蒸馏方法。DIST 比最近最先进的方法 CIRKD 在 PSPNet-R18 上的性能高出 1.58%,证明了 DIST 在关系建模方面的有效性。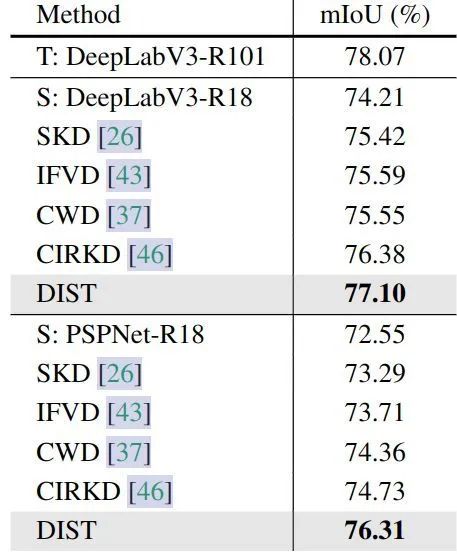 图7:Cityscapes 语义分割实验结果
图7:Cityscapes 语义分割实验结果
本文来源于一个观察,即:当教师模型的体积增大时进行知识蒸馏过程,学生模型的性能提升并不明显;当使用更强的训练策略 (数据增强) 进行知识蒸馏过程,学生模型的性能提升也不明显。这启发作者的思考,可能是知识整理过程中经常使用的 KL 散度,这种精确匹配的模式 (即当且仅当教师和学生的输出完全相同时,损失达到最小值) 就显得过于苛刻。所以作者在本文的直觉是搞一种轻松的方式来匹配老师和学生之间的预测。所以本文提出 DIST,一种包含了类内关系和类间关系的蒸馏方法,在图像识别,目标检测和语义分割任务中均取得了不错的表现。- ^Distilling the Knowledge in a Neural Network
- ^K. Pearson. Vii. mathematical contributions to the theory of evolution.—iii. regression, heredity, and panmixia

扫描二维码添加小助手微信
即可申请加入自然语言处理/Pytorch等技术交流群关于我们
MLNLP 社区是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。