©作者 | 机器之心编辑部
来源 | 机器之心
清华大学计算机系朱军教授带领的 TSAIL 团队提出 DPM-Solver(NeurIPS 2022 Oral,约前 1.7%)和 DPM-Solver++,将扩散模型的快速采样算法提升到了极致:无需额外训练,仅需 10 到 25 步就可以获得极高质量的采样。
要说 AI 领域今年影响力最大的进展,爆火的 AI 作图绝对是其中之一。设计者只需要输入对图片的文字描述,就可以由 AI 生成一张质量极高的高分辨率图片。目前,使用范围最广的当属 StabilityAI 的开源模型 Stable Diffusion,模型一经开源就在社区引起了广泛的讨论。然而,扩散模型在使用上最大的问题就是其极慢的采样速度。模型采样需要从纯噪声图片出发,一步一步不断地去噪,最终得到清晰的图片。在这个过程中,模型必须串行地计算至少 50 到 100 步才可以获得较高质量的图片,这导致生成一张图片需要的时间是其它深度生成模型的 50 到 100 倍,极大地限制了模型的部署和落地。为了加速扩散模型的采样,许多研究者从硬件优化的角度出发,例如 Google 使用 JAX 语言将模型编译运行在 TPU 上,OneFlow 团队 [1] 使用自研编译器将 Stable Diffusion 做到了“一秒出图”。这些方法都基于 50 步的采样算法 PNDM [2],该算法在步数减少时采样效果会急剧下降。就在几天前,这一纪录又被刷新了!Stable Diffusion 的官方 Demo [3] 更新显示,采样 8 张图片的时间从原来的 8 秒钟直接被缩短至了 4 秒钟!快了整整一倍!
而基于自研深度学习编译器技术的 OneFlow 团队更是在不降低采样效果的前提下,成功将之前的 “一秒出图” 缩短到了 “半秒出图”!在 GPU 上仅仅使用不到 0.5 秒就可以获得一张高清的图片!相关工作已经发布在[1] 中。事实上,这些工作的核心驱动力都来自于清华大学朱军教授带领的 TSAIL 团队所提出的 DPM-Solver,一种针对于扩散模型特殊设计的高效求解器:该算法无需任何额外训练,同时适用于离散时间与连续时间的扩散模型,可以在 20 到 25 步内几乎收敛,并且只用 10 到 15 步也能获得非常高质量的采样。在 Stable Diffusion 上,25 步的 DPM-Solver 就可以获得优于 50 步 PNDM 的采样质量,因此采样速度直接翻倍!论文题目:
DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps收录会议:
论文链接:
https://arxiv.org/abs/2206.00927代码链接:
https://github.com/LuChengTHU/dpm-solver
在线demo:
https://huggingface.co/spaces/LuChengTHU/dpmsolver_sdm

DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models论文链接:
https://arxiv.org/abs/2211.01095
扩散模型的定义与采样方法
扩散模型通过定义一个不断加噪声的前向过程来将图片逐步变为高斯噪声,再通过定义了一个逆向过程将高斯噪声逐步去噪变为清晰图片以得到采样:在采样过程中,根据是否添加额外的噪声,可以将扩散模型分为两类:一类是扩散随机微分方程模型(Diffusion SDE),另一类是扩散常微分方程(Diffusion ODE)。两种模型的训练目标函数都一样,通过最小化与噪声的均方误差来训练一个“噪声预测网络”: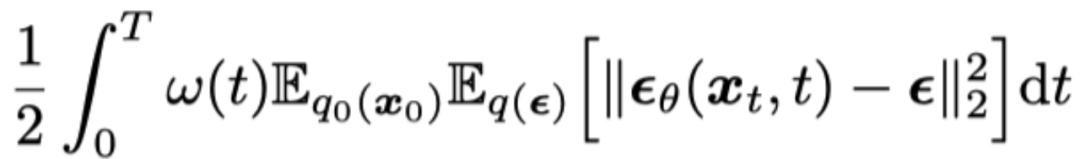
基于 Diffusion SDE 的采样过程可以视为离散化如下随机微分方程: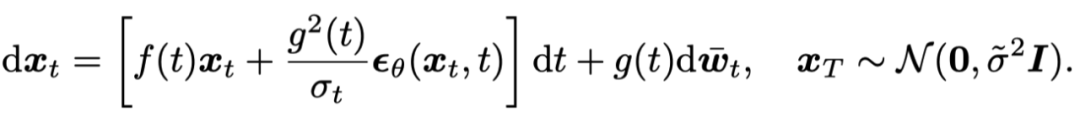
并且 [4] 中证明,DDPM[5] 是对上述 SDE 的一阶离散化。而基于 Diffusion ODE 的采样过程可以视为离散化如下常微分方程:并且 [6] 中证明,DDIM[7]是对上述 ODE 的一阶离散化。然而,这些一阶的离散化方法收敛速度极慢,扩散模型的采样通常需要 100 到 1000 次串行计算才可以得到高质量的图片。通常情况下,为了加速扩散模型的采样,研究者往往通过对 Diffusion ODE 使用高阶求解器来进行加速,例如经典的 Runge-Kutta 方法(RK45),这是因为 ODE 不会带来额外的随机性,离散化步长可以相对选取得更大一些。在给定 s 时刻的解后,Runge-Kutta 方法基于离散化如下积分:这样的离散化将 Diffusion ODE 整体看做一个黑盒,损失了 ODE 的已知信息,在小于 50 步的情况下就难以收敛了。
DPM-Solver:专为扩散模型设计的求解器
DPM-Solver 基于 Diffusion ODE 的半线性(semi-linear)结构,通过精确且解析地计算 ODE 中的线性项,我们可以得到:剩余的积分项是一个关于时间的复杂的积分。然而,DPM-Solver 的提出者发现,该积分可以通过对 log-SNR(对数信噪比)做换元后得到一个非常简单的形式:剩余的积分是一个关于噪声预测模型的指数积分(exponentially weighted integral)。通过对噪声预测模型做泰勒展开,我们可以得到该积分的一个估计:该估计中存在两项:一项是全导数部分(向量),另一项是系数部分(标量)。DPM-Solver 的另一个核心贡献是,该系数可以通过分部积分被解析地计算:而剩余的全导数部分则可以通过传统 ODE 求解器的数值方法来近似估计(无需任何求导运算):基于以上 4 点,DPM-Solver 做到了尽可能地准确计算所有已知项,只对神经网络部分做近似,因此最大程度地减小了离散化误差:此外,基于该推导,我们可以得到 DDIM 本质上是 DPM-Solver 的一阶形式,这也能解释为什么 DDIM 在步数较少时依然可以获得很好的加速效果:在实验中,DPM-Solver 获得了远超其它采样算法的加速效果,仅仅在 15-20 步就几乎可以收敛:并且在论文中定量的结果显示,DPM-Solver 引入的额外计算量完全可以忽略,即对于步数的加速效果直接正比于时间上的加速效果——因此,基于 25 步的 DPM-Solver,Stable-Diffusion 模型的采样速度直接翻倍!例如,下图展示了不同采样算法在 Stable-Diffusion 上随着步数变化的效果,可见 DPM-Solver 在 10 到 15 步就可以获得非常高质量的采样:
使用DPM-Solver
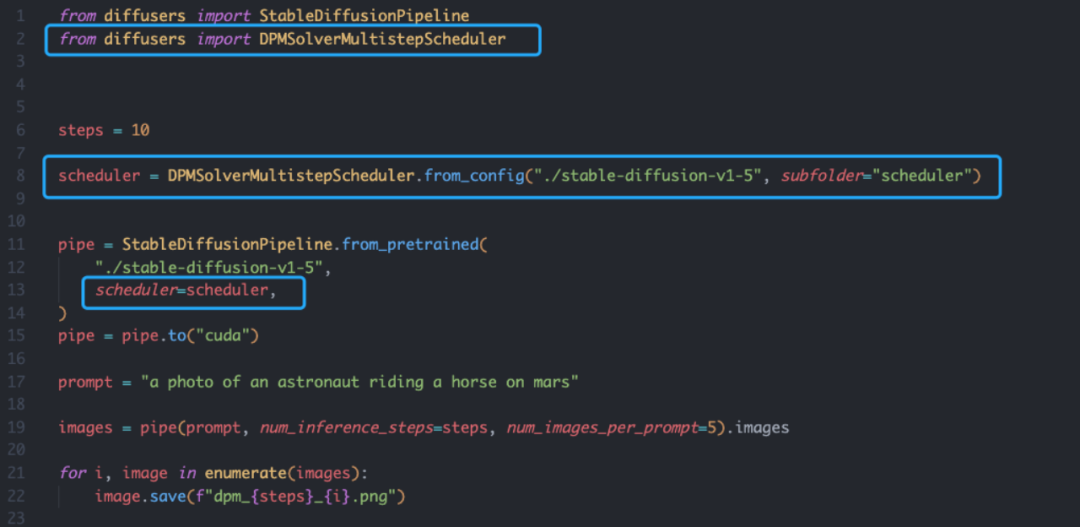
DPM-Solver 的使用非常简单,既可以基于作者提供的官方代码,也可以使用主流的 Diffusers 库。例如,基于作者提供的官方代码,只需要 3 行:https://github.com/LuChengTHU/dpm-solver
官方代码对 4 种扩散模型都进行了支持:
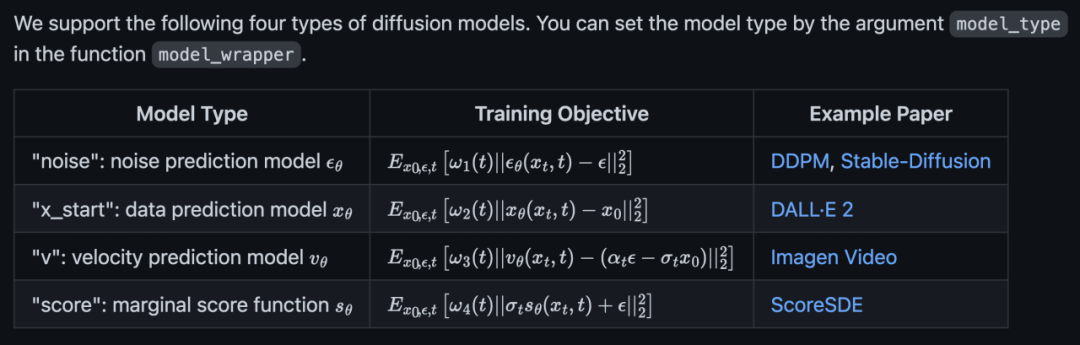
并且同时支持 unconditional sampling、classifier guidance 和 classifier-free guidance:而基于 Diffusers 库的 DPM-Solver 同样很简单,只需要定义 scheduler 即可:
此外,作者团队还提供了一个在线 Demo:
https://huggingface.co/spaces/LuChengTHU/dpmsolver_sdm下图是 15 步的例子,可以看到图像质量已经非常高:相信基于 DPM-Solver,扩散模型的采样速度将不再是瓶颈。DPM-Solver 论文一作是来自清华大学 TSAIL 团队的路橙博士,他在知乎上关于扩散模型的讨论中也写了一篇关于扩散模型原理的入门介绍,目前已有 2000 + 赞:
https://www.zhihu.com/question/536012286/answer/2533146567
清华大学 TSAIL 团队长期致力于贝叶斯机器学习的理论和算法研究,是国际上最早研究深度概率生成模型的团队之一,在贝叶斯模型、高效算法和概率编程库方面取得了系统深入的研究成果。团队另一位博士生鲍凡提出 Analytic-DPM [8][9],为扩散模型的最优均值和方差给出了简单、令人吃惊的解析形式,获得 ICLR 2022 Outstanding Paper Award。
在概率编程方面,机器之心早在 2017 年就报道了该团队发布的 “ZhuSuan” 深度概率编程库 [10],是国际上最早的面向深度概率模型的编程库之一。另外,值得一提的是,扩散概率模型的两位核心作者宋飏和宋佳铭,本科时均在朱军教授的指导下做科研训练,后来都去了斯坦福大学读博士。论文的合作者周聿浩、陈键飞、李崇轩,也是TSAIL组培养的优秀博士生,周聿浩为在读,陈键飞和李崇轩分别在清华大学计算机系、人民大学高瓴人工智能学院任教。
[1] OneFlow 版本的 Stable-Diffusion:https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion[2] Luping Liu et al., 2022, Pseudo Numerical Methods for Diffusion Models on Manifolds, https://arxiv.org/abs/2202.09778[3] Stable-Diffusion 的官方 Demo:https://huggingface.co/spaces/runwayml/stable-diffusion-v1-5[4] Yang Song et al., 2021, Score-Based Generative Modeling through Stochastic Differential Equations, https://arxiv.org/abs/2011.13456[5] Jonathan Ho et al., 2020, Denoising Diffusion Probabilistic Models, https://arxiv.org/abs/2006.11239[6] Tim Salimans & Jonathan Ho, 2022, Progressive Distillation for Fast Sampling of Diffusion Models, https://arxiv.org/abs/2202.00512[7] Jiaming Song et al., 2020, Denoising Diffusion Implicit Models, https://arxiv.org/abs/2010.02502[8] Fan Bao, et al., Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models, https://arxiv.org/abs/2201.06503[9] Fan Bao, et al. Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models, https://arxiv.org/abs/2206.07309v1[10] https://www.jiqizhixin.com/articles/2017-09-20-7

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
