
MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。在图表示学习中,Graph Transformer通过位置编码对图结构信息进行编码,相比GNN,可以捕获长距离依赖,减轻过平滑现象。本文介绍Graph Transformer的两篇近期工作。
[ICML 2022] Structure-Aware Transformer for Graph Representation Learning
本文分析了Transformer的位置编码,认为使用位置编码的Transformer生成的节点表示不一定捕获它们之间的结构相似性。为了解决这个问题,提出了结构感知Transformer,通过设计新的自注意机制,使其能够捕获到结构信息。新的注意力机制通过在计算注意力得分之前,提取每个节点的子图表示,并将结构信息合并到原始的自注意机制中。本文提出了几种自动生成子图表示的方法,并从理论上表明,生成的表示至少与子图表示具有相同的表达能力。该方法在五个图预测基准上达到了最先进的性能,可以利用任何现有的GNN来提取子图表示。它系统地提高了相对于基本GNN模型的性能,成功地结合了GNN和Transformer。
方法
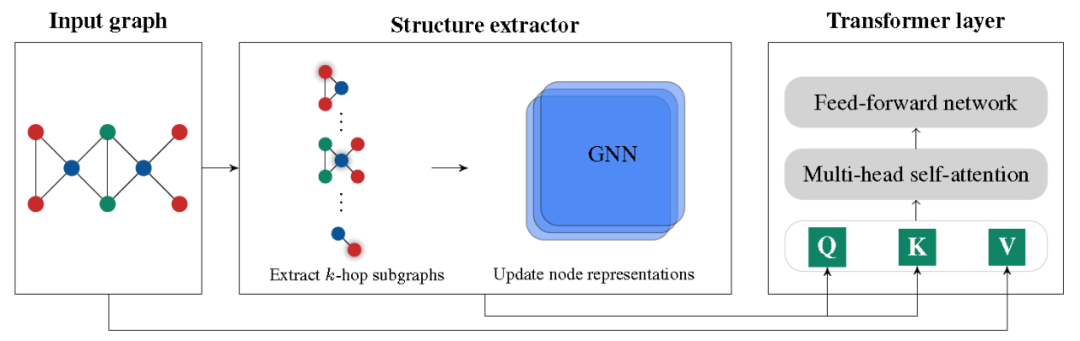
本文提出了一个将图结构编码到注意力机制中的模型。首先,通过Structure extractor抽取节点的子图结构,进行子图结构的注意力计算。其次,遵循Transformer的结构进行计算。
Structure-Aware Self-Attention
Transformer原始结构的注意力机制可以被重写为一个核平滑器:
其中, 是一个线性函数。 是 空间中,由 和 参数化的(非对称)指数核: 是定义在节点特征上的可训练指数核函数,这就带来了一个问题:当节点特征相似时,结构信息无法被识别并编码。为了同时考虑节点之间的结构相似性,我们考虑了一个更一般化的核函数,额外考虑了每个节点周围的局部子结构。通过引入以每个节点为中心的一组子图,定义结构感知注意力如下:其中, 是节点 在图 中的子图,与节点特征 相关, 是可以是任意比较一对子图的核函数。该自注意函数不仅考虑了节点特征的相似度,而且考虑了子图之间的结构相似度。因此,它生成了比原始的自我关注更有表现力的节点表示。定义如下形式的:其中 是一个结构提取器,它提取以 为中心、具有节点特征 的子图的向量表示。结构感知自我注意力十分灵活,可以与任何生成子图表示的模型结合,包括GNN和图核函数。在自注意计算中并不考虑边缘属性,而是将其合并到结构感知节点表示中。文章提出两种生成子图的方法:k-subtree GNN extractor 和 k-subgraph GNN extractor,并进行相关实验。实验
使用GNN抽取结构信息后,再用Transformer学习特征,由下图可以看出,Transformer可以增强GNN的性能。[NIPS 2022] Recipe for a General, Powerful, Scalable Graph Transformer
本文首先总结了不同类型的编码,并对其进行了更清晰的定义,将其分为局部编码、全局编码和相对编码。其次,提出了模块化框架GraphGPS,支持多种类型的编码,在小图和大图中提供效率和可伸缩性。框架由位置/结构编码、局部消息传递机制、全局注意机制三个部分组成。该架构在所有基准测试中显示了极具竞争力的结果,展示了模块化和不同策略组合所获得的经验好处。方法
在相关工作中,位置/结构编码是影响Graph Transformer性能的最重要因素之一。因此,更好地理解和组织位置/结构编码将有助于构建更加模块化的体系结构,并指导未来的研究。本文将位置/结构编码分成三类:局部编码、全局编码和相对编码。各类编码的含义和示例如下表所示。现有的MPNN+Transformer混合模型往往是MPNN层和Transformer层逐层堆叠,由于MPNN固有结构带来的过平滑问题,导致这样的混合模型的性能也会受到影响。因此,本文提出新的混合架构,使MPNN和Transformer的计算相互独立,获得更好的性能。具体框架如图所示。框架主要由位置/结构编码、局部消息传递机制(MPNN)、全局注意机制(Self Attention)三部分组成。根据不同的需求设计位置/结构编码,与输入特征相加,然后分别输入到MPNN和Transformer模型中进行训练,再对两个模型的结果相加,最后经过一个2层MLP将输出结果更好的融合,得到最终的输出。更新公式如下:实验
通过消融实验,研究框架中各个结构的作用,可以看到,MPNN和位置/结构编码模块对Transformer的效果均有提升作用。总结
两篇文章都有一个共同特点,就是采用了GNN+Transformer混合的模型设计,结合二者的优势,以不同的方式对两种模型进行融合,GNN学习到图结构信息,然后在Transformer的计算中起到提供结构信息的作用。在未来的研究工作中,如何设计更加合理的模型,也是一个值得探讨的问题。
扫描二维码添加小助手微信
即可申请加入自然语言处理/Pytorch等技术交流群关于我们
MLNLP 社区是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。