来自:HFL实验室
进NLP群—>加入NLP交流群
哈工大讯飞联合实验室(HFL)开源预训练模型家族迎来首个多模态预训练模型VLE(Vision-Language Encoder)。借助更强的单模型编码器、更细致的预训练目标和更契合下游任务的适配方案,VLE模型不仅具有良好的多模态理解能力,还具备了出色的多模态推理能力,此前荣登VCR评测榜首,相比其他同等规模模型具有显著的优势。此外,借助大型语言模型(LLM)出色的零样本学习能力,本项目设计了一种VQA+LLM方案,将大型语言模型集成到视觉问答任务中,帮助视觉问答模型生成更准确和流畅的答案。目前VLE相关预训练模型、精调模型、源代码等资源已开源,欢迎读者下载使用。

项目地址:https://github.com/iflytek/vle
演示地址:https://huggingface.co/spaces/hfl/VQA_VLE_LLM简介
多模态预训练模型通过在多种模态的大规模数据上的预训练,可以综合利用来自不同模态的信息,执行各种跨模态任务。本项目提出图像-文本多模态预训练模型VLE(Vision-Language Encoder),可应用于如视觉问答、图像-文本检索等多模态判别式任务。特别地,VLE在对语言理解和推理能力有更强要求的视觉常识推理(VCR)任务中取得了公开模型中的最佳效果。VLE模型采用双流结构,与METER模型结构类似,由两个单模态编码器(图像编码器和文本编码器)和一个跨模态融合模块构成。文本编码器初始化采用了DeBERTa-v3,图像编码器初始化采用了CLIP-ViT。输入的图片和文本分别经过图像编码器和文本编码器进行编码,送入跨模态融合模块进行信息交互,再经由任务特定的预测模块得到最终输出。VLE使用图文对数据进行预训练。在预训练阶段,VLE采用了四个预训练任务:- MLM (Masked Language Modeling):掩码预测任务。给定图文对,随机遮掩文本中的部分单词,训练模型还原遮掩的文本。
- ITM (Image-Text Matching):图文匹配预测任务。训练模型判断图像和文本是否匹配。
- MPC (Masked Patch-box Classification):遮掩Patch分类任务,给定图文对,并遮掩掉图片中包含具体对象的patch,训练模型预测对象种类。
- PBC (Patch-box Classification):Patch分类任务。给定图文对,预测图片中的哪些patch与文本描述相关。
这些预训练任务各有侧重:MLM任务提升模型的语言理解能力;ITM和MPC任务提升模型的图文交互能力;PBC任务提升模型的精确定位能力。下图展示了模型的结构和部分预训练任务(MLM、ITM和MPC)的流程。本项目将VLE应用于视觉问答(VQA)和视觉常识推理(VCR)两个多模态任务。对于VCR任务,我们采用了基于目标信息的图文对齐增强机制,并扩展了token_type_ids,为图片和文本中的对象添加了对象表示嵌入,实现“物”与“名”的对应。效果对比
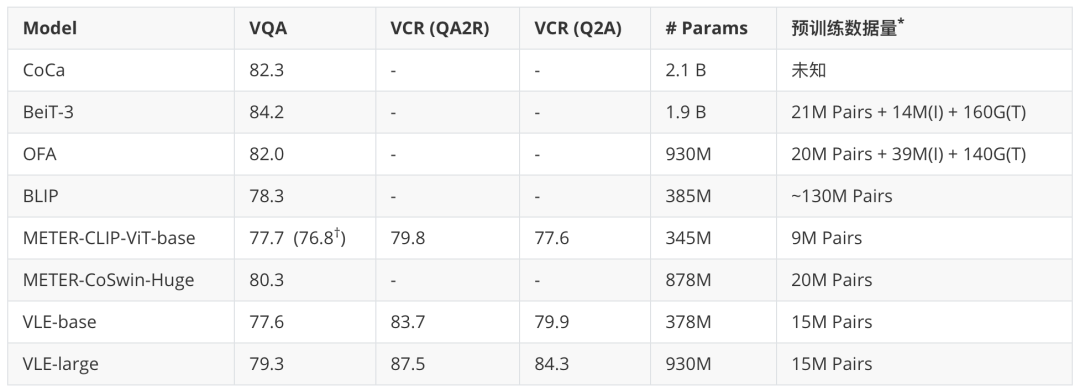
下表中对比了VLE、METER以及其他多模态模型的参数量、预训练数据和下游任务效果。其中VQA任务展示的的是test-dev集效果,VCR任务展示的是dev集效果。通过观察实验结果可以发现,- VLE的预训练更高效:与大小相近的模型相比,VLE使用了更少的预训练数据,并在视觉问答上取得了相当的效果。
- VLE有更强的推理能力:在对推理能力要求更高的视觉常识推理VCR任务上,VLE显著地超过了具有相似结构的METER。
†:复现效果
* :Pairs: 图文对数量;I:图片数据数量;T:文本数据大小VQA+LLM:结合大模型的视觉问答
近期,随着指令微调、RLHF等技术的发展,LLM在多种文本任务中取得了显著性能提升。虽然大多数LLM是单模态模型,但它们的能力也可用于辅助多模态理解任务。具体而言,本项目提出了一种VQA + LLM方案,将多模态模型与LLM集成到视觉问答任务中,从而帮助VQA模型生成更准确和流畅的答案。下图展示了系统流程。
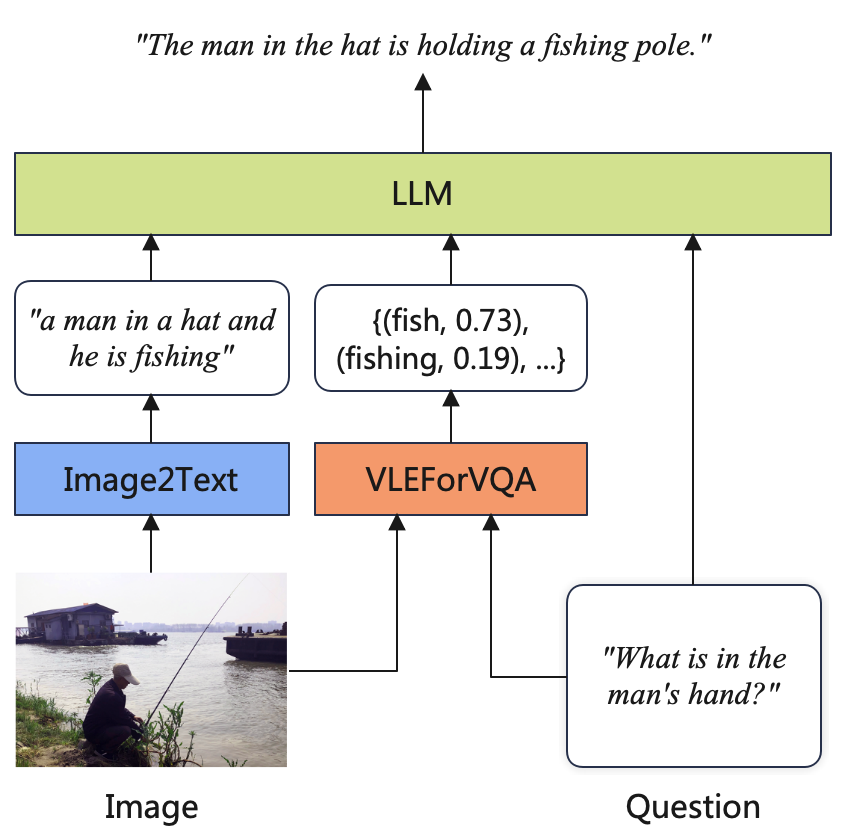
首先,本项目利用captioning模型生成图片的描述,然后将图片描述、问题以及VQA模型的预测结果进行拼接,构造合适的prompt送入LLM,最后要求LLM模型回复最合理的答案。下面给出了两组示例,不难看出VQA+LLM生成的答案更准确并且具有更好的可读性。读者可通过以下链接体验视觉问答Demo。视觉问答Demo:https://huggingface.co/spaces/hfl/VQA_VLE_LLM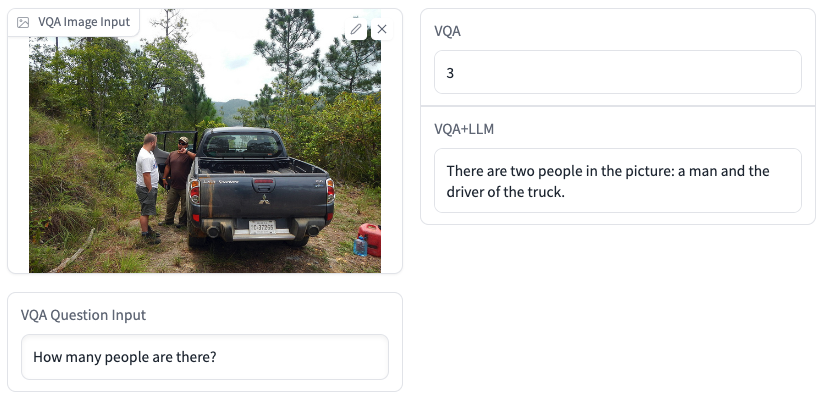
模型下载与使用
目前,本项目发布了VLE-base和VLE-large两个版本的预训练模型,还公开了VQA和VCR两个任务上的精调模型。请访问以下🤗transformers模型库页面获取更多详细信息,并了解更多HFL开源预训练模型。https://huggingface.co/HFL模型的具体使用方式和更详细的技术内容,请访问本项目GitHub地址。https://github.com/iflytek/vle