近日,中国科学院自动化研究所的研究人员杜长德等人开发了一种「脑 - 图 - 文 」多模态学习模型,可以无创地解码大脑活动的语义信息。新方法不仅揭示了视觉 - 语言的多模态信息加工机理,也实现了大脑信号的零样本语义解码。论文发表在人工智能顶级期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI 2023)。

论文地址:https://ieeexplore.ieee.org/document/10089190
代码地址:https://github.com/ChangdeDu/BraVL
数据地址:https://figshare.com/articles/dataset/BraVL/17024591
这项研究首次将大脑、视觉和语言知识相结合,通过多模态学习的方式,实现了从人类脑活动记录中零样本地解码视觉新类别。本文还贡献了三个「脑 - 图 - 文」三模态匹配数据集。实验结果表明了一些有趣的结论和认知洞见:1)从人类脑活动中解码新的视觉类别是可以实现的,并且精度较高;2)使用视觉和语言特征的组合的解码模型比仅使用其中之一的模型表现更好;3)视觉感知可能伴随着语言影响来表示视觉刺激的语义。这些发现不仅对人类视觉系统的理解有所启示,而且也为将来的脑机接口技术提供了新的思路。本研究的代码和数据集均已开源。解码人类视觉神经表征是一个具有重要科学意义的挑战,可以揭示视觉处理机制并促进脑科学与人工智能的发展。然而,目前的神经解码方法难以泛化到训练数据以外的新类别上,主要原因有两个:一是现有方法未充分利用神经数据背后的多模态语义知识,二是现有的可利用的配对(刺激 - 脑响应)训练数据很少。研究表明,人类对视觉刺激的感知和识别受到视觉特征和人们先前经验的影响。例如当我们看到一个熟悉的物体时,我们的大脑会自然而然地检索与该物体相关的知识。如下图 1 所示,认知神经科学对双重编码理论 [9] 的研究认为,具体概念在大脑中既以视觉方式又以语言方式进行编码,其中语言作为有效的先验经验,有助于塑造由视觉生成的表征。因此,作者认为想要更好地解码记录到的脑信号,不仅应该使用实际呈现的视觉语义特征,还应该包括与该视觉目标对象相关的更丰富的语言语义特征的组合来进行解码。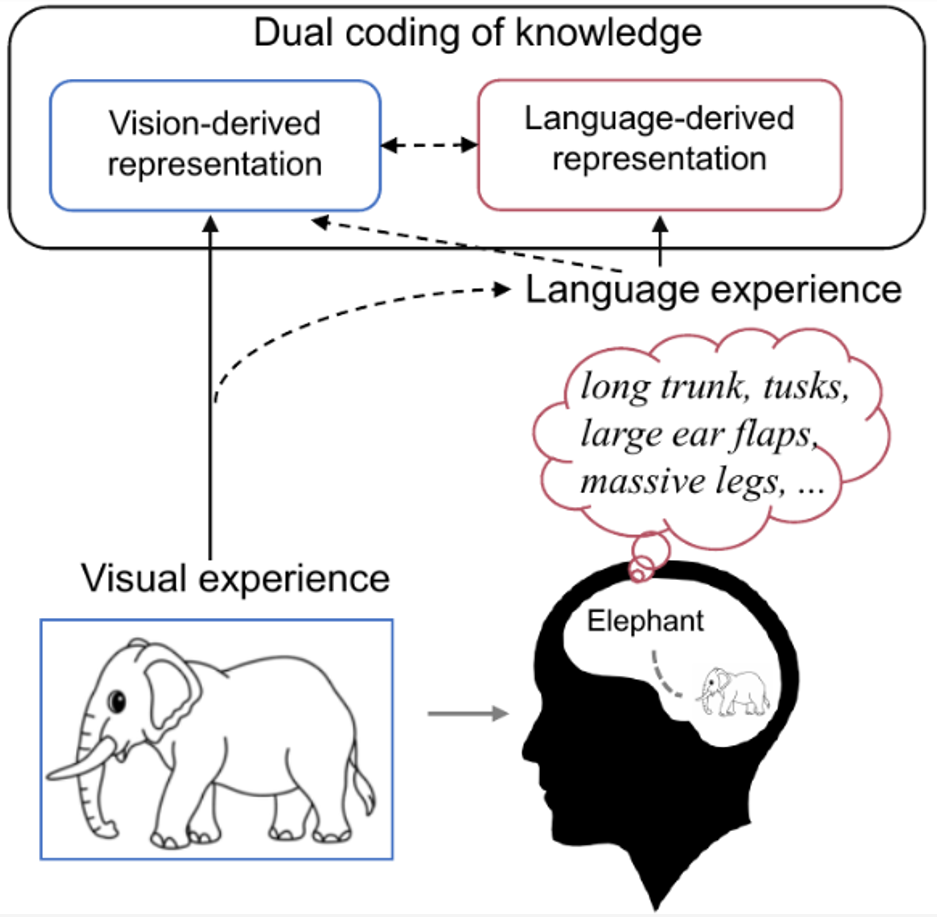 图 1. 人类大脑中的知识双重编码。当我们看到大象的图片时,会自然地在脑海中检索到大象的相关知识(如长长的鼻子、长长的牙齿、大大耳朵等)。此时,大象的概念会在大脑中以视觉和语言的形式进行编码,其中语言作为一种有效的先前经验,有助于塑造由视觉产生的表征。
图 1. 人类大脑中的知识双重编码。当我们看到大象的图片时,会自然地在脑海中检索到大象的相关知识(如长长的鼻子、长长的牙齿、大大耳朵等)。此时,大象的概念会在大脑中以视觉和语言的形式进行编码,其中语言作为一种有效的先前经验,有助于塑造由视觉产生的表征。
如下图 2 所示,由于收集各种视觉类别的人脑活动非常昂贵,通常研究者只有非常有限的视觉类别的脑活动。然而,图像和文本数据却非常丰富,它们也可以提供额外的有用信息。本文的方法可以充分利用所有类型的数据(三模态、双模态和单模态)来提高神经解码的泛化能力。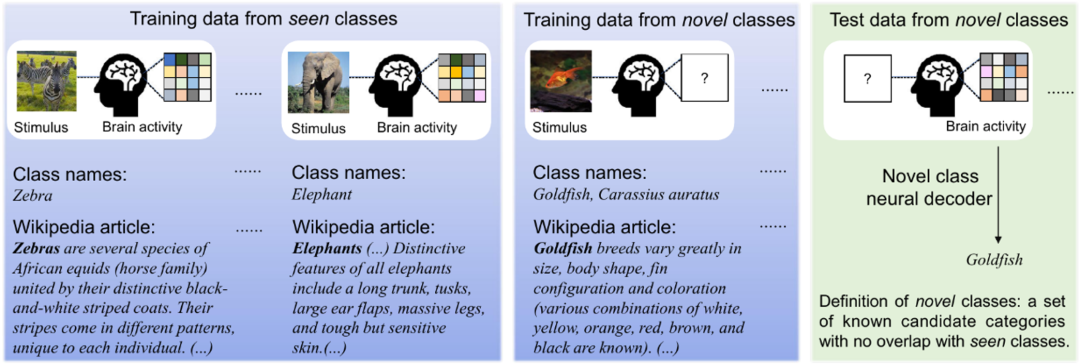 图 2. 图像刺激、引发的大脑活动以及它们相应的文本数据。我们只能为少数类别收集大脑活动数据,但是可以很容易地收集几乎所有类别的图像和 / 或文本数据。因此,对于已知类别,我们假设大脑活动、视觉图像和相应的文本描述都可用于训练,而对于新类别,仅视觉图像和文本描述可用于训练。测试数据是来自新类别的大脑活动数据。
图 2. 图像刺激、引发的大脑活动以及它们相应的文本数据。我们只能为少数类别收集大脑活动数据,但是可以很容易地收集几乎所有类别的图像和 / 或文本数据。因此,对于已知类别,我们假设大脑活动、视觉图像和相应的文本描述都可用于训练,而对于新类别,仅视觉图像和文本描述可用于训练。测试数据是来自新类别的大脑活动数据。
如下图 3A 所示,本文方法的关键在于将每种模态学习到的分布对齐到一个共享的潜在空间中,该空间包含与新类别相关的基本多模态信息。具体地说,作者提出了一种多模态自编码变分贝叶斯学习框架,其中使用了专家混合相乘模型(Mixture-of-Products-of-Experts,MoPoE),推断出一种潜在编码,以实现所有三种模态的联合生成。为了学习更相关的联合表示,并在脑活动数据有限的情况下提高数据效率,作者还进一步引入了模态内和模态间的互信息正则化项。此外,BraVL 模型可以在各种半监督学习场景下进行训练,以纳入额外的大规模图像类别的视觉和文本特征。在图 3B 中,作者从新类别的视觉和文本特征的潜在表示中训练 SVM 分类器。需要注意的是,在这一步中编码器 E_v 和 E_t 被冻结,只有 SVM 分类器(灰色模块)会被优化。在应用中,如图 3C 所示,本文方法的输入仅为新类别脑信号,不需要其他数据,因此可以轻松应用于大多数神经解码场景。SVM 分类器之所以能够从(B)推广到(C),是因为这三种模态的潜在表示已经在 A 中对齐。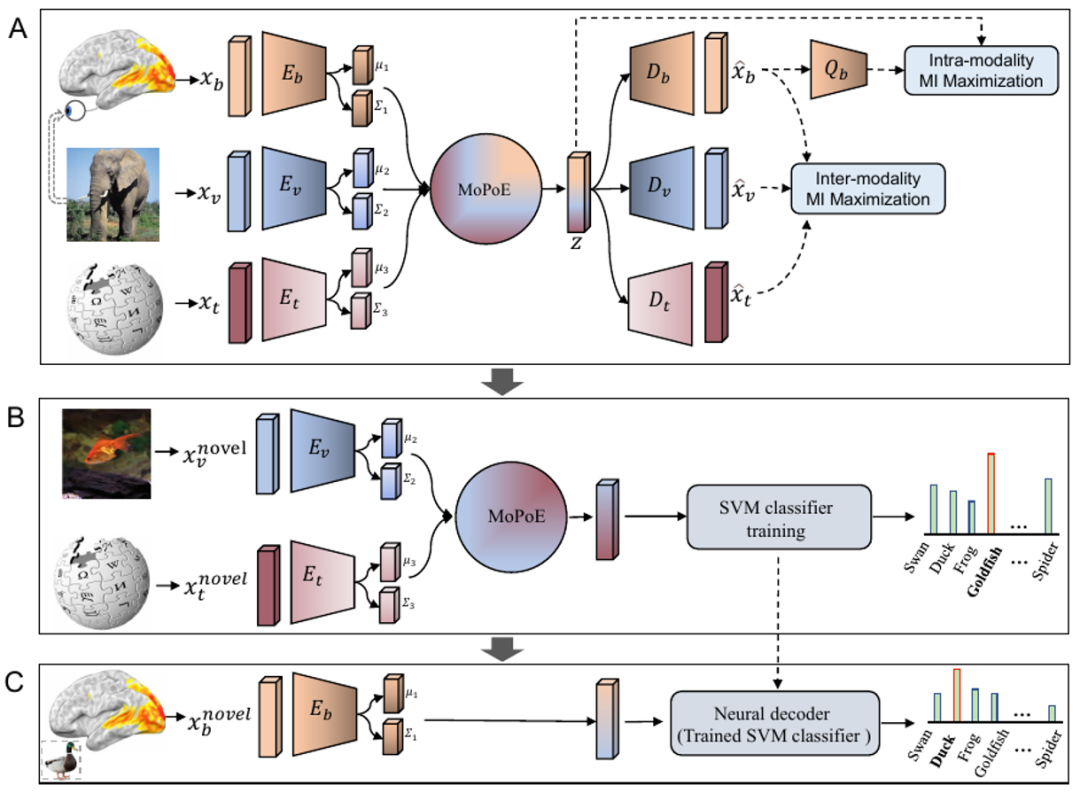 图 3 本文提出的 “脑 - 图 - 文” 三模态联合学习框架,简称 BraVL。
图 3 本文提出的 “脑 - 图 - 文” 三模态联合学习框架,简称 BraVL。
此外,脑信号会因试次(trial)的不同而发生变化,即使是相同的视觉刺激也是如此。为了提高神经解码的稳定性,作者使用了稳定性选择方法来处理 fMRI 数据。所有体素的稳定性分数如下图 4 所示,作者选取稳定性最好的前 15% 体素参与神经解码过程。这种操作可以有效地降低 fMRI 数据的维度,并抑制噪声体素引起的干扰,而不会严重影响脑特征的判别能力。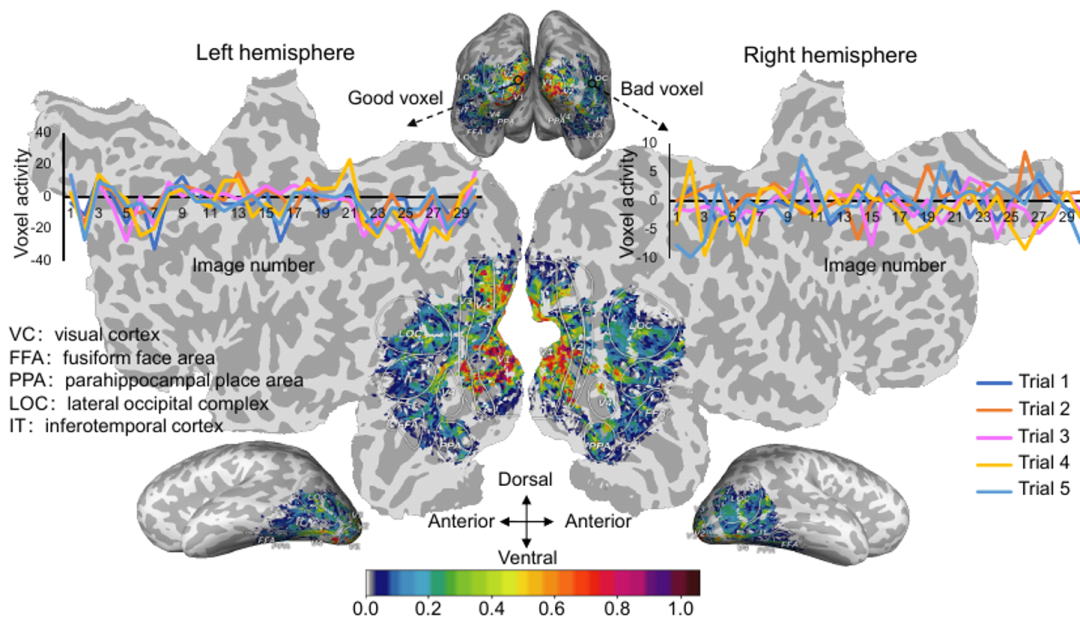 图 4. 大脑视觉皮层的体素活动稳定性分数映射图。
图 4. 大脑视觉皮层的体素活动稳定性分数映射图。
现有的神经编解码数据集往往只有图像刺激和脑响应。为了获取视觉概念对应的语言描述,作者采用了一种半自动的维基百科文章抽取方法。具体来说,作者首先创建 ImageNet 类与其对应的维基百科页面的自动匹配,匹配是基于 ImageNet 类和维基百科标题的同义词集单词之间的相似性,以及它们的父类别。如下图 5 所示,遗憾的是,这种匹配偶尔会产生假阳性,因为名称相似的类可能表示非常不同的概念。在构建三模态数据集时,为了确保视觉特征和语言特征之间的高质量匹配,作者手动删除了不匹配的文章。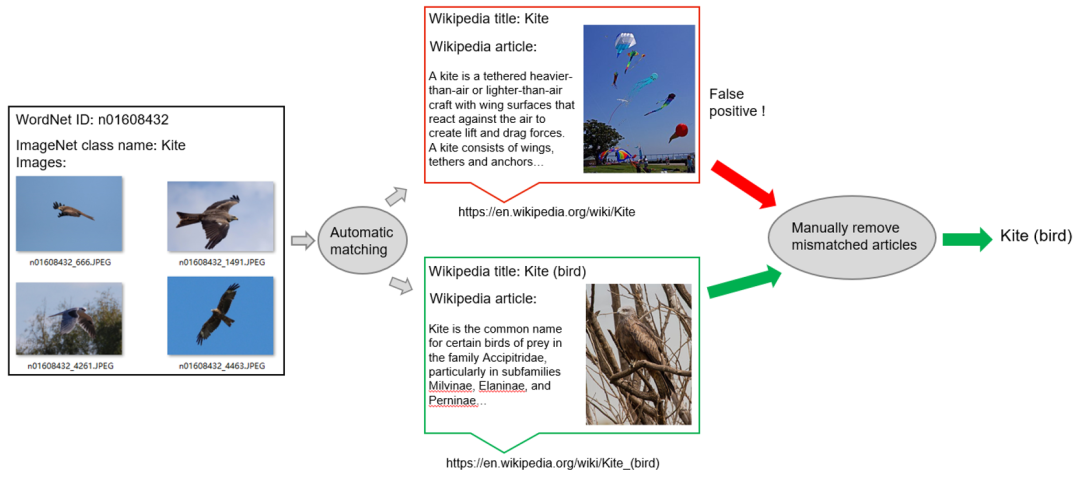 图 5. 半自动视觉概念描述获取
图 5. 半自动视觉概念描述获取
作者在多个「脑 - 图 - 文」三模态匹配数据集上进行了广泛的零样本神经解码实验,实验结果如下表所示。可以看到,使用视觉和文本特征组合 (V&T) 的模型比单独使用它们中的任何一种的模型表现得要好得多。值得注意的是,基于 V&T 特征的 BraVL 在两个数据集上的平均 top-5 准确率都有显著提高。这些结果表明,尽管呈现给被试的刺激只包含视觉信息,但可以想象,被试会下意识地调用适当的语言表征,从而影响视觉处理。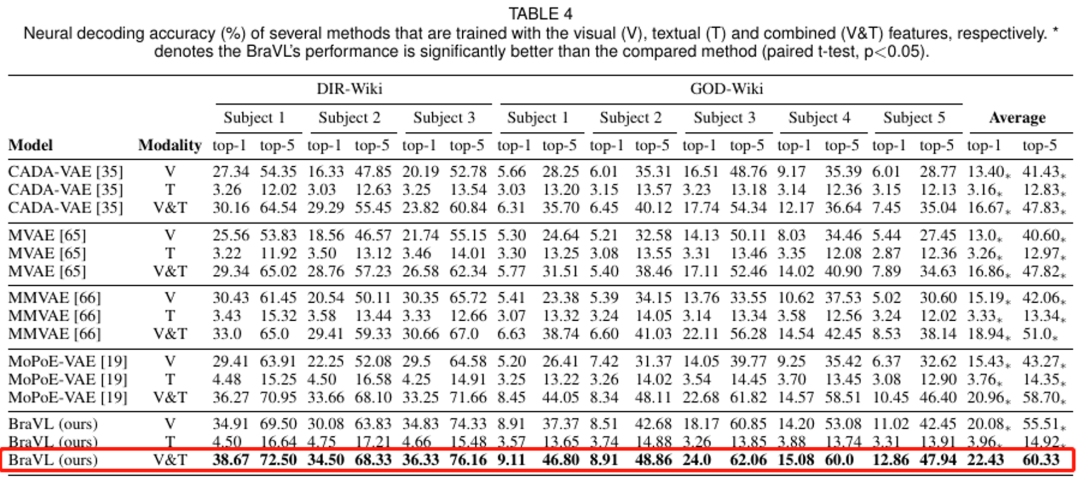
对于每个视觉概念类别,作者还展示了加入文本特征后的神经解码准确率增益,如下图 6 所示。可以看到,对于大多数测试类,文本特征的加入都有积极的影响,平均 Top-1 解码精度提高了约 6%。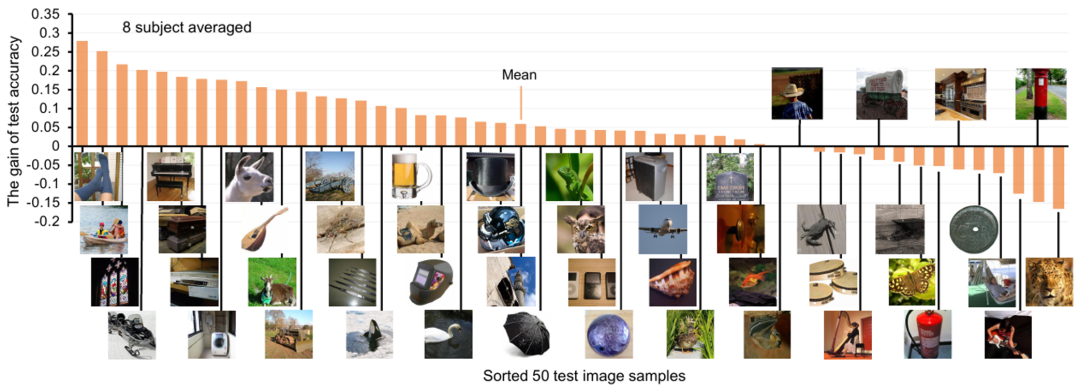 图 6. 加入文本特征后的神经解码准确率增益
图 6. 加入文本特征后的神经解码准确率增益
除了神经解码分析,作者还分析了文本特征在体素级神经编码方面的贡献 (基于视觉或文本特征预测相应的脑体素活动),结果如图 7 所示。可见,对于大多数高级视觉皮层 (HVC,如 FFA, LOC 和 IT),在视觉特征的基础上融合文本特征可以提高大脑活动的预测精度,而对于大多数低级视觉皮层 (LVC,如 V1, V2 和 V3),融合文本特征是没有好处的,甚至是有害的。从认知神经科学的角度来看,我们的结果是合理的,因为一般认为 HVC 负责处理物体的类别信息、运动信息等更高层次的语义信息,而 LVC 负责处理方向、轮廓等底层信息。此外,最近的一项神经科学研究发现,视觉和语言语义表示在人类视觉皮层的边界上对齐 (即「语义对齐假说」)[10],作者的实验结果也支持这一假说。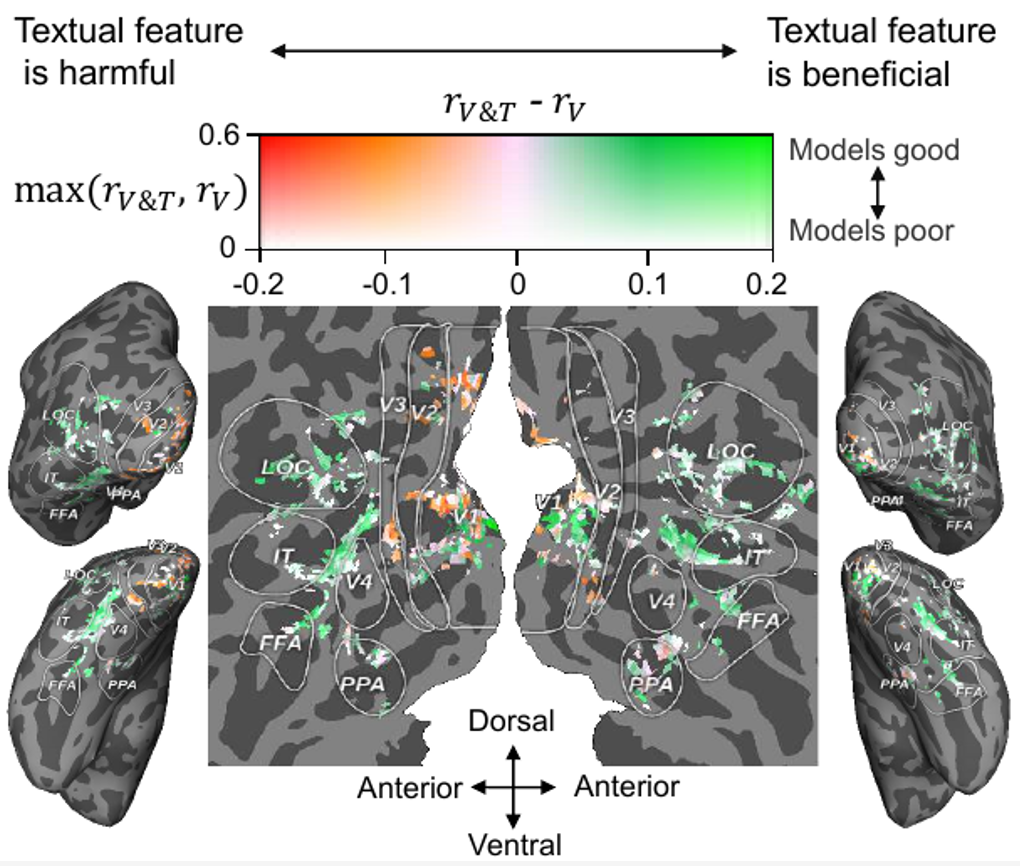 图 7. 将文本特征贡献投影到视觉皮层
图 7. 将文本特征贡献投影到视觉皮层
总体上,本文得出了一些有趣的结论和认知洞见:1)从人类脑活动中解码新的视觉类别是可以实现的,并且精度较高;2)使用视觉和语言特征组合的解码模型比单独使用两者中的任何一种的解码模型的性能要好得多;3)视觉感知可能伴随着语言影响来表示视觉刺激的语义;4) 使用自然语言作为概念描述比使用类名具有更高的神经解码性能;5) 单模态和双模态的额外数据均能显著提高解码精度。论文第一作者、中科院自动化所特别研究助理杜长德表示:「此工作证实了从大脑活动、视觉图像和文本描述中提取的特征对于解码神经信号是有效的。然而,提取的视觉特征可能无法准确反映人类视觉处理的所有阶段,更好的特征集将有助于这些任务的完成。例如,可以使用更大的预训练语言模型(如 GPT-3),来提取更具有零样本泛化能力的文本特征。此外,尽管维基百科文章包含丰富的视觉信息,但这些信息很容易被大量的非视觉句子所掩盖。通过视觉句子提取或者使用 ChatGPT 和 GPT-4 等模型收集更准确和丰富的视觉描述可以解决这个问题。最后,与相关研究相比,虽然本研究使用了相对较多的三模态数据,但更大更多样化的数据集会更有益。这些方面我们留待未来的研究。」论文通讯作者、中科院自动化所何晖光研究员指出:「本文提出的方法有三个潜在的应用:1)作为一种神经语义解码工具,此方法将在新型读取人脑语义信息的神经假肢设备的开发中发挥重要作用。虽然这种应用还不成熟,但本文的方法为其提供了技术基础。2)通过跨模态推断脑活动,本文方法还可以用作神经编码工具,用于研究视觉和语言特征如何在人类大脑皮层上表达,揭示哪些脑区具有多模态属性(即对视觉和语言特征敏感)。3)AI 模型内部表征的神经可解码性可以被视为该模型的类脑水平指标。因此,本文的方法也可以用作类脑特性评估工具,测试哪个模型的(视觉或语言)表征更接近于人类脑活动,从而激励研究人员设计更类脑的计算模型。」神经信息编解码是脑机接口领域的核心问题,也是探索人脑复杂功能背后的原理从而促进类脑智能发展的有效途径。自动化所神经计算与脑机交互研究团队已在该领域持续深耕多年,做出了一系列研究工作,发表在 TPAMI 2023、TMI2023、TNNLS 2022/2019、TMM 2021、Info. Fusion 2021, AAAI 2020 等。前期工作被 MIT Technology Review 头条报道,并获得 ICME 2019 Best Paper Runner-up Award。 该研究得到了科技创新 2030—“新一代人工智能” 重大项目、基金委项目、自动化所 2035 项目以及中国人工智能学会 - 华为 MindSpore 学术奖励基金及智能基座等项目的支持。第一作者:杜长德,中科院自动化所特别研究助理,从事脑认知与人工智能方面的研究,在视觉神经信息编解码、多模态神经计算等方面发表论文 40 余篇,包括 TPAMI/TNNLS/AAAI/KDD/ACMMM 等。曾获得 2019 年 IEEE ICME Best Paper Runner-up Award、2021 年 AI 华人新星百强。先后承担科技部、基金委、中科院的多项科研任务,研究成果被 MIT Technology Review 头条报道。
个人主页:https://changdedu.github.io/ 通讯作者:何晖光,中科院自动化所研究员,博导,中国科学院大学岗位教授,上海科技大学特聘教授,中科院青促会优秀会员,建国七十周年纪念章获得者。先后承担 7 项国家自然基金(含基金重点和国际合作重点)、2 项 863、国家重点研究计划课题等项目。曾获得国家科技进步二等奖两项(分别排名第二、第三)、北京市科技进步奖两项、教育部科技进步一等奖、中科院首届优秀博士论文奖、北京市科技新星、中科院 “卢嘉锡青年人才奖”、福建省 “闽江学者” 讲座教授。其研究领域为人工智能、脑 - 机接口、医学影像分析等。近五年来,在 IEEE TPAMI/TNNLS、ICML 等期刊和会议上发表文章 80 余篇。他是 IEEEE TCDS、《自动化学报》等期刊编委,CCF 杰出会员,CSIG 杰出会员。
[1]. Changde Du, Kaicheng Fu, Jinpeng Li, Huiguang He*. Decoding Visual Neural Representations by Multimodal Learning of Brain-Visual-Linguistic Features. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2023)[2]. Zhongyu Huang, Changde Du, Yingheng Wang, Kaicheng Fu, Huiguang He. Graph-Enhanced Emotion Neural Decoding. IEEE Transactions on Medical Imaging (TMI 2023)[3]. Changde Du, Changying Du, Lijie Huang, Haibao Wang, Huiguang He*. Structured Neural Decoding With Multitask Transfer Learning of Deep Neural Network Representations. IEEE Trans. Neural Netw. Learn. Syst (TNNLS 2022).[4]. Kaicheng Fu, Changde Du, Shengpei Wang, Huiguang He. Multi-view Multi-label Fine-grained Emotion Decoding from Human Brain Activity. IEEE Trans. Neural Netw. Learn. Syst (TNNLS 2022) [5]. Changde Du, Changying Du, Huiguang He*. Multimodal Deep Generative Adversarial Models for Scalable Doubly Semi-supervised Learning. Information Fusion 2021.[6]. Dan Li, Changde Du, Haibao Wang, Qiongyi Zhou, Huiguang He. Deep Modality Assistance Co-Training Network for Semi-Supervised Multi-Label Semantic Decoding. IEEE Transactions on Multimedia (TMM 2021).[7]. Changde Du, Changying Du, Lijie Huang, Huiguang He*. Conditional Generative Neural Decoding with Structured CNN Feature Prediction. In AAAI 2020 [8]. Changde Du, Changying Du, Lijie Huang, Huiguang He*. Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multiview Learning. IEEE Trans. Neural Netw. Learn. Syst (TNNLS 2019).[9] Y. Bi, “Dual coding of knowledge in the human brain,” Trends Cogn. Sci., vol.25, no.10, pp.883–895, 2021[10] S. F. Popham, A. G. Huth et al., “Visual and linguistic semantic representations are aligned at the border of human visual cortex,” Nat. Neurosci., vol. 24, no. 11, pp. 1628–1636, 2021.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]