
©PaperWeekly 原创 · 作者 | 张三岁

论文标题:
S2GAE: Self-Supervised Graph Autoencoders Are Generalizable Learners with Graph Masking
https://dl.acm.org/doi/pdf/10.1145/3539597.3570404
WSDM 2023
Background
自监督学习(SSL Self-supervised learning)已经在自然语言处理(NLP)和计算机视觉(CV)领域进行了广泛研究,用来提高模型的通用性。最近,越来越多的研究也致力于探索在图(graph)上的自监督学习(SSL),以提高学习到的图(graph)模型对各种图分析任务的适用性,例如链路预测(link prediction)、节点分类(node classification)和图分类(graph classification)任务。在这些工作中,图自编码器(GAE graph autoencoder)是一种典型的生成式图自监督学习(generative SSL)方法,它通过数据重构表现出较好的节点表征(node representation)学习能力。GAE 通常采用图神经网络 GNNs(graph neural networks)作为编码器(encoder),通过重构边(edge)或节点属性(node attribute)来训练模型。近年来,许多 GAE 模型被提出,但这些 GAE 工作仅在链路预测(link prediction)任务上表现较好,在节点分类和图分类的任务上则表现较差。这主要是因为传统的 GAE 过于强调重构边或节点属性的相似性(proximity information),而忽略了结构信息(structural information)。
Motivation
如 Background 所述,目前还没有任何 GAE 模型能够在链路预测、节点分类和图分类任务中都表现出色,即与当前图自监督学习下的最佳方法——图对比学习(GCL graph contrastive learning)模型相当(笔者注:图对比学习 GCL 是目前图自监督学习 SSL 下的 SOTA 方法)。这使得这篇文章对于 GAE 的通用性产生了研究兴趣。这篇文章的研究主要围绕以下两个问题展开:1. 为什么传统的 GAE 在图分类任务上表现差强人意?2. 该如何构建一个通用的(generalizable)GAE框架,使其在链路预测、节点分类和图分类任务上都表现出色?
Challenge
为了解决 Motivation 中的研究问题,这篇文章首先分析了传统的GAE在图分类任务上表现不佳的三个原因,具体如下:1. 传统 GAE 框架过度强调图的拓扑结构(topology structure):大多数现有的 GAE 模型侧重于准确地重构输入图的拓扑结构(topology structure),即所有成对的(pair-wise)连接(connection)关系,以保持邻居节点之间的拓扑相似性(topological closeness)。然而,这种侧重对于捕捉节点间的结构信息(structure information)是有害的,尤其是在包含冗余和噪声信息的真实世界的(real-world)图上。
笔者注:拓扑结构(topology structure)和结构信息(structure information)是不同的,前者强调成对的连接(pair-wise connection)即一对一,后者强调有用的邻居节点结构信息即一对多
2. 传统 GAE 框架中重构图的设计容易出现过拟合的现象:传统 GAE 通常采用先进的神经网络模型(如 GNN)作为编码器(encoder),来学习节点的表征(node representation)。但由于要重构的目标边在 GNN 编码器中也会被用于学习节点表征,因此编码器学到的节点表征天然的带有相似性。在解码器中,如果利用这本就带有相似性的节点表征,再次计算两两节点间的相似性,从而重建整张图的结构。这样的重构图的设计容易使 GAE 陷入过拟合。
3. 传统 GAE 框架中解码器架构(decoder architecture)对于边的重建表现较差,尤其是在边受到扰动(edge perturbation)的情况下:传统 GAE 通常使用多层感知器(MLPs multi-layer perceptrons)作为解码器,从而根据节点表征计算节点间的相似性。通常来说,基于 MLP 的解码器可能足以对节点之间的关联性进行建模。然而,一旦图的结构被破坏,GNN 编码器将不可避免地受到影响,从而生成有噪声的(noisy)节点表示。在这种情况下,仅依靠 MLP 作为解码器是无法有效地重构边。Method
在上述 Challenge 的启发下,这篇文章提出了一个通用的图表示学习框架,称为自监督图自动编码器 S2GAE(Self-Supervised Graph Autoencoders)。简单来说,S2GAE 的工作原理是随机掩盖(mask)一部分图结构(graph structure),然后利用未掩盖的(unmasked)图结构来学习重建这些被掩盖的边(edge)。图 1 描述了 S2GAE 的整体架构。具体而言,S2GAE 主要包含以下四个部分。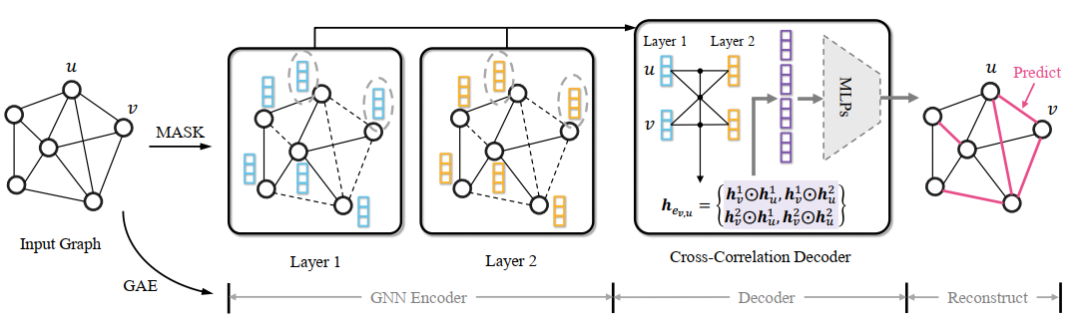
3.1 Perturbed Graph Input给定一个图 ,标准的 GAE 将完整的图 输入编码器,学习得到节点表征(node representation),并根据编码表征(encoded representation)的相似性来重构输入的网络结构 。然而,如 Challenge 所述,这样的设计可能会过度强调邻居节点间的相似性而忽略了结构信息,从而导致在分类任务上的表现较差。为了解决这个问题,这篇文章提出对输入图结构进行扰动,并仅利用其中的一部分作为编码器的输入。具体来说,本文采用随机丢弃的方式(即图掩盖)来扰动输入图。即从边集 中随机抽取一定比例 的子集 ,得到扰动后的输入图 ,如公式 1 所示。在实践中,通常采用不放回的随机均匀抽样(概率为 )来生成 。这主要是因为基于均匀分布的抽样可以防止潜在的中心偏差,即被掩盖的边集全由有影响力的节点(influential node)组成。这种方法将节点视为像素且把边看作是单向的,就像在计算机视觉领域中所做的那样。对于图像(image)数据来说,这种实现方式是合理的,因为它们是密集的、类似网格的数据。然而,对于现实世界的图(graph)而言,它是次优的,因为图通常很稀疏(sparse)。因此,在遮盖边时,需要考虑到图本身的特性(characteristic)。基于此,本文提出了两个有方向感知的(direction-aware)图掩盖策略(graph masking strategy)。
无向掩盖 UM(Undirected masking):将节点 和 之间的连接(link)看作是无向的(undirected),即 和 被认为是相同的且在 中只存在一份。因此,在对 进行随机抽样后,所产生的 和 也是无向的。有向掩盖 DM(Directed masking):将图中的连接(link)看作是有向的(即使是无向图),即 和 被认为是不同的且都被存在 中。删除 并不意味着 也被删除。因此,在对 进行随机抽样后,所产生的 和 也是有向的。虽然在概念上很简单,但在实验中,上述两种图掩盖策略都表现出色。具体来说,最佳的图掩盖策略与图本身及其下游任务有关。如果图的网络结构很密集或者已具有冗余信息(如社交网络),那么最好采用更强硬的策略——无向掩盖。相反,如果原始图网络结构是稀疏的,那么有向掩盖可能是一个更好的选择。3.2 GNN Encoder
为了有效地将节点映射到表征(representation)中,GNNs 经常被用作编码器(encoder)。GNN 通过利用节点自身及其相邻节点的表征来更新其表征。与传统 GAE 不同,S2GAE 将扰动后的图 作为 GNN 编码器的输入,因此从编码器得到的节点表征 将会不可避免地包含噪声,特别是当 较大时。为解决这个问题并提高解码器的重构能力,这篇文章开发了一个互相关解码器(cross-correlation decoder)。3.3 Cross-Correlation Decoder
给定一条边 及其从编码器得到的表征 ,现有的 GAE 通常将解码器定义为它们表征的内积(即 )或建立在它们表征串联(concatenation)上的 MLP 层(即 )。然而,如 GNN Encoder 一节中所述,当使用扰动后的图 G𝑝𝑒𝑟𝑏 作为输入时,表征质量会受到影响,特别是在遮盖率 较高时。因此,直接应用上述标准解码器架构的性能相当有限。同时,这种限制是由遮盖后图结构的不完整性造成的,所以仅仅采用更先进的神经网络(如 GNN)并不能解决这个问题。这是因为 GNN 依赖于可靠的网络结构进行信息传播。基于上文,这篇文章提出了一个互相关解码器(cross-correlation decoder)来显式地捕捉两个终端节点间在不同粒度下互相之间关系的相似性。具体来说,给定 个从编码器得到的节点 和 表征,即 ,根据公式2计算其互表征(cross representation) ,公式2如下所示: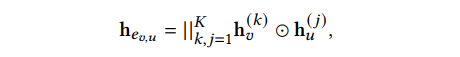
其中, 表示元素相乘(element-wise product), 是最终的边表征(edge representation)。 表示节点 的第 个表征向量(embedding)和节点 的第 个表征向量对应位置上的元素相乘。这种操作可以有效地模拟他们之间的交叉关系,即通过突出两者的共同属性并稀释不一致的信息。因此, 中的大部分元素都将是 0 或者很小的值(small value),只有那些在两个节点之间高度相关的(highly correlated)元素会被保留,这对于后续的边预测(edge prediction)任务非常有用。3.4 Training and Inference
S2GAE 使用随机梯度下降法进行优化。它首先使用有方向感知的图掩盖策略对输入图 进行扰动,得到 和 。然后,将 输入 GNN 编码器 来生成节点表征。接下来,互相关解码器 根据其端节点(end node)的各层(multi-scale)表征,估计锚定边(anchor edge)的存在概率。最后,通过最大化 中被掩盖边的可能性,对模型进行端到端的训练。经过训练后,S2GAE 模型可以通过输入没有掩盖的原始图来生成节点表示。该节点表示可以应用于不同的下游任务(downstream task),如链接预测、节点分类和图分类任务。
具体来说,对于分类任务,可以直接使用所学到的节点表征进行节点分类,同时使用 MaxPooling 或 MeanPooling 函数等来获得图表征,进行图分类任务。对于链路预测,给定一条未见过的边,通过将其端节点(end node)的表征反馈给解码器 来估计其存在的概率。实验表明,S2GAE 模型可以在上述三个任务中均取得了有竞争力的(competitive)表现。
Experiment
实验部分可分为如下章节,实验设置和基线(baseline)的介绍在这里不过多赘述,有兴趣的读者可以自行阅读全文。如表 1 所示,在链路预测任务上,S2GAE 在 8 个数据集中的 5 个上表现都优于生成性(generative)及对比性(contrastive)基线,而在另外 3 个数据集中的 2 个上也与基线(baseline)表现相当。
此外,S2GAE 在大规模的 OGB 数据集上有很大的性能提升。与 MaskGAE 相比,S2GAE 在 5 个大规模数据集上获胜,而在 3 个小数据集上表现稍逊。这一结果揭示了 S2GAE 模型的可扩展性(scalability)。▲ 表1
如表 2 所示,在节点分类任务上,S2GAE 在 9 个数据集中的 5 个上表现均优于所有基线,特别是在两个大规模的 OGB 数据集上。与传统的生成性方法(不包括 GraphMAE、MaskGAE 和 S2GAE)相比,对比性方法在几乎所有的分类场景中都能达到 SOTA 的效果。然而,通过从掩盖编码方面对 GAE 进行改进,S2GAE、GraphMAE 和 MaskGAE 的表现往往与 SOTA 的对比性方法相当,甚至更好。
具体来说,与 GraphMAE 和 MaskGAE 相比,S2GAE 在相对较大和更具挑战性的数据集上表现特别好,如 orgn-arxiv 和 ogbn-proteins。这些结果验证了 S2GAE 在节点分类上的泛化(generalization)能力。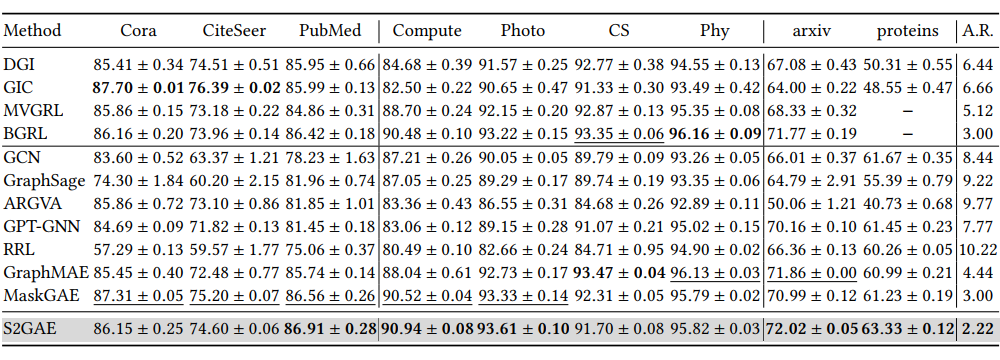
如表 3 所示,在图分类任务上,S2GAE 在 7 个数据集中的 5 个超过了现有的对比性和生成性基线。这些结果证实了S2GAE在图级任务上的泛化(generalization)能力。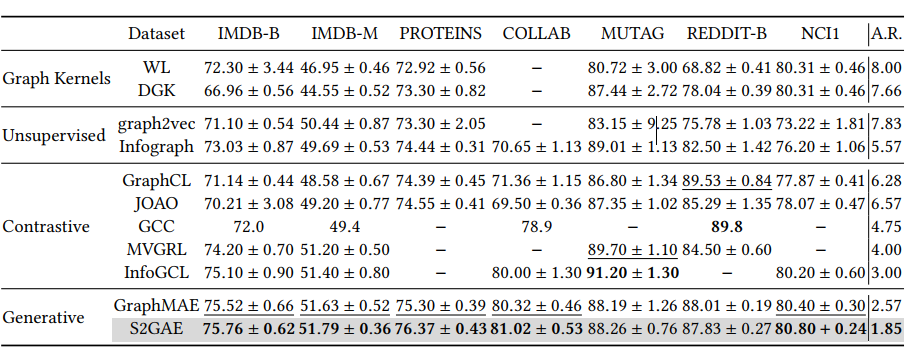
在这章中,介绍 S2GAE 在消融实验中的结果,以验证 S2GAE 的有效性。
1. 自监督训练对 S2GAE 至关重要:S2GAE 的核心思想是在一个自监督的环境下训练 GAE。为了验证其必要性,本文在表 5 中探讨了图掩盖(w/o GP)和掩盖的边重建(w/o MGR)的贡献。一般来说,如果把它们放在一起考虑,S2GAE 的性能比它们中的任何一个都要好。这个结果验证了本文从 SSL 角度改进 GAE 的动机。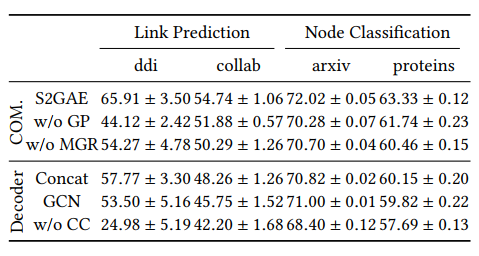
▲ 表4
2. 互相关解码器的效果(effect):捕捉节点之间的互相关性对于预测被掩盖的边是很重要的。
为了验证这一点,本文在表 4 中比较了 S2GAE 在不同解码器下的变体。首先,S2GAE 和“Concat”(或“GCN”)变体之间的性能差距表明,连接所有的节点表征(或采用先进的 GNN 模型作为解码器)对从噪声表征中重建被掩盖的边没有帮助。其次,在没有互相关解码器的情况下,变体(w/o CC)在 4 个评估(evaluation)场景下均表现很差。这些结果证明了所提出的互相关解码器的有效性。
3. 遮盖率(masking ratio)的影响:图 2 的右图显示了遮盖率的影响。一般来说,一个小的遮盖率(如 )不足以学习到可泛化的(generalizable)特征,而当 达到 0.7 时,S2GAE 模型也一直表现良好。▲ 图2
4. 有方向感知的图掩盖策略的影响:图 2 的左图显示了图掩盖策略的影响。DM 在 OGB 数据集中更有效,而 OGB 数据集比其他数据集更稀疏。这些结果验证了对不同类型图进行方向感知的图屏蔽掩盖策略的必要性。

这篇文章提出了一个简单而有效的自监督图自动编码器框架——S2GAE,它通过从图掩盖(graph masking)的角度改进模型设计,提高了标准 GAE 架构的泛化能力。S2GAE 的主要创新点包括有方向感知的图掩盖策略(direction-aware graph masking)和定制的互相关解码器(cross-correlation decoder),它们的共同作用为 GAE 提供了超越链路预测的能力。
在链路预测,节点分类和图分类任务上的实验结果证明了 S2GAE 的强大泛化能力。本文的研究揭示了 GAE 作为通用图学习模型的潜力,并呼吁人们重新关注这个方向。

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
