

开源项目:
Llama-X: Open Academic Research on Improving LLaMA to SOTA LLM
https://github.com/AetherCortex/Llama-X
我们是一群人工智能领域的开源爱好者,来自国内外高校实验室,企业研究院,以及独立开发者。
我们有一个共同的目标:与开源社区一道,推动 LLaMA 成为最先进的 LLM。
我们承诺:研究为了开源,研究依靠开源,研究成果与开源社区共享。Let's Make AI Open Again。
我们希望:Llama-X 是一个长期、系统、严谨的 LLM 学术研究项目。
我们相信只有通过开放包容的态度,才能汇聚更多的智慧和力量,做出真正属于全人类的人工智能。因此欢迎每一位对 Llama-X 感兴趣的同行加入我们,你可以通过为任何一个技术节点贡献有效的数据,代码,论文,算力而成为 Llama-X 的一员。
目前 NLP 社区对于 SOTA LLM 模型相关技术的研究主要存在以下 5 个问题,导致我们在资源分散的劣势下无法形成合力:
1. 算法层面,停留在对于已公开文献中 Instruction-Following、PPO 等算法的简单复现,忽视研究算法性能的上限、算法改进、以及未公开的算法细节;
2. 工程层面,重视对于小模型的微调,忽视整个预训练系统的稳定性和可扩展性;
3. 数据层面,忽视从预训练到微调,高质量数据的科学收集和使用对于模型能力的定量影响;
4. 评测层面,一般仅通过若干个样本示例来比较和定义不同微调模型的能力;
5. 最后,忽视对 Long Context、Text+Vision Modeling 等前沿技术的深入研究。
因此,我们希望以一种系统、严谨、量化的方式,递进式地揭露、验证、提升 SOTA LLM 背后完整的算法原理和技术路线。具体地,基于初代 LLaMA 模型的优异表现,我们决定以它为起点,通过版本迭代提升其性能,任何在算法、数据、工程层面的技术猜想和努力,都可以最新版本的 Llama-X 为基准进行多维度的量化比较和验证。同时,我们将负责实时整理并更新所有版本模型能力进化的技术路线与关键细节,主要版本将以学术论文的形式发布。
接下来我们将依次介绍 Llama-X 的总体原则、十大关键技术、版本迭代方案、训练工具示例、如何成为 Contributor 等五个方面。
总体原则
Llama-X 是一个长期、系统、严谨的开源学术研究项目,它既非只为复现某一个特定算法,也非只针对某一细节的改进,而是通过对现有 SOTA 模型的基本原理,工程架构,训练进化的全面分析,制定并公布完整的研究方案和技术路线,欢迎每位参与者在特长领域开展研究,分工协作,通过对目标版本的迭代,逐步提升 LLaMA 模型的性能。Llama-X 的学术研究,主要围绕本文提出的十大关键技术展开;模型版本的迭代,须以模型在自动指标上的显著提升作为主要依据,同时以规范公平、统计显著的方式进行发布前的人工评价和示例比较。每一代主要版本新模型及技术细节,我们都将以学术论文的形式完整发布,论文作者为实际参与此版本研究的 Contributor。
十大关键技术
我们经过反复研究和讨论,制定了以下 10 个主要研究方向:1. 指令微调
指令微调是新近语言大模型的代表能力,它可以帮助人类用自然语言对大模型下达命令,进行沟通交流。指令微调技术包括:指令训练数据集构建,自动/人工评测方法,高效进行指令微调训练,减轻对大模型通用知识能力的伤害等。2. 反馈型强化学习
使用人类反馈进行强化学习训练已经证明可以大幅提升语言大模型的有用性,可靠性,降低其偏见和误导。鉴于人类反馈非常昂贵,如何用相对便宜低廉的 AI 系统代替人类进行强化学习训练是一个值得长期探索的研究领域。这是一个无需赘言的课题,从预训练,RLHF,到多阶段微调,高质量的训练数据始终扮演决定性的角色,但目前开源 LLM 的训练数据趋向同质化和同分布,忽视了对更广泛数据的收集和甄别,以及验证不同质量/规模数据对模型能力的量化影响。 4. 长程上下文能力
GPT-4 可以同时编码 32768 个 token,大概相当于 50 页文本的内容,这一突破将该模型推向了新的高度,并在各种需要超长序列理解的应用中释放了各种可能性。有了更大的上下文窗口,GPT-4 现在可以有效地处理更复杂和冗长的输入,例如处理整个法律文档、理解学术文章的全部内容,甚至与用户进行超长的多轮对话,这种能力在微软发布的新必应中得到了很好的验证。虽然现有 ALiBi,LONGT5,CoLT5 等技术已具备长序列建模能力,但我们希望探究 GPT-4 具体如何做到效率与效果的完美兼顾? 文本+视觉对象的联合建模,并不是一个陌生的研究课题,最近两年包括 CLIP,DALL-E, Flamingo,PaLM-E 等模型在多模态对齐、理解、控制上展示了令人惊叹的能力,但 GPT-4 对于图像细致精准的理解,仍是目前开源算法未能企及的水平。6. 多语言能力
我们认为模型多语言能力的习得,主要通过收集与训练足够的高质量数据。但因为该能力在应用层面的巨大价值,以及 GPT-4 极致均衡的多语言表现和 LLaMA 预训练数据在语言多样性上的天生缺陷,所以我们在此单独讨论。7. 高效的基础设施和优化
一个毫无疑问的事实是,GPT 系列模型的训练,在这个世界上最好的云计算平台完成。GPT-4 项目的一大重点就是构建了一个可预测扩展的深度学习堆栈:他们甚至可以使用 1/1000 的计算量,去可靠地预测最大模型的能力。这种由基础设施带来的生产力水平的降维领先,其实是开源社区以及非 Azure 企业用户训练优化 LLM 的最大阻力。8. 科学全面的评测
显然,仅通过若干实例的尝试,无法准确评价模型能力,也无法全面发现模型的能力缺陷,在这方面 Stanford CRFM、清华 CoAI 等团队做了出色的贡献。但我们对 LLM 的使用经验、能力边界、模型危害等认知仍处早期阶段,因此科学全面的评测 LLM,有利于我们进一步认识模型,比较模型,改进模型。9. 模型可解释性
尽管我们对于 LLM 各项涌现能力来源的各种讨论已经持续了相当一段时间,但是这种“先训练模型,再发现能力,最后自圆其说”的研究路径,说明我们在理论上的认知已落后于技术的自我进化。10. LLM与其他场景的结合
从 New Bing Prometheus 到 ChatGPT Plugin, LLM 正在改变一切科技应用的形态和内涵,也许不久的将来,LLM 将重构传统搜索、推荐、广告、电商、社交领域的技术架构,也给 NLP 研究者们带来了新的机会。 以上具体细节请访问我们即将发布的《Llama-X 白皮书》。
模型版本迭代方案
我们将会在下周 4.9 号之前发布 Llama-X 初代版本模型 Llama-X 3.0.1 及其论文。 为便于比较,我们将 Llama-X 未来主要版本从 3.0.0 - 4.0.0 进行编码。3.5.0及以下性能应与对应版本的 GPT-3.5 相近,3.6.0 及以上应每次缩小与 GPT-4 20% 以上的 Gap:
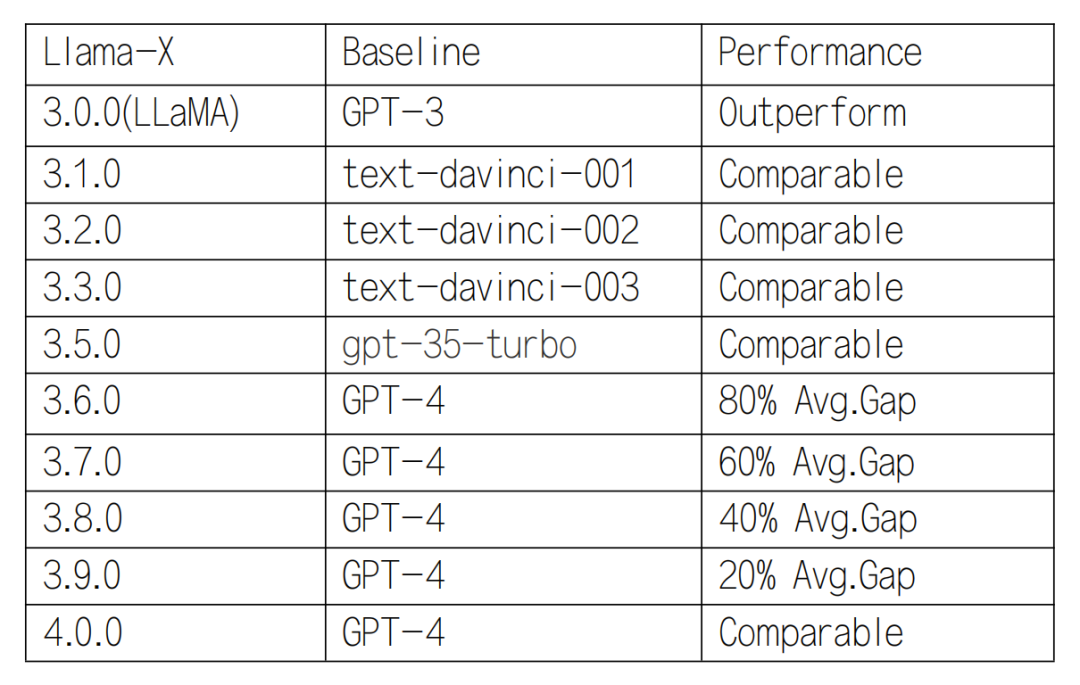
每一代 Llama-X 模型的 check-in,都至少应在以下所有 A 类 Benchmark 的自动指标评价中显著优于当前版本模型,并在 3.6.0+ 版本中新增测试 B 类 Benchmark:

注:所有 Llama-X 模型的使用条件及适用场景均与 Meta AI LLaMA 保持一致。
训练工具示例
Llama-X 提供了一个高效的训练工具作为研究的起点和示例。目前的模型训练利用 DeepSpeed Zero-3 技术实现了优化器状态(Optimizer States)、梯度(Gradients)与参数(Parameters)的分发(Partitioning),从而显著降低了显存占用率。此外,当前版本的代码支持完整 LLaMA Checkpoint 的 finetuning,而非基于 LoRA 等技术。 如下表所示,我们在 Alpaca 提供的 52k 训练样本以及 8 卡 V100 GPU 的条件下,实现了 LLaMA-7B 和 13B 模型的高效训练,我们也即将支持 33B 和 65B 模型的分布式训练。但这并不代表开发者必须使用这一工具,你可以改进这一工具,或分享更高效的训练方式,因为我们的共同目标是提升模型性能和整个训练系统的效率。开发者可以通过贡献数据,代码,论文,算力等成为 Contributor。1. 代码:包括算法实现,训练优化,推理优化,模型部署。2. 数据:每一个研究方向及版本迭代,都需要高质量数据,包括 Instructions,Pre-train data,Multi-modal,Multilingual,User feedbacks 等。 3. 论文:我们将维护一个 Llama-X Paper List, 以 Llama-X 为基座模型进行优化、完整测试、且显著提升的学术论文,可以 check-in 到 Llama-X Paper List。4. 算力:我们希望通过协调部分开发者的冗余算力,或高校/企业的非营利性赞助,帮助加快模型迭代速度。
https://github.com/AetherCortex/Llama-X
https://discord.gg/2etwhe6GvU


如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
