「每个人都有一个自己的大模型 —— 这是一个想象力演示,还是真正的技术发展方向?……」
本周,阿里 AI 会有大动作已经传开了。自去年 11 月底 OpenAI 发布 ChatGPT 以来,大语言模型成为整个 AI 社区关注的焦点。国外大厂要么在自己的应用中融合 ChatGPT(如微软新必应),要么推出对标大模型(如谷歌 Bard)。国内也掀起了研发类 ChatGPT 的热潮,先后出现了 ChatYUAN、MOSS、文心一言等文本对话大模型和产品。第一个透出的是阿里大模型联合项目团队(以下简称联合团队)调教出了一个有个性的大模型,与脱口秀演员鸟鸟合作训练出她的数字分身 —— 鸟鸟分鸟。在这个针对消费级终端的大模型技术交流中,机器之心参与评测了几个重要体验:- 唤醒一次,即可与 “鸟鸟分鸟” 不间断自由语音对话。
- 鸟鸟分鸟很拟人化,拥有了鸟鸟的音色、语气、表达方式。
- 与其他对话机器人一样,可以从鸟鸟分鸟那里了解百科知识,还能在创作时获得灵感。
鸟鸟是一位脱口秀演员,她在《脱口秀大会第 5 季》中获得年度亚军,其社恐式脱口秀风格收获了大量粉丝,被称为文本之神、互联网嘴替。机器之心还向这个联合团队了解,其研究的特点是两个方面:一是如何让大模型为个人终端、家庭场景等安全高效的服务;二是 AIGC 以多模态驱动,包括文本、图像、语音、视频。由于整个技术接口通过天猫精灵终端进行演示,我们应该可以预期,阿里版 ChatGPT 应该会融合多种产业场景,推向智能助手和消费终端行业是其中之一。是骡子是马拉出来遛遛,在拿到天猫精灵音箱后,机器之心立即体验了一把鸟鸟分鸟的聊天能力。一番体验下来,鸟鸟分鸟超出了预期,就像跟鸟鸟本人交流一样,很有那个味!此外在知识启蒙、共情和创作辅助的多轮对话中带给用户帮助。不过目前能力不稳定,比如让它来段周杰伦的音乐,只能说出几句歌词,没有跳到播放音乐技能。相信后续版本会呈现更好的效果。最近几年,大模型在通识任务上的表现越来越出色,基于超大规模语料训练的大模型在知识评测等任务上超越了人类平均水平。ChatGPT 等对话大模型的出现更让人切身感受到 AI 的智能水平,其回答人类问题的能力令人叹服。然而,目前的通识大模型似乎缺少了个性,当问它的偏好、对某事的看法这类问题时,回答效果就没那么好了。因此,在主流通识大模型的基础之上注入个性化是一个重要的探索方向。从相关研究的演进来说,这种个性化大模型在对话场景训练中关注多轮对话中人设一致性、对话风格、逻辑一致性和对话三观以及有偏好的个性化对话。这意味着它们被赋予了相应的角色设定,包括身份、性别、名字、性格、偏好等,并拥有了共情能力。针对个性化大模型的这四个细分方向,学界和业界已经发表过一些相关的观点和论文。关于多轮对话中人设一致性,哈工大研究团队在 AAAI 2019 论文 [1] 中提出利用自然语言推理(NLI)技术来解决,将来自响应 - 角色对(response-persona pairs)的 NLI 信号作为对话生成过程的奖励。关于对话风格,Meta 在论文 [2] 中利用三种可控生成方法(即检索和风格迁移、即插即用和有条件生成器微调)控制开放域对话的风格。关于对话过程中的三观,爱丁堡大学联合 DeepMind 在论文 [3] 中提出要赋予对话大模型不同的三观。最后关于有偏好的个性化对话,华南理工联合清华大学在论文 [4] 中提出了一个基于影视角色的大规模中文个性化和情感对话数据集 CPED,它包含了与共情和个人特征相关的多源知识(性别、人格特质、情感等)。该研究还强调了说话人个性和情绪在对话式 AI 中的作用。对于阿里而言,这个领域最早可以追溯到 2020 年其联合南洋理工大学发表在顶会 EMNLP 2020 的论文[5],对基于角色的共情对话模型进行了深入研究。但这篇论文似乎不是今天看到的个性化大模型的同类技术方向。为了让大模型更好地符合角色的特点,阿里联合团队这次首次提出了 “知识、情感、记忆、性格” 四位一体的个性化大模型方向,相信相关的研究论文应该在路上。融合个性化大模型能力的对话产品在回答问题时会给出符合身份、性格的答案,提升用户的满意度。鸟鸟分鸟正是联合团队在个性化大模型中训练出来的,用了仅仅 15 天时间完成工程链路。整个过程分为了大规模语言训练、知识和工具增强、个性化对话增强和人类反馈增强等四步。第一步大规模语言预训练,用到了层次化训练方法,模拟人类学习,从简单知识到专业复杂知识,逐步增加难度。就鸟鸟分鸟而言,联合团队先用大规模语料进行预训练,让大模型学习到足够的世界知识,其中也包含了鸟鸟的公开信息。但第一步后发现,每天都会有大量新增和过时的知识,因此把所有知识记下来不是好的选择。联合团队选择使用搜索引擎等工具让大模型能力变得更强,比如利用搜索引擎输入在对搜索结果的理解和归纳基础上更准确和及时地回答问题。这样一来,鸟鸟分鸟可以回答最新信息、新闻等。接着第三步,在知识和工具增强的基础上进行个性化对话增强。这里鸟鸟分鸟既要学习多轮对话和启发式对话,具备了较好的多轮一致性和连贯性;又被赋予了人格标签,联合团队标注了少量的鸟鸟语料来做个性化增强和调优,实现了快速的角色复刻。最后像不像鸟鸟,人类反馈更直接真实。联合团队利用人类反馈增强做角色强化,检查多个回答候选中哪个更像或不太像鸟鸟、哪个对或不太对。这些反馈和标注对个性化对话大模型进行纠偏,朝着更像鸟鸟的方向正向增强。不过目前联合团队只是基于成员反馈来增强,未来将开放给更多鸟鸟粉丝以收集更多反馈,让鸟鸟分鸟更具真实感。
语音交互是一项系统性工程,对天猫精灵鸟鸟分鸟而言,不仅要听得清,还要说得像。联合团队在训练鸟鸟分鸟之后,着力在听清、音色和文风几个方面提升它的对话式 AI 体验。
首先在对话中让鸟鸟分鸟听清人说的话。联合团队采用了猫耳算法,即准确地听声辨位。一方面做回声消除,设备播放产生的回声会对对话有较大干扰。联合团队结合深度学习方法与传统 AEC、多通道立体声消除回声,确保设备只听到人说的话。另一方面是定向拾音,借助设备中的麦克风阵列,在被唤醒时准确识别说话人位置,精准捕捉人声。同时利用降噪消除非人声或远处说话人的声音。其次让鸟鸟分鸟的音色接近鸟鸟,这要归功于阿里达摩院自研的声学模型。传统人声定制方案复杂,可能需要收集 20 个小时的有效录音数据,并以年为周期定制算法,时间成本太高。传统语音合成的声音机械感也强,一听就是机器人的声音。达摩院的 KAN-TTS 定制方案只需收集 1 个小时的鸟鸟有效录音,从录音到训练完成、模型上线差不多一周时间。呈现出的拟人化声音更自然,接近了鸟鸟的音色。
最后是文本风格。鸟鸟分鸟不仅要在音色上接近鸟鸟,还要沿用她的表达风格。这可以通过人格标签的方式为对话大模型设置角色风格,角色性格开朗则整体给人快乐、乐观的形象。同时在人设描述上进一步约束,比如叫什么、多大了、干什么的、哪里人。联合团队针对鸟鸟分鸟选择了脱口秀演员、内蒙古人、有深度、幽默、内向、90 后等标签词。另外,在与鸟鸟分鸟的互动中发现,当人说话时,它会发出一些承接词,比如「嗯,我在」、「容我想一想」。当它回答上一个问题到一半时,我们还可以打断它直接问下个问题。整体对话时延非常低,基本接近人与人之间的对话。这都要得益于已经在云上运行很久的双工对话系统,使对话体验有了很大提升。善于倾听、增量对话和较低时延成为这种双工对话系统有别于传统对话的几个显著特征。整体来看,联合团队致力于四位一体的大模型个性化,从问问题产生 Query、利用 ASR 猫耳算法精确转换成文本、文本又通过通义大模型产生个性化对话回复、最后个性化 TTS 给出个性化音色(鸟鸟)答案。这个大模型能实现知识、情感、记忆和性格四位一体。联合团队还希望鸟鸟分鸟具备长短期记忆,短期要能记住过去三至五轮讲到的话题,并基于这些来回复;长期则是在做好安全隐私共识的基础上,会对用户对话中的偏好、喜欢做什么、吃什么等信息存储下来,在未来对话过程中更加理解用户并产生共情和风格化的对话。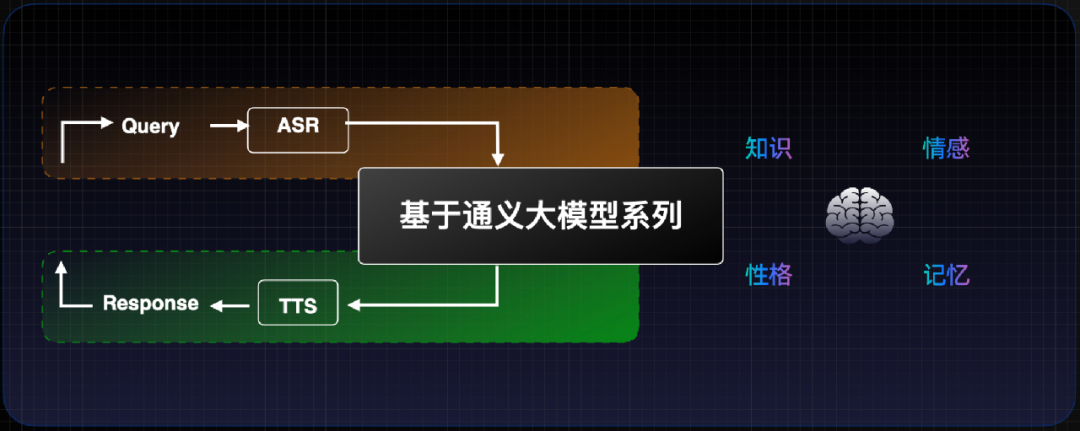
这样看来,鸟鸟分鸟目前似乎是一个专门部署的大模型,而不是一个大模型进行角色扮演。这背后似乎也暗含着面向未来的探索。如果鸟鸟可以有一个自己的大模型,是不是每个家庭也可以独立部署自己的 AIGC 智能服务呢?[1] Haoyu Song etc. Generating Persona Consistent Dialogues by Exploiting Natural Language Inference[2] Eric Michael Smithattitude etc. Controlling Style in Generated Dialogu[3] Atoosa Kasirzadeh etc. In conversation with Artificial Intelligence: aligning language models with human values[4] Yirong Chen etc. CPED: A Large-Scale Chinese Personalized and Emotional Dialogue Dataset for Conversational AI[5] Peixiang Zhong etc. Towards Persona-Based Empathetic Conversational Models© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]