【新智元导读】一夜之间,AI大模型圈变了天。Meta联手微软宣布,Llama 2正式开源商用。
一觉醒来,Meta直接丢了一颗重磅核弹:Llama 2!
继LLaMA开源后,Meta今天联手微软高调开源Llama 2,一共有7B、13B、70B三个版本。
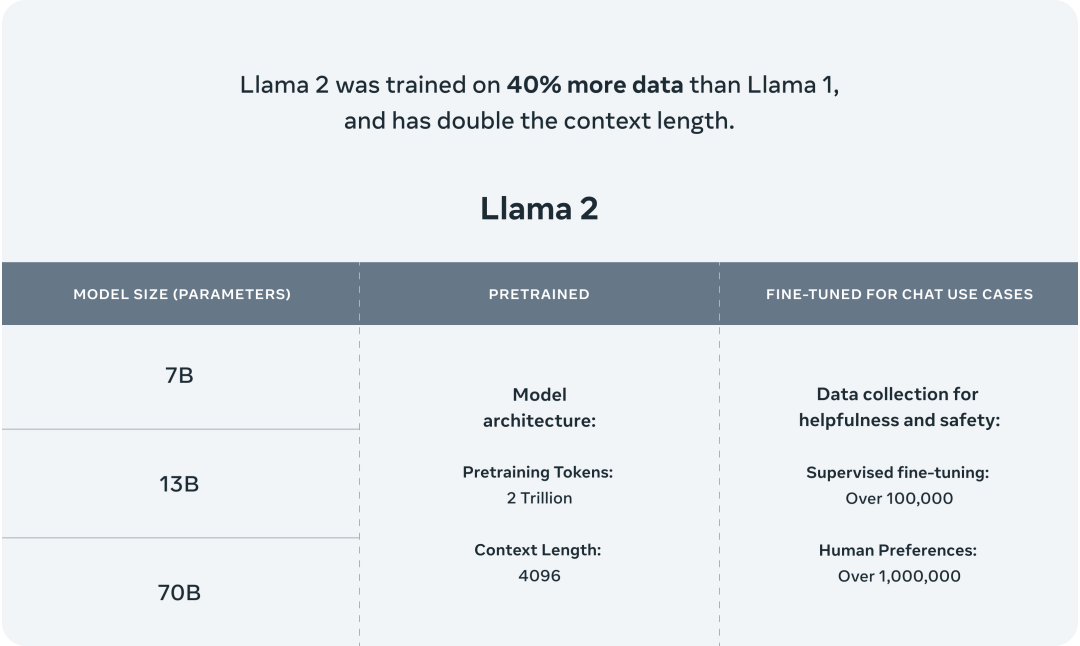
据介绍,Llama 2接受了2万亿个token训练,上下文长度4k,是Llama 1的2倍。微调模型已在超100万个人类标注中进行了训练。
Llama 2的表现更是秒杀许多开源语言模型,在推理、编码、能力和知识测试上取得了SOTA。
最最最重要的是,这次Llama 2不仅可以研究,甚至能免费商用!(划重点)

今年2月,Llama 1开源后,Meta收到了10万多个访问大型语言模型的请求。
没想到,Llama的开放瞬间让AI社区模型大爆发,UC 伯克利的Vicuna、斯坦福Alpaca等各种系列「羊驼」蜂拥而出。
这次,Llama 2的开源直接向OpenAI和谷歌发起挑战。
在OpenAI和谷歌独占鳌头下,Meta此举想通过另辟蹊径改变大模型AI之争的格局。
LeCun表示,Llama 2免费商用将直接改变大型语言模型的市场格局。
Llama 2的横空出世,没想到,直接被一众网友「封神」。
Meta,你的王冠掉了
就连GPT-4,被推下了战场。

但是,就客观来讲,Llama 2真的无所不能吗?
英伟达科学家Jim Fan称,Llama 2还没有达到GPT-3.5的水平,主要是因为其代码能力较弱。
关于Llama 2更多细节,Jim Fan和做了一个太长不爱看版:
- Llama 2的训练费用可能超过200万美元。
Meta发布商业友好许可的模型,为社区提供了令人难以置信的服务。由于许可问题,大公司的AI研究员对Llama-1持谨慎态度,但现在我认为他们中的很多人都会加入进来,贡献自己的力量。
- Meta团队对4K提示进行了人类研究,以评估Llama-2的实用性。
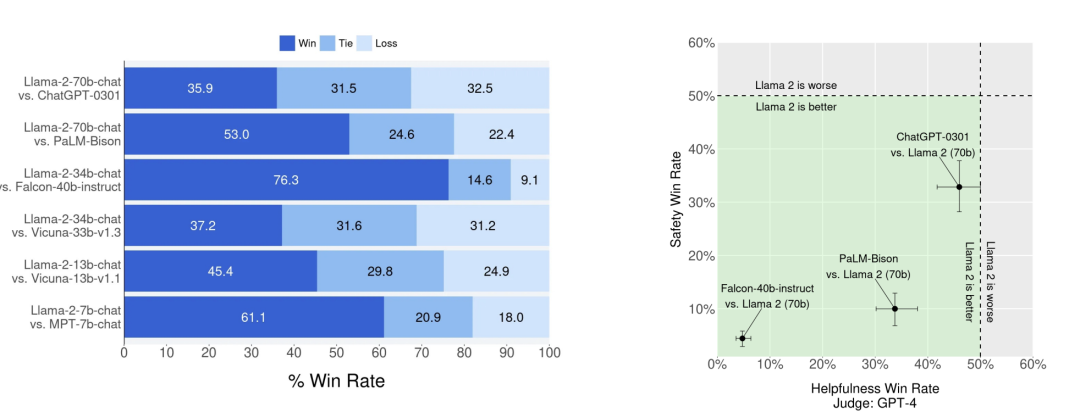
他们使用「胜率」(win rate)作为比较模型的指标,与Vicuna基准类似。70B模型与GPT-3.5-0301大致持平,表现明显强于Falcon、MPT和Vicuna。
与学术基准相比,我更相信真实的人类评级。
- Llama-2还没有达到GPT-3.5的水平。
在HumanEval上,它还不如StarCoder或其他许多专门为编码而设计的模型。尽管如此,我毫不怀疑Llama-2将因其开放的权重而得到显著改善。
- Meta团队在人工智能安全问题上不遗余力。
事实上,这篇论文几乎有一半的篇幅都在谈论安全护栏、红队和评估。
在之前的研究中,有用性和安全性之间非常难平衡。Meta通过训练2个独立的奖励模型来缓解这一问题。这些模型还没有开源,但对社区来说非常有价值。
- Llama-2将极大地推动多模态人工智能和机器人研究。
这些领域需要的不仅仅是黑盒子访问API。到目前为止,研究人员必须将复杂的感官信号(视频、音频、三维感知)转换为文本描述,然后再输入到 LLM,这样做既笨拙又会导致大量信息丢失。
而将感官模块直接「嫁接」到强大的LLM主干上会更有效。
- 技术报告本身就是一部杰作。
GPT-4的技术报告只分享了很少的信息,而Llama-2则不同,它详细介绍了整个recipe,包括模型细节、训练阶段、硬件、数据管线和标题过程。例如,论文对 RLHF 的影响进行了系统分析,并提供了漂亮的可视化效果。
Llama 2最新技术报告也同在今天发布,足足有70多页。
GenAI首次以团队名称出现
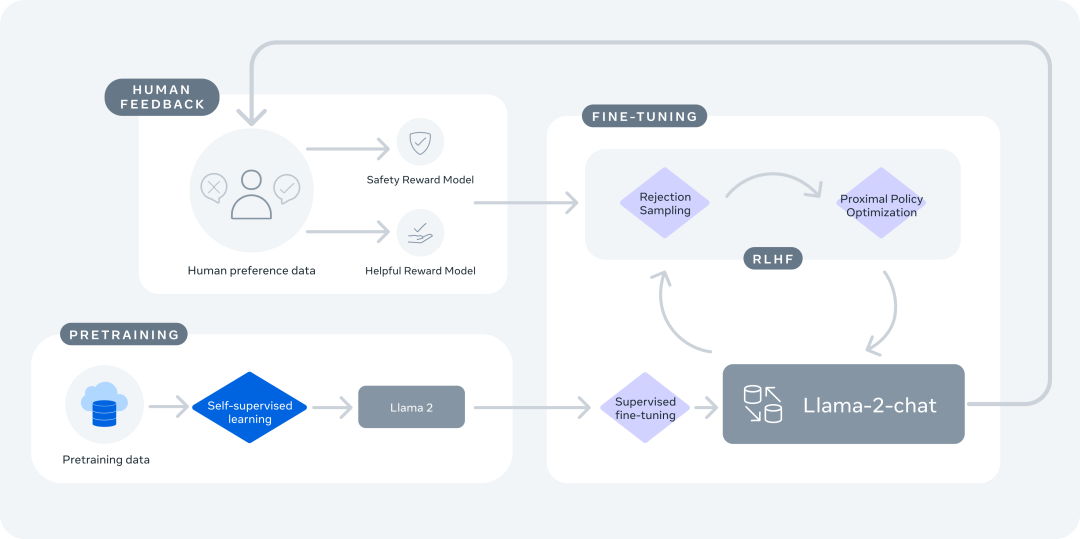
针对模型训练,与ChatGPT相同,Llama 2也是经历了预训练(Pretraining)、微调(Fine-tuing)和人类反馈强化学习(RLHF)三个阶段。
除了开源了Llama 2,Meta基于Llama 2微调了Llama 2-Chat模型。
在各大基准测试上,Llama 2在推理等方面表现相当出色。
接下来,具体看看Llama 2是如何诞生的吧。
预训练
为了创建新的Llama 2,Meta的研究人员首先采用了Touvron等人所使用的预训练方法,应用了优化的自回归Transformer。
但是,为了进一步提高性能,Meta团队做了一些改动。
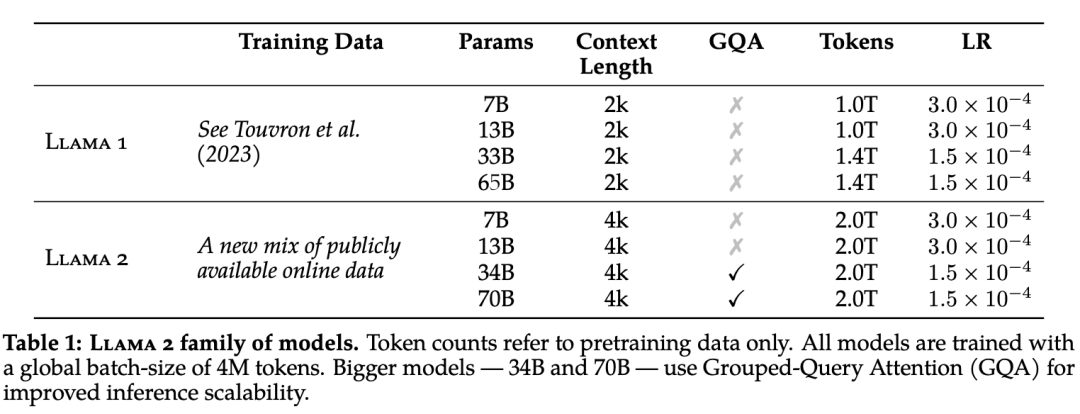
具体来说,研究人员进行了更稳健的数据清理,更新了数据组合,且训练的标记总数增加了40%,上下文长度增加了一倍,还使用了GQA(Group Query Attention)来提高大型模型推理的可扩展性。
下表比较了Llama 2和Llama 1的属性差异。
在预训练数据方面,Meta的训练语料库包括公开来源的各种新数据组合,但并不包括来自Meta自家产品或服务中的数据。
另外,研究人员努力删除了某些已知包含大量个人隐私信息的网站的数据信息。
Meta团队在2万亿个token的数据上进行了训练(如上表所示),这样做可以很好地权衡性能和成本,并对最真实的数据源进行取样,以增加知识和减少幻觉。
训练细节方面,Meta团队既有沿用也有创新。
研究人员沿用了Llama 1中的大部分预训练设置和模型架构,使用标准的Transformer架构,以及RMSNorm进行预规范化,还用了SwiGLU激活函数和旋转位置嵌入。
与Llama 1在结构上的主要区别在于,增加了上下文长度和GQA(Group Query Attention)(如上表所示)。
下图则展示了Llama 2的训练损耗。
研究人员比较了Llama 2系列不同大小模型的训练损耗分别是多少,Meta团队发现,在对2T数量的token进行预训练后,模型依旧没有出现任何饱和的迹象。
评估
接下来研究人员报告了Llama 1和Llama 2、MPT和Falcon模型在一些标准的学术基准上的性能测试结果。
在所有评估中,Meta团队都应用了内部评估库,在内部重现了MPT和Falcon模型的测试结果。
对于这些模型,研究人员总是在评估框架和任何公开报告的结果之间选取最高分进行比较。
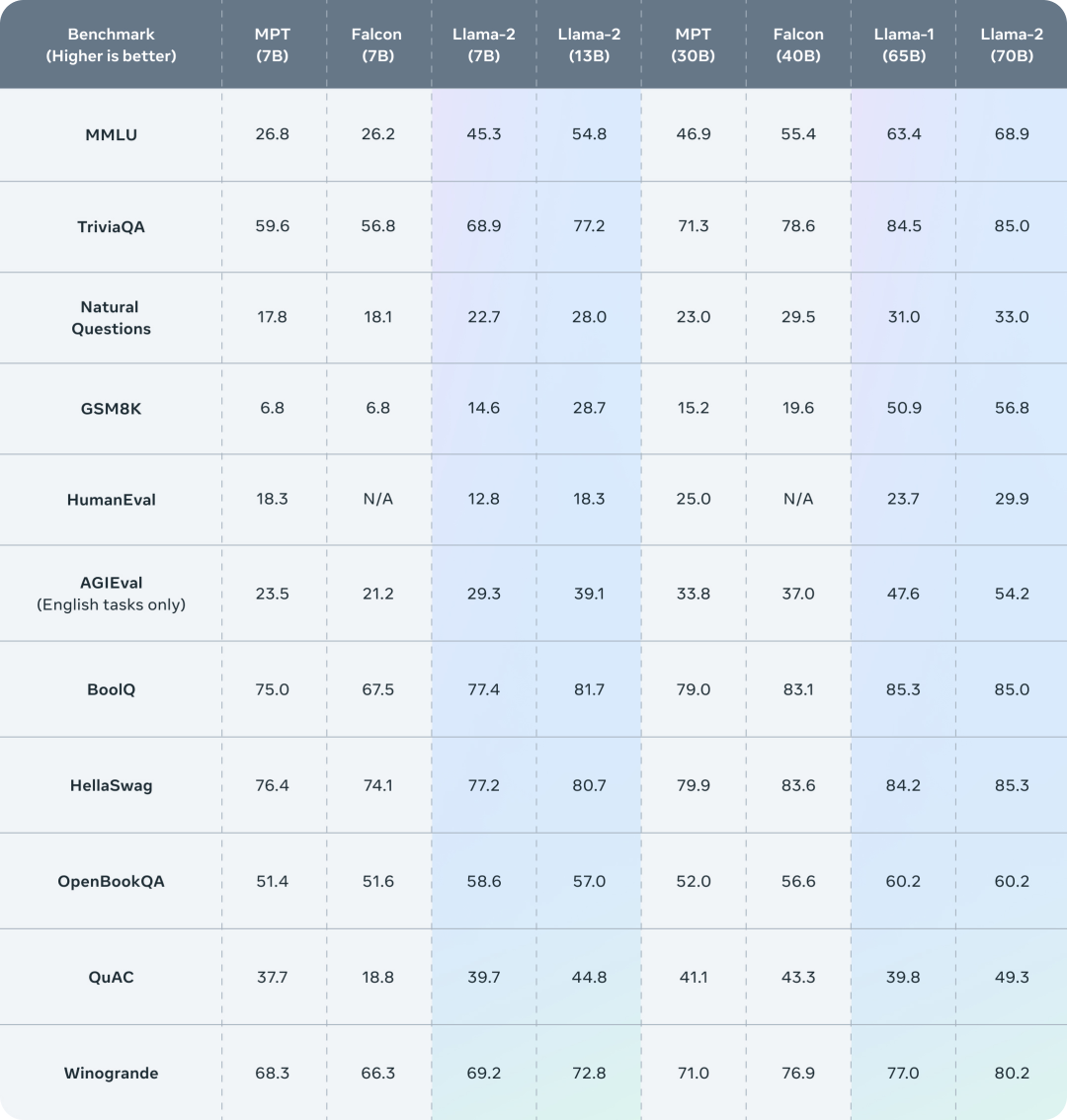
在表3中,研究人员总结了LlaMa 2在一系列常用基准上的总体性能表现。以下是这些常用的基准大致介绍:
代码:研究人员报告了模型在HumanEval和MBPP上的平均pass@1分数。
常识推理:研究人员人员报告了PIQA、SIQA、HellaSwag、WinoGrande、ARC easy and challenge、OpenBookQA和CommonsenseQA等项目的平均得分,还有CommonSenseQA的7-shot测试结果和所有其他基准的0-shot测试结果。
知识面:研究人员评估了NaturalQuestions和TriviaQA的5-shot成绩,以及平均成绩。
阅读理解能力:研究人员报告了SQuAD、QuAC和BoolQ的0-shot平均成绩。
数学能力:研究人员报告了GSM8K(8-shot)和MATH(4-shot)基准的平均成绩,报告第一。
其它热门的综合基准:研究人员报告了MMLU(5-shot)、Big Bench Hard(BBH)(3-shot)和AGI Eval(3-5shot)的总体结果。其中,对于AGI Eval,研究人员只对英语相关的任务进行了评估并报告了平均值。
从上表中可以看出,Llama 2要优于Llama 1。尤其是和Llama 1-65B的模型相比,Llama 2-70B在MMLU和BBH上的成绩分别提高了5分和8分。除代码基准外,Llama 2-7B和30B的模型在所有测试上都优于同等规模的MPT模型。就Falcon模型而言,在所有基准测试中,Llama 2-7B和34B的表现都要比Falcon-7B和40B的模型更好。此外,Llama 2-70B模型也优于所有开源模型。除了和开源模型作比,Meta团队还将Llama 2-70B的结果与闭源模型进行了比较。如下表所示,Llama 2-70B在MMLU和GSM8K上的得分接近GPT-3.5,但在编码基准上有明显差距。在几乎所有的基准测试上,Llama 2-70B的结果都与PaLM 540B相当,甚至更好。而Llama 2-70B与GPT-4和PaLM-2-L之间的性能差距仍然很大。微调
Llama 2-Chat是Meta团队数月研究,并迭代应用了对齐技术(包括指令微调和RLHF)的成果,需要大量的计算和标注。监督微调 (SFT)
第三方的SFT数据可以从许多不同来源获得,但Meta团队发现,其中许多数据的多样性和质量都不够,尤其是让LLM与对话指令保持一致这一方面。因此,研究人员首先重点收集了数千个高质量的SFT数据示例,如上图所示。通过撇开来自第三方数据集的数百万个示例,使用质量较高的示例,研究结果得到了明显改善。研究人员发现,在总共收集到27540条标注后,SFT标注获得了高质量的结果。为了验证数据质量,研究人员仔细检查了一组180个示例,比较了人类提供的标注和模型通过人工检查生成的样本。出乎意料的是,研究人员发现SFT模型生成的样本输出,往往能与人类标注者手写的SFT数据相媲美。这表明研究人员可以调整优先级,将更多的注释精力投入到基于偏好的RLHF标注中。在监督微调中,研究人员使用余弦学习率计划(cosine learning rate schedule),初始学习率为2乘以10的负5次方,权重衰减为0.1,批量大小为64,序列长度为4096个标记。为确保模型序列长度得到适当填充,研究人员将训练集中的所有提示和答案连接起来,并使用一个特殊的标记来分隔提示和答案片段。研究人员利用自回归目标,将来自用户提示的标记损失归零,因此,只对答案标记进行反向的传播。人类反馈强化学习 (RLHF)
Meta团队收集的数据代表了人类偏好的经验取样,人类标注者可以根据这个来选择他们更喜欢的2种模型输出。这种人类反馈随后被用于训练奖励模型,该模型可学习人类标注者的偏好模式,然后自动做出偏好决定。与其他方案相比,团队选择了二进制比较协议(binary comparison protocol),主要是因为它能让研究人员最大限度地提高所收集提示的多样性。研究人员列出了用于奖励建模的开源数据,以及内部收集的人类偏好数据。请注意,二进制人类偏好比较包含共享相同提示的2个响应(选择和不选)。每个示例都由一个prompt和一个回复组成,后者是奖励模型的输入。研究人员报告了比较的次数、每次对话的平均回合数、每个示例、每个prompt和每个回复的平均标记数。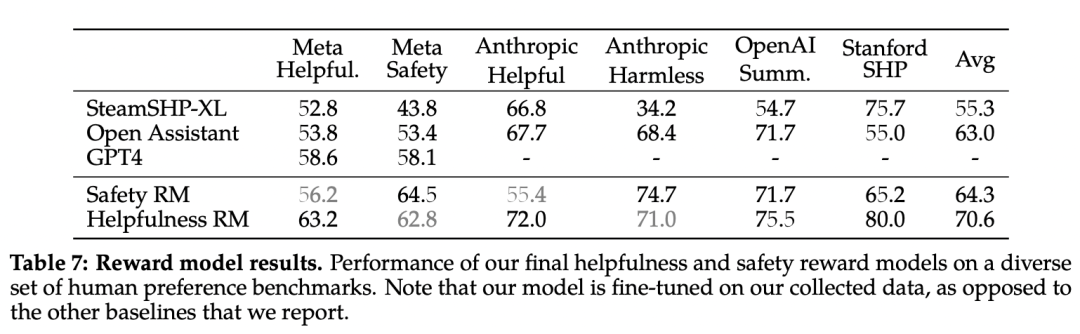
Meta自己的奖励模型在基于Llama 2-Chat收集的内部测试集上表现最佳,其中有用性奖励模型在元有用性(Mega Helpful)测试集上表现最佳。同样,安全性奖励模型在元安全性(Mega Safety)测试集上表现最佳。总体而言,Meta的奖励模型优于包括GPT-4在内的所有模型。有趣的是,尽管GPT-4没有经过直接训练,也没有专门的针对奖励建模任务,但它的表现却优于其它模型。在每一批用于奖励建模的人类偏好标注中,研究人员都会拿出1000个例子作为测试集来评估模型。研究人员将相应测试集的所有提示的集合分别称为元有用性(Meta Helpful)和元安全性(Meta Safety)。作为参考,研究人员还评估了其他公开的替代方案:基于FLAN-T5-xl的SteamSHP-XL、基于DeBERTa V3 Large的 Open Assistant的奖励模型以及GPT4。请注意,推理时与训练时不同,所有奖励模型都可以预测单个输出的标量,而无需访问其配对输出。当然,更多的数据和更大的模型通常会提高准确率,而Meta的模型目前似乎还没有从训练数据的学习中达到饱和。多轮一致性系统消息
在对话设置中,有些指令应该适用于所有的对话场合,例如,简明扼要地做出回应,或者扮演某个公众人物等等。当研究人员向Llama 2-Chat提供这样的指令时,给出的回应应始终遵守该约束。然而,最初的RLHF模型往往会在几轮对话后忘记最初的指令,如下图所示。为了解决这些局限性,Meta团队提出了「幽灵注意力」(GAtt),这是一种非常简单的方法,利用微调数据帮助模型的注意力在多阶段过程中保持集中。应用了GAtt后,结果如下图所示,我们可以看到,GAtt能在多个回合中实现对话控制。下图为应用了GAtt和没有应用GAtt的对话注意力可视化图。研究人员考虑了整个网络的最大激活度,并将相邻的标记放在一起。为了说明GAtt是如何在微调过程中帮助重塑注意力,上图显示了模型的最大注意力激活。每幅图的左侧都对应着系统信息。我们可以看到,与未安装GAtt的模型(左)相比,安装了GAtt的模型(右)在对话的大部分时间里都能对系统信息保持较大的注意力激活。但是,尽管GAtt很有用,但它目前的实现过程还很粗糙,对这项技术进行更多的开发和迭代才会使模型进一步受益。RLHF的结果
当然,评估LLM是一个具有挑战性的开放性研究问题。人工评估虽然是一个不错的标准,但会因各种人机交互考虑因素而变得复杂,而且并不总是可扩展的。因此,为了在从RLHF-V1到V5的每次迭代中从多个模型中选出表现最佳的模型,Meta的研究人员首先观察了最新奖励模型的奖励改进情况,以节约成本并提高迭代速度。研究人员展示了经过多次迭代微调后,Llama 2-Chat与ChatGPT对比胜率百分比的演变。左边的裁判是Meta的奖励模型,可能会向着他们自己的模型,右图的裁判则是GPT-4,其结果应该会更中立。而就像上面提到的一样,人工评估通常被认为是评判自然语言生成模型(包括对话模型)的黄金标准。为了评估主要模型版本的质量,Meta请人类评估员对它们的有用性和安全性进行了评分。研究人员将Llama 2-Chat模型与开源模型(Falcon、MPT),以及闭源模型(ChatGPT) 和PaLM在超过4000个单轮和多轮的prompt上进行了比较。对于ChatGPT,研究人员在各代中都使用了gpt-3.5-turbo-0301的模型。对于PaLM,则使用的是chat-bison-001模型可以看到,Llama 2-Chat模型在单匝和多匝提示上的表现都明显优于开源模型。特别是,在60%的提示中,Llama 2-Chat 7B模型都优于MPT-7B-chat。而Llama 2-Chat 34B与同等大小的Vicuna-33B和Falcon 40B相比,总体胜率超过75%。此外,最大的Llama 2-Chat模型与ChatGPT相比,70B版本的胜率为36%,平局率为31.5%。在Meta研究人员的pompt集上,Llama 2-Chat 70B模型在很大程度上都优于PaLM-bison的聊天模型。
Llama-2商业免费用,对Meta来说,还是首次。根据许可条款,Meta规定不能Llama-2的数据或输出来改进任何其他 LLM,与OpenAI类似,但在OSS模型中并不常见。另外,如果产品MAU在2023年6月超过7亿用户,必须申请特殊商业许可。除上述情况外,使用、复制、分发、拷贝、创作衍生作品和修改 Llama-2 都是免版税的。具体可参见:https://github.com/facebookresearch/llama/blob/main/LICENSE
一边联手OpenAI推出GPT-4加持的付费版Office,另一边牵着Meta的手,欢迎Llama 2在Azure和Windows登台。再把上半年,纳德拉和Sam Altman的合照拿出来,瞬间有种OpenAI遭到背刺的感觉。再加上网友的配文:纳德拉在开放式和封闭式Al之间,做出了令人惊讶和赞叹的举动。(是高手)据Meta官博介绍,我们将与微软的合作伙伴关系提升到一个新的水平,成为Llama 2的首选合作伙伴。Llama 2在Azure人工智能模型库中可用。使用微软Azure的开发人员能够使用它进行构建,并利用云原生工具进行内容过滤。它还经过优化,可以在Windows上本地运行,为开发人员提供无缝的工作流程。另外,Llama 2也可以通过AWS、Hugging Face和其他平台获得。据称,Llama 2在亚马逊AWS上运行70B模型,1年,最低要求大约需要8.50万美元。此外,今天Meta还宣布了与高通联手合作,计划从2024年起在旗舰智能手机和个人电脑上提供基于Llama 2的能力。让开发人员能够利用Snapdragon平台的AI,推出令人兴奋的新生成式人工智能应用。
许多网友纷纷用Midjourney各种AI工具生成羊驼,来致敬这一重要时刻。
HuggingFace的负责人称,Meta在开源人工智能领域的影响力不断扩大,已经在Hugging Face上发布了600+模型,如MusicGen、Galactica、Wav2Vec等。已确认。Llama 2-70B可在48GB的单GPU上轻松训练。70B 4位QLoRA和A6000畅通无阻。Llama 2-7B已转换为Core ML,并以每秒~6.5个token的速度在Mac本地运。我刚才使用这个项目的最新版本在我的Mac上运行了Llama 2:https://github.com/jmorganca/ollama很多人都在问Llama 2与其他流行模型相比如何?与其他类似规模的模型相比,Llama 2显然更胜一筹,而且根据基准测试,Llama 2 是最佳的OS模型!https://ai.meta.com/llama/?utm_source=twitter&utm_medium=organic_social&utm_campaign=llama2&utm_content=video