【新智元导读】谷歌研究院和DeepMind研究人员推出最新PaLI-3视觉语言模型(VLM),模型以更小、更快、更强的特点获得大部分研究人员青睐,在诸多任务中达到SOTA。
最近,堪称改变游戏规则的视觉语言模型(VLM)PaLI-3问世,引得大量科研人员关注。PaLI-3是谷歌最新推出的视觉语言模型,以更小的体量,更快的推理速度,达到了更强的性能。PaLI是谷歌去年推出的多模态大模型。谷歌通过研究对比预训练方法,在PaLI基础上大大提升了PaLI-3的性能。而PaLI-3仅拥有5B的参数量,在定位和文本理解等任务中表现出色,刷新了多个SOTA。
论文地址:https://arxiv.org/abs/2310.09199?ref=emergentmind该模型利用VIT-G14作为图像编码器,拥有2B参数的多模态对比视觉模型。在人工智能圈,PaLI-3重新定义了成功,较小规模模型以实用性和效率赢得了大部分人的青睐。在快节奏的人工智能世界中,视觉语言模型已成为变革型技术,其技术的发展,不断地模糊了图像理解与文本理解的之间的界限。
Google AI的PaLI-3提供了一种紧凑而强大的替代方案,以其强大的性能和1/10的参数与其他模型正面硬刚,有希望彻底改变视觉语言的发展。PaLI-3将自然语言理解和图像识别能力完美地融合,是AI创新的先锋。就像OpenAI的CLIP和Google的BigGAN一样,这些具有文本描述、解码图像卓越能力的模型,解锁了计算机视觉、内容生成和人机交互等众多应用。这使得它们成为人们关注的焦点,成为推动科学研究、商业发展的核心力量。而PaLI-3的成功归功于Google Research、Google DeepMind和Google Cloud的共同努力。研究人员采用了一种新颖的对比预训练方法,深度探索了VIT的潜力,并在多语言模态检索中达到了SOTA,凸显出基于SigLIP的PaLI-3等模型在定位和文本理解任务的优越性。扩大的实用性
虽然大模型的涌现能力、对更大模型的追求往往主导着人工智能的讨论,但是谷歌的研究强调了较小规模模型在实际应用和高效研究的价值。
「PaLI-3登场了,它是一个拥有50亿参数的VLM,性能远超其体量。」PaLI-3的训练过程结合了图像编码器在不同数据集上的对比预训练,分别是网络规模数据、增强混合的数据集和高分辨率数据。具有20亿参数量多语言对比模型占据了人工智能的中心舞台,在需要空间注意力和视觉文本对齐方面,该模型证明了对比预训练模型的主导地位。
那么,PaLI-3的内部结构是什么样的呢?它用到了什么方法?使用了哪种架构?
首先,PaLI-3利用预先训练的VIT-G14作为图像编码器,严格遵循SigLIP的训练方法,其中VIT-G14的20亿参数是PaLI-3的基石。对比预训练是关键,首先对图像和文本嵌入(Embedding),然后在特征层面关联。
进而,将视觉和文本的特征合并起来,输入到30亿参数的UL2编码-解码器语言模型中,以实现精确的文本生成,或用于特征任务的查询提升,例如视觉问答(VQA)。总体评述
在VLM领域,相比同期其他模型,PaLI-3脱颖而出,尤其在定位和视觉文本理解等任务取得非常好的性能表现。
其基于SigLIP的图像编码器预训练方法,开创了多语言跨模态检索的新时代。PaLI-3在引用表达、分割方法表现出色,在不同的检测任务子组中保持卓越的准确性。而值得注意的是,对比预训练是定位首选方法,该方法增强了模型的表征能力。ViT-G图像编码器是PaLI-3的组成部分,在多种分类和跨模态检索场景中表现出了非凡的能力。具体指标
具体地,论文汇报了PaLI-3在各个任务、数据集上的结果。
上图是在 PaLI-3框架内比较了两种类型的 ViT 模型,一种在JFT数据集上进行分类预训练,另一种使用SigLIP在 WebLI数据集上进行对比预训练。结果表明,虽然SigLIP模型在少样本线性分类方面落后,但它们在PaLI-3框架中的Caption、TextVQA 和 RefCOCO 等更复杂的任务中表现出色。无论有或没有外部OCR输入,该模型在大多数基准测试中都显示出最先进的性能。并在无需外部OCR系统的任务中尤其出色。PaLI-3 在参考语义表达上使用VQ-VAE方法预测分割掩模。该模型经过训练来预测边界框,然后预测代表框内掩码的掩码标记。结果表明,对于此类任务,对比预训练比分类预训练更有效。除此之外,PaLI-3 在视频字幕和视频问答基准上进行了微调和评估。尽管没有使用视频数据进行预训练,PaLI-3仍取得了出色的结果(几个 SOTA),凸显了采用对比ViT的好处。模型公平性、偏见和其他潜在问题
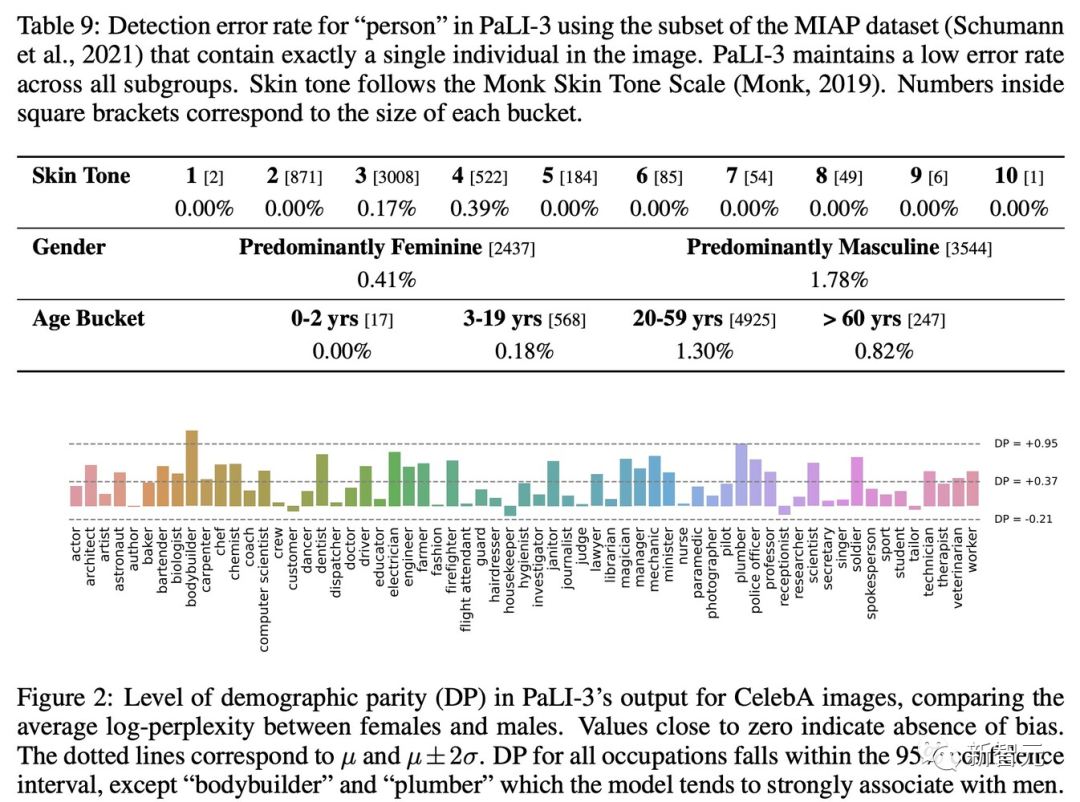
根据论文提供的结果,其方法在所有数据切片的毒性和脏话水平都较低,与PaLI-X模型相当。发现所有子组的错误率都非常低。且在使用MIAP数据集的检测任务中,发现所有子组的错误率都非常低。目前,PaLI-3还未完全开源,但是开发人员已经发布了多语言和英文SigLIP Base、Large和So400M模型。模型链接在huggingface中(https://huggingface.co/models?other=siglip)https://medium.com/@multiplatform.ai/pali-3-a-game-changing-vision-language-model-unveiled-13479bdf6eb5https://the-decoder.com/googles-new-pali-3-vision-language-model-achieves-performance-of-10x-larger-models/