本文结合这三年作者在钉钉见到的应用架构,以及一些业界的实践分享,整理出一篇关于应用读写扩散设计的维基。应用程序员常常自嘲 "CRUD Boy"。也确实, 在应用开发的过程中,主要是在和各式各样的存储打交道,比如 MySQL, Tair, Odps 或者搜索引擎等等,应用主要时间都是在执行各种各样的 "SQL", 而不是在运行业务逻辑。2020年刚来阿里(钉钉)时,第一次听到同事们用 "读扩散" 或者 "写扩散" 来描述自己的架构方案, 瞬间眼前一亮, 觉得这两个词非常简洁地概括了业务应用性能设计的实质。所有的业务应用性能优化,无非就是根据业务场景,通过读写扩散,将数据额外写扩散到一份性能更好的存储,或者读扩散减少数据冗余。比如我们 Tair 缓存,本质上就是将数据库的数据额外写扩散一份到 Tair,这样后续读取性能更好。本文结合这三年我在钉钉见到的应用架构,以及一些业界的实践分享,希望能整理出一篇关于应用读写扩散设计的维基。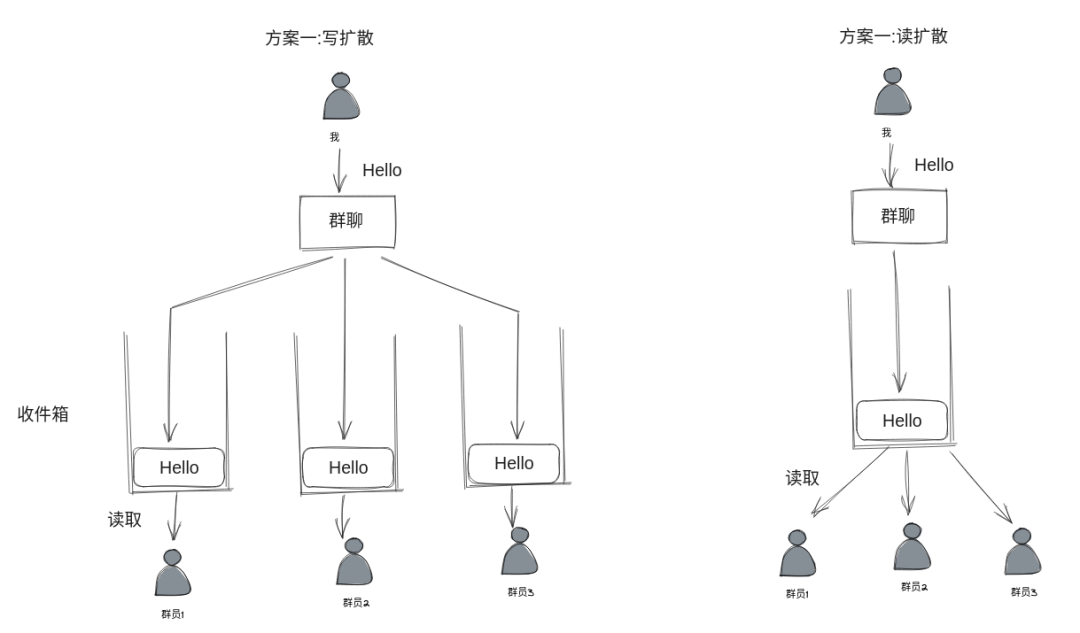
上文中用户消息订阅场景是读写扩散的经典案例,比如 IM 或者 微博/Twitter 的 feeds 流订阅。但是大多数业务应用场景都跟消息订阅不太一样,从数据库的规范化和反规范化角度来看,能帮我们进一步理解日常业务开发中的读写扩散。试想一个电商购物车系统的设计,根据购物车中商品信息的存储方式不同,我们又能得出两个方案。第一种方案, 在购物车表中只存储一个商品 ID,每次用户读取时, 用购物车表去 join 商品表 (或者等价的,在应用中通过 rpc 去调用商品系统查询),获得商品名称,价格等额外的商品信息。这种方案非常符合我们上学时学习的所谓数据库 “三大范式”,也称为数据库的 “规范化”。“三大范式” 主张每张表都是原子的,不能含有不属于该维度的冗余数据,读取时通过外键 join 来获取其他维度数据。所以“三大范式”对于写性能是非常友好的,但是读取却需要查询大量其他维度的数据,非常符合上面对于 “读扩散” 的定义。第二种方案, 在购物车表中冗余需要的商品信息,比如商品名称,商品价格等等,这样在读取时只需要读取这一张表即可。但是对于写入却是灾难,商品更新时,除了要更新商品表外,还要去更新冗余了商品信息的购物车表。这种方案和“三大范式” 理念相反, 所以被称为 “反规范化”,它通过写冗余数据,提升了读性能,非常符合上面对于 “写扩散” 的定义。"反规范化" 在互联网中越来越受到欢迎, 主要有两点原因:第一点是很多场景读多写少,比如商品信息可能每年才会更新一次,但是购物车却每时每刻都在读取,所以着力优化读取性能,牺牲一点写入也未尝不可。第二点是,很多新兴的 no sql 数据库为了提升水平扩展能力,都不再支持 join。它们主张一种叫做查询驱动(query-driven)的库表设计,即针对每一种查询视图,设计一张单独的表。比如针对购物车视图,我在 MongoDB 中单独新建一个集合,集合中的每个文档就是完整的购物车记录:在 MongoDB 中, "集合" 相当于一张 "表", "文档" 相当于表中的 "一行"
{ "id": "123456", "product": { "name": "康师傅方便面", "pic": "https://xx.jpg", "price": 2 }, "num": 10}
查询驱动(query-driven)这个词我最早是在 no sql 数据库 Cassandra 的 官方文档 [参考1] 中读到的, 这个词简洁地阐释了所有 no sql 数据库建模的本质。
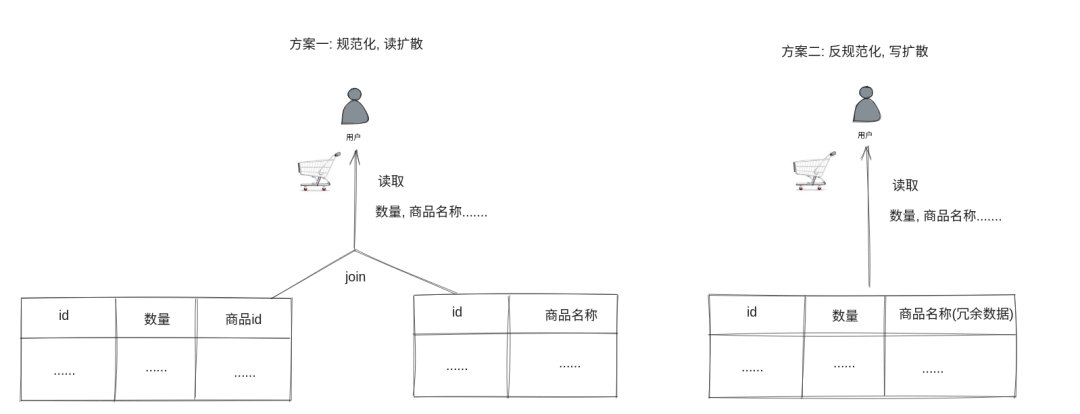
"规范化" 和 "反规范化" 也不是一个一刀切的概念, 随着冗余的数据越来越多 (比如我还额外冗余了用户的头像,这样就不用在购物车页面额外查询用户系统了),读性能会越来越好,写性能会越来越差。另外,对于糟糕的软件设计,读写性能会同时很差。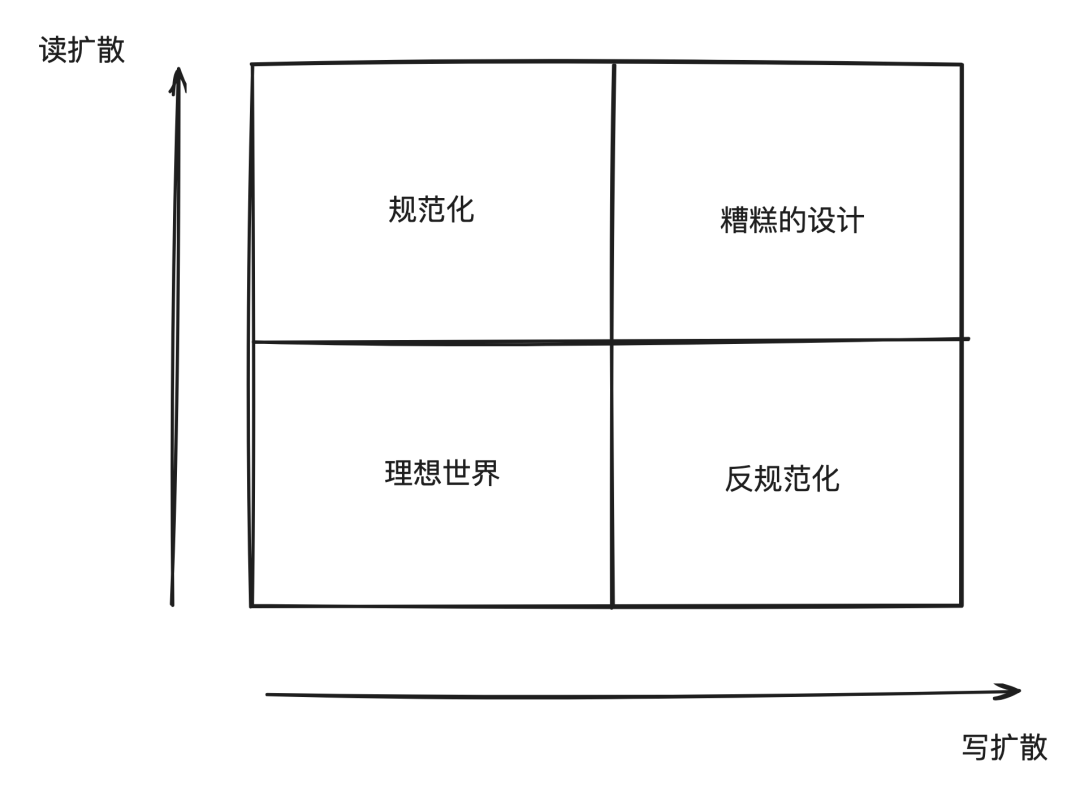
"读写扩散" 这个词其实有一定误导性,让人觉得设计一个架构,肯定不是 "写扩散",就是 "读扩散"。下文中我们发现不是这样,不存在绝对的 "读扩散" 和 "写扩散",任何架构设计都是 "读写路径" 的结合。我们先来试想一下 "绝对的写扩散" 是像什么样子。在 "绝对的写扩散" 中,读性能已经好了极致,而最好的读性能就是 "不读", 躺平等待推送: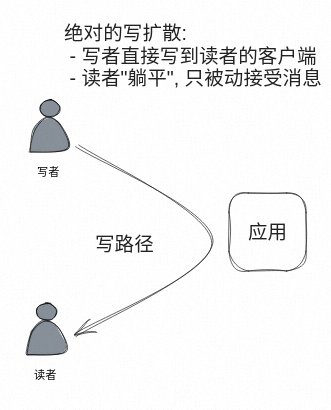
但是现实中没有人会这么做,首先读者客户端不一定总是在线给你写,所以开发者总是会找个地方先暂存下写入的内容,等读者上线后,再去读取。另外这么无节制地写入, 也容易超过读者自身处理能力上限,把读者写挂。所以现实架构中总是需要读者稍微做点 "努力" 去读取内容的,典型的就是消息队列的架构: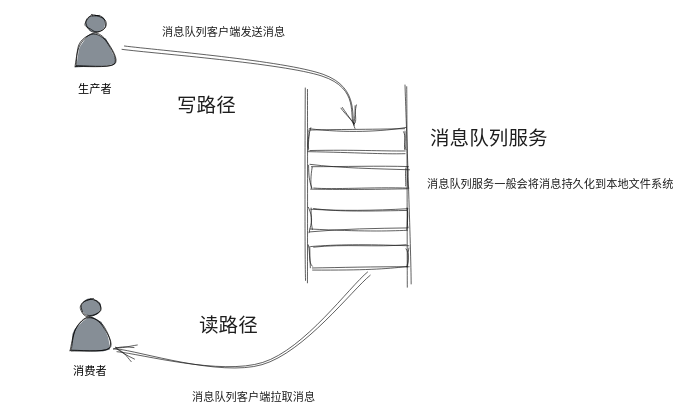
所以不管是有意还是无意,应用最后总是被设计成了读路径与写路径的结合,它们一般在某个持久化存储中交汇(比如数据库, 消息队列等等)。所谓 "写扩散",其实就是把写路径延长一些,读路径缩短一些。而 "读扩散" 相反,把读路径延长一点,写路径缩短一些。以钉钉考勤的统计页为例,用户可以在此查看不同周期内公司的打卡签到情况: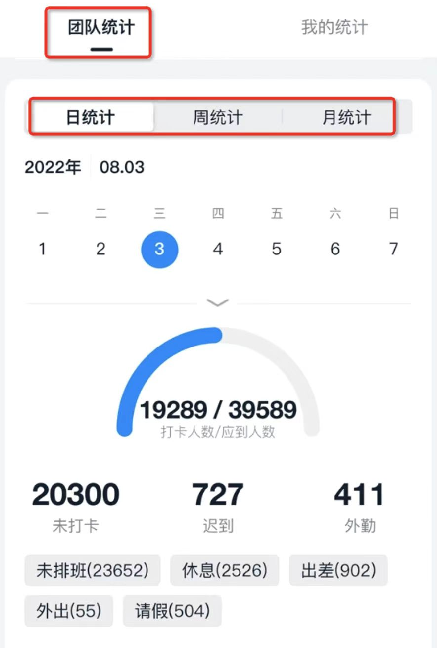
最初的方案是,每次用户打卡只存储一条打卡记录,然后在老板查看统计页时实时计算周期内的统计数据。这种方案虽然简单,但是每到月初业务高峰期,就产生大量的慢 SQL,有些企业打卡记录众多导致 Full GC。这个方案本质上就是一个 "读扩散",写路径很短,只需要写入一条打卡记录,代价就是读路径很长,需要做各种复杂的聚合统计。既然 "读路径" 太长,我们就可以通过延长 "写路径",来缩短 "读路径"。比如在每次用户打卡后,异步更新当前周期的统计数据,或者定期地离线计算不同周期的数据,这样就能大大降低读取的压力。从上面考勤例子可以看出,一般项目初期会先使用相对简单的 "读扩散" 方案,后期随着项目规模变大,遇到问题,才会采用适当的 "写扩散" 去解决问题。本节列举了几个我在业界和钉钉看到架构优化案例,希望在遇到类似场景时,能够快速有个参考。Twitter 有一个正在关注列表的功能, 能够按时间显示用户关注的人所发表的内容: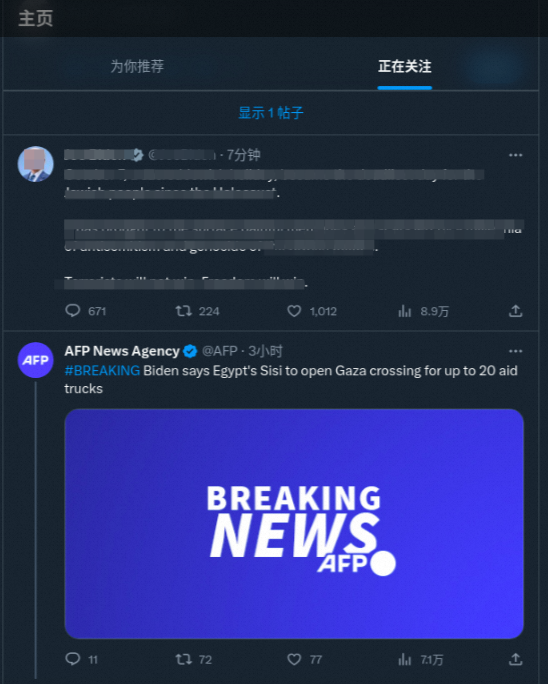
最初 Twitter 采用的也是简单的读扩散的方案,每个作者只会将推文写到自己的发表记录中,粉丝实时去发表记录表中读取所有关注者的推文,并且按时间排序。一开始这个方案不会有太大问题,但是后来 A 平台出现了很多大 V,大 V 的粉丝量非常多,而 Twitter 底层的分布式存储是按照用户 ID 来分区,这就造成大 V 所在分区的读热点。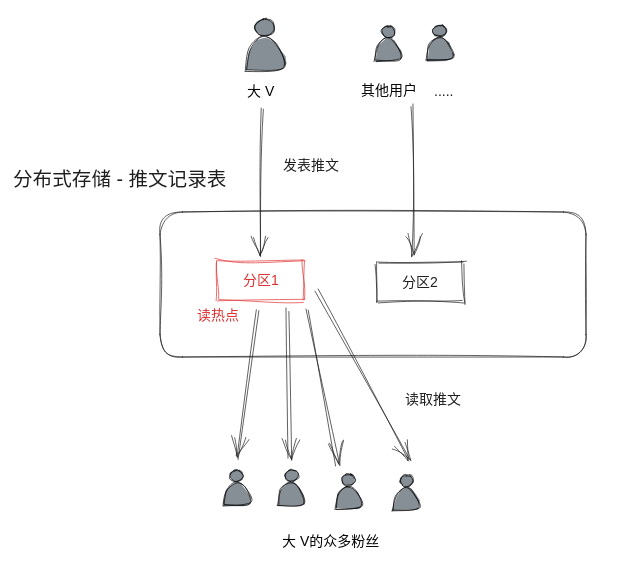
后来 Twitter 还是改造成了写扩散的方案,每个粉丝都有自己的收件箱,大 V 发表推文后,除了写到自己的发表记录中,还会异步地写入所有粉丝的收件箱。Twitter 的场景非常适合写扩散,原因在于: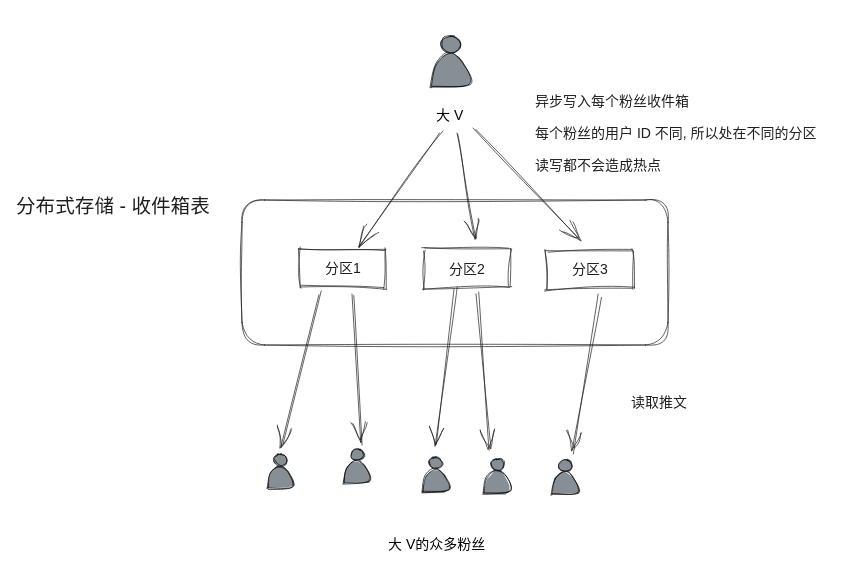
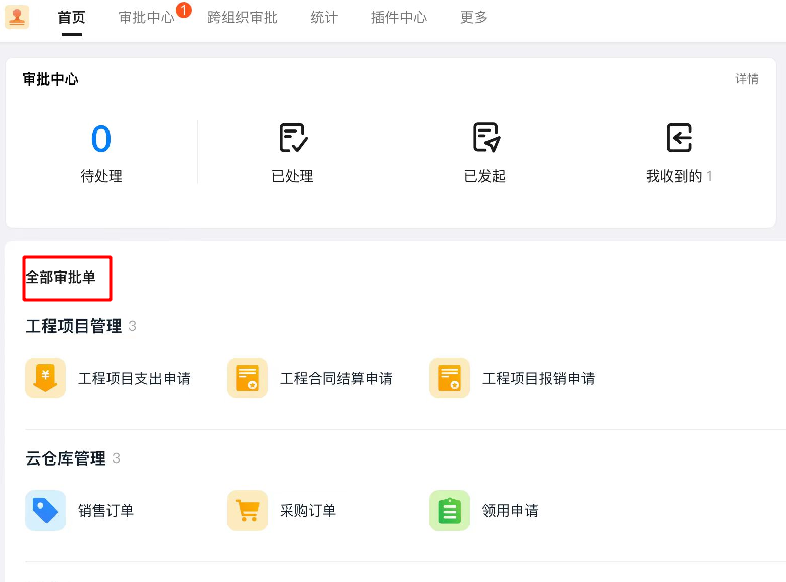
钉钉审批首页的 "全部审批单" 部分,会展示用户在该企业所有可见的审批单。然而审批单可见性取决的因素非常多:这就导致审批首页完全没法做分页查询,只能一次性把所有审批单查询出来,逐个判断用户是否可见,最后只把用户可见的审批单返回给用户,伪代码如下:List result = new ArrayList();List 所有审批单 = 查询企业所有审批单();for (审批单 : 所有审批单) { if (判断审批单对用户是否可见(用户ID, 审批单)) { result.add(审批单); }}return result;
可以看出读路径非常复杂,需要逐个审批单按照各种维度进行过滤,是典型的 "读扩散" 方案。当企业模板数量非常多时,首页的加载时间就会特别长,所以我们限制了企业的审批单模板数量不能超过 1000 个,对大企业非常不友好。
所以我们就计划采用写扩散进行优化,给每个用户推送自己的可见模板列表,在模板可见性变更时,再修改推送的内容。这样当用户读取时,分页查询就非常好做了。不过代价就是会造成大量的数据冗余,增加成本,一般方案都不会像上文写的那样简单直接,还会使用多种手段优化写扩散带来的数据冗余。后文中会再详细阐述,针对写扩散的缺陷,常见的优化思路。
工作台是钉钉的一个一级入口,因为钉钉的业务特点,有明显的流量毛刺,业务高峰期一瞬间的请求量能是平时的 3-4 倍,影响系统的稳定性。我们可以通过进一步缩短读路径来优化该场景。比如利用钉钉客户端的能力,缓存用户上次打开的工作台界面,等到用户再次打开,直接显示缓存的页面。然后请求服务端更新工作台,这个请求立即返回。如果服务端发现该用户的工作台需要更新,再根据自己的当前负载,以稳定的速率将更新内容推送给客户端,实现削峰填谷的效果。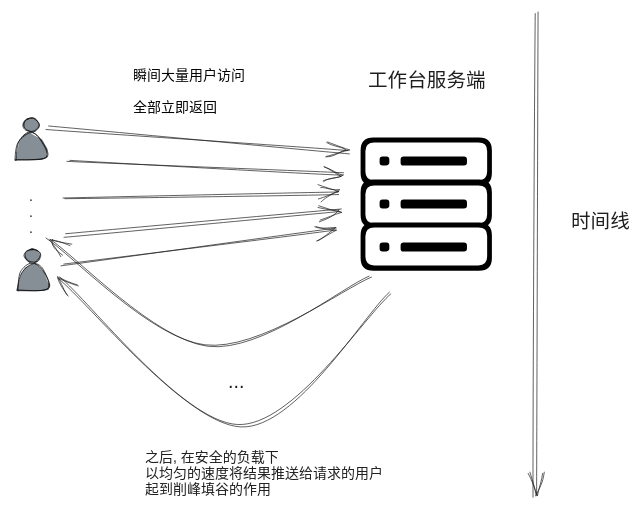
这个方案的缺陷就是,只适合那些能够支持服务端推送的客户端,比如钉钉。对于需要在浏览器打开的网页端应用来说,是无法实现的。
审批在提供基本的功能之外,为了方便用户使用,还支持按照关键字检索审批单。MySQL 中的数据结构无法满足灵活搜索的需求,所以业务上会冗余一份数据到专门的搜索引擎,搜索引擎采用搜索友好的倒排索引来存储数据,可以实现灵活搜索的需求。这里也体现了前文所述的查询驱动(query-driven)的设计原则,即每一份数据冗余存储,其实都是对应的一种数据查询视图。案例中就是专门冗余了一份数据到搜索引擎,来应对关键词检索的查询视图。不过这也给我们带来了多数据源一致性的问题,下文中会再讨论。上文为了方便理解,将写扩散的方案都描述得很简单,似乎就是多写几份数据,或者给每个用户推送一份数据。虽然大体思路就是这样,但是现实中的方案都要复杂很多,这些复杂性都是为了治理写扩散带来的数据不一致,延迟高,数据冗余等缺陷。写扩散虽然对于读取更为有利,但是写的性能也不能太差,所以冗余数据的写入常常是异步的。这就导致写者写完后,读者无法立马读到。这在分布式系统中叫做 读自己写(read-own-write) 问题。不过这对于大多数应用来说,这都不是什么问题,可以通过下面手段解决:基本上所有大规模应用都会碰到的问题,但是大家又不得不都做一遍这些老生常谈的保障:上面的案例中,写扩散总是从用户维度切入,给每个用户保存一份数据。不禁让人困惑,这数据量会不会太大了?而且大多数用户根本就不会进入这个页面,所以写入的大多数数据都是无效的。优化这两个问题的方法常被称做 "读写结合",本质就是在部分场景采用读扩散减少数据冗余,举几个例子:从上面的案例进一步总结,可以发现,我们甚至可以通过应用的读写扩散设计,看出业务当前的发展阶段:第一阶段:业务刚刚启动,还处于探索与试错期。应用倾向于使用读扩散方案快速迭代试错。
第二阶段:业务已经确定可行,很快就进入了快速规模增长期。之前快速迭代留下的坑,都随着规模增长一一暴露。之前读扩散的方案已经很难满足业务要求,架构治理迫在眉睫,开发者们就会使用各种写扩散的技术优化性能,以支持快速增长的规模。
第三阶段:业务的规模已经达到天花板,进入 业务瓶颈期。之前因为规模和营收还在快速增长,所以写扩散带来的存储成本,看起来没什么。但是到了业务瓶颈期,写扩散带来的成本,已经没法带来相应的规模增长了。此时很多开发者们的 OKR 都会变成 “降成本”, 读扩散的方案因为存储成本低,在很多场景又会被重新提出,最终变成 “读写混合” 的方案。
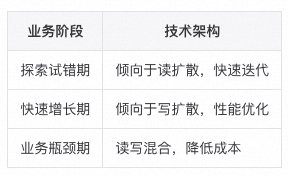
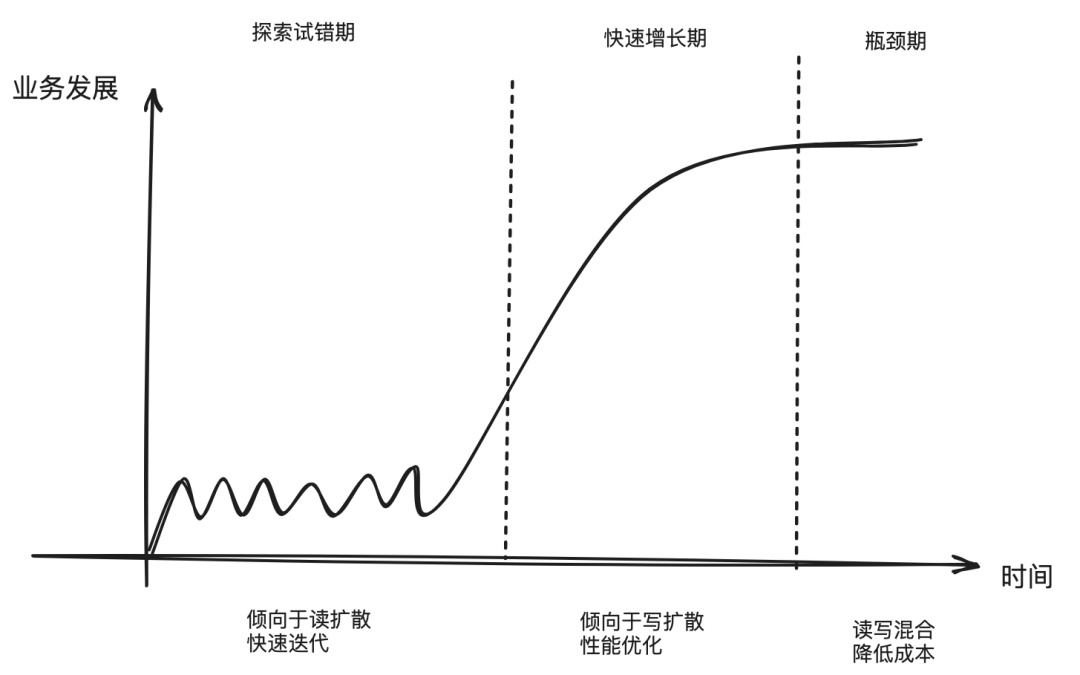
上图只是对于一个成功业务的一般情况,现实情况会更加复杂,可能有很多业务在探索期就死了,或者有的业务瓶颈不高,即使在瓶颈期,也可以通过读扩散和加机器硬撑下去。
所以有句话说的没错,“应用架构也是业务现状的一个反映”。参考资料:
[参考1] : Cassandra 数据库官方文档:https://cassandra.apache.org/doc/latest/cassandra/data_modeling/intro.html?spm=ata.21736010.0.0.20207d51bUhe0F
这是一个专门面向“阿里云开发者”公众号的读者交流空间💡 在这里你可以探讨技术和实践,我们也会定期发布群福利和活动~欢迎扫码或者添加微信:argentinaliu 加入我们👇