---- 本周为您解读 ④ 个值得细品的 AI & Robotics 业内要事 ----
1. 苹果与众不同的 LLM-based-Agent 路线将对具身智能掀起怎样的风暴? 苹果也训具身 Agent 了?用 LLM 做 VLM 的 policy 会更好用吗?把 LLM 和强化学习串起来训 Agent 的操作了解一下?苹果的训出的 Agent 更强吗?...大模型推理成本到底有多高?成本结构是什么样的?为什么公司都在关注大模型推理优化技术?大模型推理优化有哪些主流技术?近期有哪些好用的大模型推理、部署、优化方面的新技术方案?... 3. 英伟达 MimicGen 生成的机器人数据比人类收集的还好用? MimicGen 了解一下?MimicGen 生成的数据质量有多好?MimicGen 生成数据训的机器人有多强?MimicGen 学习人类不挑对象?... 4. 全球首个人工智能贡献榜重磅发布,哪些华人研究者榜上有名? 自1943年起,人工智能领域有哪些代表性成果?哪些华人研究者上榜了人工智能领域百年人才榜?他们都有哪些代表性工作?国家榜中,中国位列第四,前三是谁?......本期完整版通讯含 4 项专题解读 + 33 项本周 AI & Robotics 赛道要事速递,其中技术方面 12 项,国内方面 10 项,国外方面 11 项...
本期通讯总计 24075 字,可免费试读至 5 % 消耗 99 微信豆即可兑换完整本期解读(约合人民币 9.9 元) 要事解读 ① 苹果的 LLM-based-Agent 要如何掀起具身智能风暴?
事件:苹果的研究者近期提出了一项「大型语言模型强化学习策略(LLaRP)」,可融合在线强化学习将 LLMs 应用于复杂多变的具身智能任务,其任务成功率为已有基线或零试(zero-shot)应用的 1.7 倍。1、苹果的研究者近期发布论文,表明大型语言模型(LLM)可以适配为用于具身视觉任务的泛化策略。2、该工作提出了大型语言模型强化学习策略(Large LAnguage model Reinforcement Learning Policy ,LLaRP),它将预训练的冻结 LLM 适配为直接在环境中以文本指令和视觉自我中心观察为输入,并在环境中输出行为动作。① 其中,研究者通过强化学习训练 LLaRP 只通过环境互动来观察和行动。3、通过使用 LLMs 作为视觉-语言模型(VLM)策略,以及在线强化学习训练,LLaRP 对复杂的任务指令解析具备稳健性,并且可以泛化新任务中。① LLaRP 在 1000 多个未见过(unseen)的任务测试中实现了 42%的成功率,优于基于 LSTM 的策略(25%)和零试 LLM 应用(22%)的表现。② 研究者还展示了 LLaRP 在雅达利游戏中与基于 Transformer 的基线的能力对比,同样具备性能的提成。4、此外,研究者开发了一项称为「语言重排(Language Rearrangement)」的基准,用于帮助社区研究语言条件下的大规模多任务具身智能问题。① 该基准包含 150,000 个训练任务和 1,000 个测试任务。表: 在综合语言重排零试条件测试中,LLaRP 的表现优于所有其他基线[1]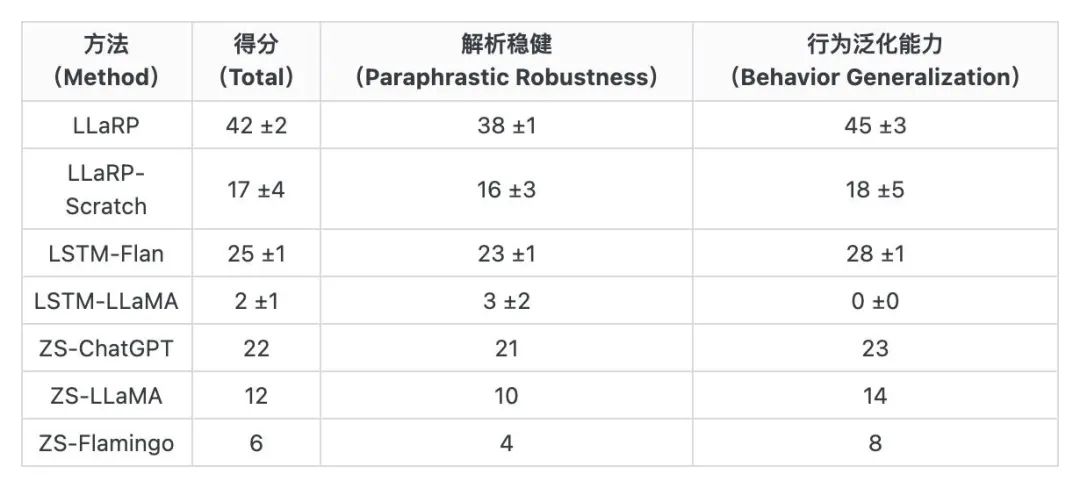
苹果为什么要研究 LLM-based-Agent?[1]在论文《Large Language Models as Generalizable Policies for Embodied Tasks》,苹果的研究者阐述了大型语言模型的能力和所具备的潜力,及其在具身智能领域所面对的挑战。1、大型语言模型(LLMs)已经证明了它在语言理解方面的潜力。现有的 LLM 工作不仅在语言理解的核心问题上得到突破,还在对话系统、视觉理解、推理、代码生成、具身推理和机器人控制等多个领域得以应用。2、泛化能力: 现有 LLMs 显示出可以无需特定于每种能力的训练数据,即可泛化到多个领域的能力。这表明 LLMs 内含的知识广泛且通用,即使是在非自然语言表达的输入输出空间(例如图像和机器人命令)也能展现这些能力。3、具身智能挑战: 具身智能的关键目标之一是开发出能够泛化到新任务的决策制定能力,但现有工作仍存在诸多挑战。① 虽然 Agent 能够学习自然语言描述的任务,如部分工作依靠模仿学习,使用专家轨迹(trajectory)和语言对的数据集来训练语言条件策略,但相似的工作主要关注在扩大数据集,以及增加模仿学习的数据多样性。4、视觉语言模型(VLMs)的研究整合了预训练 LLMs 和视觉推理,但仍存在局限。① 有些工作为 VLMs 增加 3D 空间信息,但通常是在静态的、无环境互动的情境下;② 有些工作则将 VLMs 扩展到视觉具身环境中的交互式决策,但是这些研究依赖于高质量的专家数据。③ 具身智能模拟环境(simulators)可以让 Agents 通过与环境互动、探索和奖励反馈来学习,但这些 Agents 在新的具身任务中的泛化能力与上述领域相比仍有差距。5、当前没有工作展示 LLMs 中的语言知识可以用于在线 RL 问题,并用于改善具身智能 Agent 的泛化能力,苹果的研究者为此通过多样化的评估集来探索这种能力,在关注语言(释义泛化)的同时,也关注环境/目标行为的变化。论文中,研究者阐述了 LLaRP 如何将预训练的 LLMs 适配到多模态具身决策环境中,从而开发出在新的语言指令上具有显著泛化能力改善的 Agent。