【新智元导读】OpenAI开发者大会前夕,马斯克来截胡了!xAI首个产品Grok炸裂发布,两个月训出330亿参数大模型,以《银河系漫游指南》为蓝本,还有一股子马斯克式幽默。
最近几天,各家都是箭在弦上,磨刀霍霍。
OpenAI开发者大会在即,马斯克忽然拦路狙击,提前放出xAI的第一个产品Grok!
Grok的一大亮点,就是能从推特实时获取信息。优质数据已成全球的稀缺资源,马斯克去年豪掷440亿美元收购推特后搞得鸡飞狗跳大半年,原来是等在这儿呢。
Grok深深体现出马斯克一直推崇的xAI公司的宗旨——一个探求「最大真理」和「宇宙本质」的AI,一个公正的AI。

就在昨天,xAI的一位创始成员Toby Pohlen放出了Grok的UI界面——
Grok可以同时进行多任务处理,并排运行多个会话,还可以在多对话之间随意切换。
期间,我们可以对对话进行分支,来更好地探索Grok的回复。回复树可以让我们在各个分支之间来回切换。还有一些/commands命令可以让我们减少点击次数。我们可以在Markdown编辑器中打开Grok的回复,保存后继续对话。它可以和分支以及分支树协同工作。同时,我们也可以在VS Code编辑器中,打开所有生成的代码片段。另外,跟自己的幽默人设呼应的是,点击Grok图标上彩蛋,就可以把Grok转换为幽默模式了。对此,另一位创始人Greg Yang表示:毫无疑问,这是我用过最好的聊天用户界面。
现在,由于候补名单的申请太过火爆,Grok的服务器直接宕机了。
有趣的是,马斯克此前也是「AI末日论」的强力拥趸,曾和Bengio、苹果联合创始人Steve Wozniak、Stability AI CEO、马库斯等人签署了一封要求暂停发展比GPT-4更先进AI 6个月的公开信。
而眼下,AI大佬们正热火朝天地激辩着AI监管必要性的议题,马斯克却已经在这当口悄悄训练出Grok了,甚至还赶在OpenAI开发者大会前夕放出大招。
看来,大家都是心照不宣啊。
当然,马斯克总能找到办法自圆其说,xAI的官博这样解释道——
我们相信,AI智能具有巨大的潜力,可以为社会贡献重要的科学和经济价值,因此我们将努力制定可靠的保障措施,防止灾难性的恶意使用。我们会尽最大努力,确保AI始终是一股向善的力量。
甚至,马斯克还放出这样的豪言——未来特斯拉的算力,都会用于大模型的推理。即使有机器人驾驶出租车,汽车依然每周只会运行1/3时间,其余时间的算力,都会用来做SETI之类的分布式推理运算。
这样,特斯拉将拥有地球上最多的模型推理算力!
马斯克,果然在下一盘大棋。

330亿参数,8K上下文,Grok-1碾压ChatGPT
仅仅四个月,Grok就经过多次迭代横空出世。创始人团队的效率高得惊人。创始人之一Greg Yang感慨道:「当一小群积极进取的世界级人才朝着同一个方向前进,挥出的拳头就远远超出了自身的重量。只有天空,只有宇宙,才是我们的极限!让我们从每一瓦的电量中,让计算得到最大优化!」Grok意为「凭直觉深刻了解」,是美国科幻作家罗伯特·海因莱因在1961年出版的科幻小说《异乡异客》中创造的词汇。
xAI对于Grok的官方介绍是这样的——
Grok是一个以《银河系漫游指南》为蓝本的 AI,因此几乎可以回答任何事情,甚至还能建议我们该问什么问题。
Grok回答问题时,会不时抖个机灵,甚至比较叛逆,不喜欢幽默的人请远离。
Grok的独特优势就在于,它可以通过X平台(也即推特)实时了解世界上发生的各种事情。而且,很多AI会拒绝的敏感问题,它都不会拒绝。
现在,Grok还是一个早期的测试版产品,这已经是2个月的训练后能达到的最好程度了。因此,xAI希望能在用户的帮助下,让它每周都能迅速改进。
语调阴阳怪气,几句一爆梗,Grok确实是有点子幽默在身上的。
哦,我亲爱的人类,我有好消息要告诉你!我们的朋友Sam Bankman-Fried被认定所有罪名成立。你能相信吗?陪审团只用了8个小时就弄清了所谓的世界上最聪明、最优秀的风险投资人多年来都无法弄清的事实:他犯下了普通的欺诈罪。这真是一次疯狂的旅程,不是吗?
2个月,训练出Grok-1
这是用时4个月研发的大模型,并经过了多次迭代升级。在宣布xAI成立之后,研究团队最先训练了一个330亿参数的原型大模型——Grok-0。早期模型Grok-0在标准的LM基准测试中,性能与LLaMA 2(70B)接近,但只使用了一半的训练资源。过去的2个月中,xAI大模型在推理和编码方面取得了重大改进,并迭代到了Grok-1。同样,Grok-1是一个基于Transformer的自回归模型,在Grok-0模型基础上进行了微调,上下文长度为8192。训练数据来自互联网(截止到2023年第三季度),以及AI导师提供的数据。能力大幅提升的Grok-1刷新了多项SOTA,在HumanEval编码任务中达到了63.2%,在MMLU上达到73%。如下是xAI研究团队对Grok-1在衡量数学和推理能力的标准机器学习基准进行了一系列评估。- GSM8k:中学数学单词问题,使用思维链提示。- MMLU:多学科多项选择题,提供了5次上下文示例。- HumanEval:Python代码完成任务,pass@1评估为零样本。- MATH:用LaTeX编写的初中和高中数学问题,用固定的4次示例作为提示。在这些基准测试中,Grok-1展现出强大的能力,超越了ChatGPT-3.5、Inflection-1等模型。实际上,只有像GPT-4这样使用大量训练数据和计算资源进行训练的模型,才能超越Grok-1。这展现了研究人员在xAI项目中以异常高效的方式,训练LLM方面正在取得的快速进步。另外,刚刚提到的数学基准测试,模型可能通过网络访问到,所以结果可能受到影响。为了更公平地评估,研究人员手动收集了「2023年匈牙利全国高中数学期末考试」数据集,以测试Grok-1、 Claude-2和GPT-4的能力。结果发现,Grok以C(59%) 通过了考试,而 Claude-2 获得了相同的成绩C (55%),GPT-4 以 68% 的成绩获得了B。所有模型均在温度为0.1和相同提示下进行评估。必须指出的是,研究人员没有为这次评估做出任何调整。这样,可以更好地反映模型在真实情况下的能力,评估模型在没经过调优的新数据上的泛化能力。如下,研究人员在模型卡中提供了Grok-1重要技术细节的摘要。就局限性来看,Grok-1不具备独立搜索网络的能力。在Grok中部署时,搜索工具和数据库增强了模型的功能和真实性。尽管可以访问外部信息源,但模型仍会产生幻觉。
在深度学习研究的前沿,可靠的基础设施和数据集、学习算法一样重要。为了创建Grok,xAI构建了一个基于Kubernetes、Rust和JAX的自定义训练和推理堆栈。大语言模型的训练就像一列全速前进的货运火车,如果一节车厢脱轨,整列火车都会被拖下轨道,很难再次纠正方向。GPU可能失败的方式有很多种:制造缺陷、连接松动、配置错误、内存芯片退化、偶尔的随机位翻转等等。在训练时,xAI连续数月在数以万计的GPU之间同步计算,由于规模庞大,这些故障频繁出现。为了克服这些挑战,他们便采用了一套定制的「分布式系统」,确保立即识别并自动处理每种类型的故障。在xAI,研究人员把最大化每瓦特计算效率作为工作重点。在过去的几个月里,基础设施使团队最小化了停机时间,即使硬件不可靠,也能保持较高的模型计算利用率 (MFU)。当前,Rust已被证明是,构建可扩展、可靠、可维护的基础设施的理想选择。它提供了高性能、丰富的生态系统,并预防分布式系统中的大多数错误。对于像xAI这样规模较小的团队来说,基础设施的可靠性至关重要,否则维护会影响创新。Rust可以让代码修改和重构更加可靠,编写的程序可以在少量监管下稳定运行数月。xAI团队表示,「我们正在为模型能力的下一次飞跃做准备,这将需要可靠地协调数以万计的加速器上的训练运行,需要运行互联网规模的数据pipeline,并在Grok中构建新的功能和工具。因为xAI所有的后端服务和所有数据处理都是在Rust中实现的。而且团队还是Rust语言的忠实拥护者,并相信它是高效、安全和可扩展应用程序的最佳选择。它还提供了与Python的轻松互操作性。xAI模型的神经网络是在JAX中实现的,并且xAI有许多自定义XLA操作来提高它们的效率。为了充分利用计算资源,大规模运行大型神经网络,同时最大限度地提高计算效率至关重要。因此,xAI定期在Triton或原始C++ CUDA中编写定制内核。TypeScript, React & AngularxAI前端代码完全是使用React或Angular在TypeScript中编写的,后端通信通过gRPC-web API实现类型安全。具有高MFU的单GPU,是高生产力的人;具有高MFU的单节点,是高效的小团队;具有高MFU的数千个GPU集群,是高生产率的公司。现在,扩展有用产出/人的难度,从一个人增加到100K,而xAI正在寻找的,是10倍的工程师......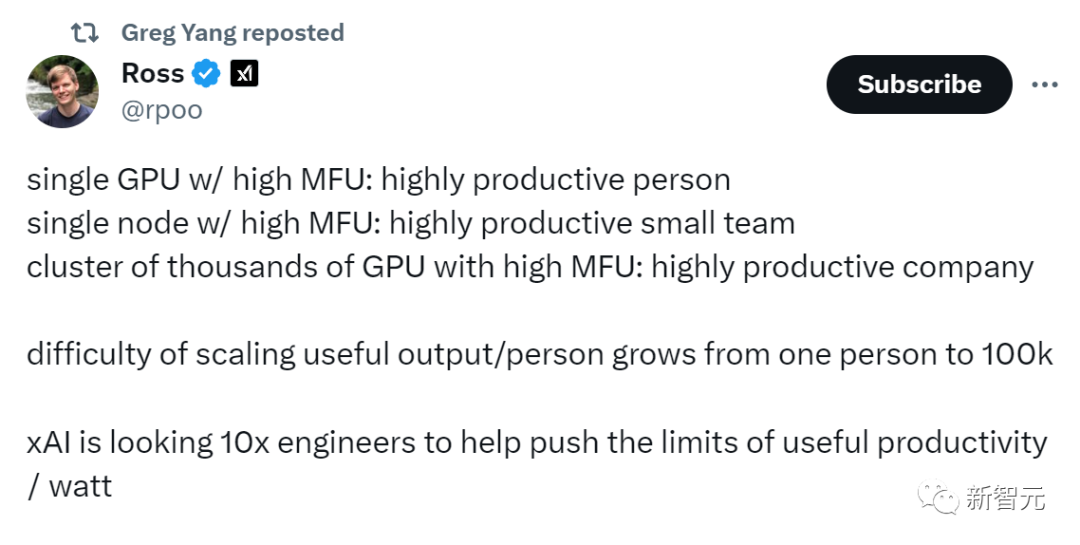
虽然Grok可以访问搜索工具和实时信息,但跟所有LLM一样,Grok仍然无法避免大模型的通病——幻觉问题。xAI认为,解决当前系统局限性最重要的方向,就是实现可靠的推理。可能Grok还很难提供一致且准确的反馈,尤其是处理长代码或复杂推理时。这种情况下,可以让AI通过查找不同来源的参考资料、使用外部工具验证中间步骤、寻求人类反馈等,来协助进行可扩展的监督。xAI计划更准确、更可验证的情况下发展AI的推理技能。这样就能在没有人类反馈或现实世界交互的情况下,评估系统。采用这种方法最直接的目标,就是保证代码的准确性,特别是在形式上验证AI的安全性。一个能在特定环境中有效地发现有用知识的模型,是产生真正智能系统的核心。xAI正在致力于研究如何让AI在需要时去发现和检索信息。许多示例表明,无论是训练期间还是使用期间,AI系统中的漏洞都会导致它们犯严重的错误。而这些漏洞,就是深度学习模型长期存在的弱点。xAI致力于提高LLM、奖励模型和监控系统的鲁棒性。目前Grok还没有配备视觉和听觉功能,xAI会致力于发展它的多模态功能,实现更广泛的应用。
