机器之心专栏
作者:李永彬、惠彬原、黄非
团队:达摩院-自然语言-对话智能团队
如何将人类先验知识低成本融入到预训练模型中一直是个难题。达摩院对话智能团队提出了一种基于半监督预训练的新训练方式,将对话领域的少量有标数据和海量无标数据一起进行预训练,从而把标注数据中蕴含的知识注入到预训练模型中去,打造了 SPACE 1/2/3 系列模型。
- SPACE-1:注入对话策略知识,AAAI 2022 长文录用;
- SPACE-2:注入对话理解知识,COLING 2022 长文录用,并获 best paper award 推荐;
- SPACE-3:集对话理解 + 对话策略 + 对话生成于一体的模型, SIGIR 2022 长文录用。
达摩院对话大模型 SPACE-1/2/3 在 11 个国际对话数据集取得 SOTA。
图 1 SPACE 系列模型在 11 个国际对话数据集取得 SOTA,包含 Intent Prediction、Slot Filling、Dialog State Tracking、Semantic Parsing、End-to-End Generation 五大类对话任务- SPACE-1: https://arxiv.org/abs/2111.14592
- SPACE-2: https://arxiv.org/abs/2209.06638
- SPACE-3: https://arxiv.org/abs/2209.06664
- 相关代码:https://github.com/AlibabaResearch/DAMO-ConvAI
人机对话的终极目的是让机器(对话系统)和人类(用户)能像人和人一样进行自由的对话。通常来说,对话系统和人类的对话过程主要分为三个主要阶段,分别是对话理解(Understanding)、对话策略(Policy)和对话生成(Generation)。如下图所示,当用户说了一句 "查询水费",对话系统首先要理解用户说的是什么意思(What do you say ?),然后要根据理解的结果,需要判断自己该如何去回答(How Shold I say ?),第三步要通过自然语言的方式返回给用户(What should I say ?)。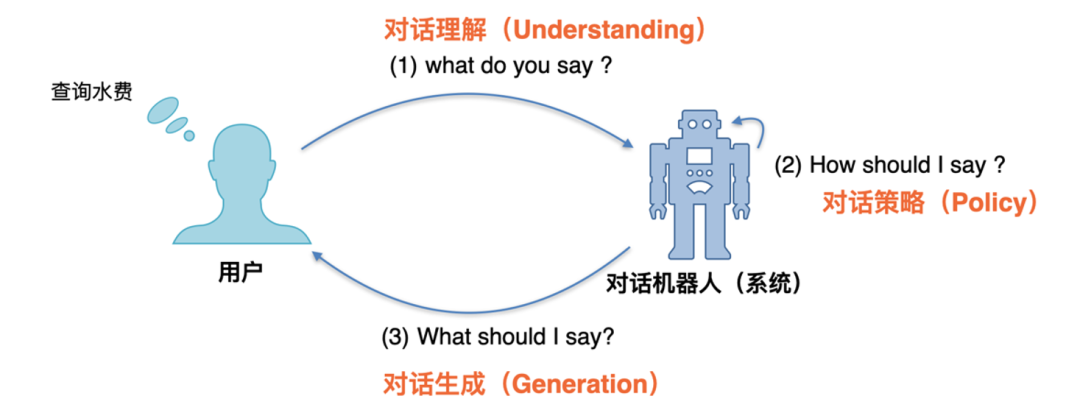
人机对话都是基于知识构建起来的,即“无知识,不对话”。目前的对话系统大概可以分为三个类别,包括对话、问答和闲聊。对话主要是指任务型对话,通过具体的业务流程知识来构建,围绕一个流程完成某个具体的任务;问答根据知识形态的不同,分为了很多种,比如基于知识图谱的问答(KBQA)、基于表格或者数据库的问答(TableQA)、基于文档的问答(DocQA)等;闲聊主要是利用一些开放域知识,完成与人类的聊天等。除此之外,所有的对话都可能会依赖人类标注的知识、世界知识和各种常识等。
举个例子,比如在办理汽车保险的场景中,相关的多轮对话受业务逻辑流程约束的:首先需要验证个人信息,然后系统调用验收报告,如果验收报告通过,接下来就要填写保单,最终完成保险的办理;如果验车不通过,需要反馈给用户原因,最终完成整个对话的流程。在这个例子中,对话流程体现的是业务流程知识;需要验证的个人信息包括姓名等,依赖于世界知识,比如姓名中的“弓长张木子李”;最后,这个项目如果想达到交付效果要求,还需要标注训练样本训练模型,这里面就包含人工标注知识。近些年来,预训练模型引爆了 NLP 的技术变革,比如 BERT[1]、GPT[2]、T5[3] 等。这些模型基于自监督的训练方式(MLM)在大规模无监督语料上进行学习,而其背后的本质是语言模型(Language Model),回答什么样的句子更像一个合理的句子。典型的预训练语言模型主要由三个主要组件构成 :(1) 海量的自由文本作为输入 (2)利用 Transformer [4] 网络架构作为模型 (3)通过自监督的预训练目标 MLM 作为优化目标。 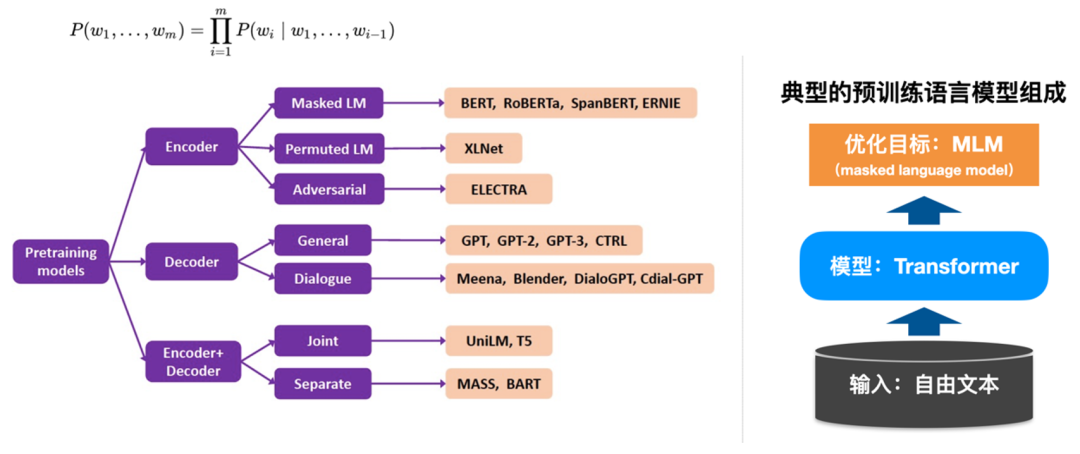 图 4 预训练语言模型及其组成
图 4 预训练语言模型及其组成
但是对话数据和普通文本数据有非常显著的差异,相比于普通的文本数据,对话作为语言的高级应用,至少有如下的特点:- 对话是口语化的,人在对话的时候表述随意,也不一定符合语法,可能存在噪音及 ASR 错误;
- 对话是分角色多轮次的,至少有两个参与主题,轮次间存在省略、指代、状态继承等特点;
- 对话需要深层语义理解,比如涉及到意图槽位,逻辑推理等;
- 对话是讲究策略的,为了完成特定的任务目标,模型需要知道自己该如何决策。
直接利用预训练语言模型作为对话模型的基座存在天然的不适配,我们需要针对对话的数据及特点,设计独特的对话预训练模型,来增强对话系统的效果。从 2020 年开始,面向对话的专用预训练对话模型开始涌现。目前预训练对话模型的建模,基本按照对话理解和对话生成两大任务类进行建模,利用类似于 BERT 或者 GPT-2 的 loss 在对话语料上进行预训练。例如,针对话理解,常见模型有 PolyAI 的 ConvRT [5],Salesforce 的 TOD-BERT[6]和亚马逊的 ConvBERT[7],针对对话生成,常见模型有微软的 DialoGPT [8],谷歌的 Meena[9]和 Meta 的 Blender[10]。这些预训练对话模型仍然存在很多不足:
综上,一方面,无知识不对话,知识是对话的基础;另一方面,预训练对话模型对于对话系统是刚需。基于此,我们希望在数据和知识双驱动的预训练对话模型方向上进行深入探索。2. SPACE-1: 从 自监督训练 到 半监督训练如何向模型中注入标注知识依旧是一个尚未充分探索的方向。早期工作中,谷歌的 T5 就已经尝试了将有标和无标数据统一成语言生成任务进行学习,但是实验却表明简单地混合有标无标数据训练反而会带来负面影响。经过大量的实验探索,我们发现如果还是基于原先的两大预训练范式,难以很好地进行预训练。首先,单利用自监督预训练或者有监督预训练是无法同时利用好有标和无标的预训练数据,仅自监督损失函数是无法学习出标注知识中的高层语义的,有监督损失函数亦不能学出无标语料中的通用底层语义;其次,在大规模预训练中,由于所使用的预训练数据往往存在着少量有标数据和海量无标数据之间的数量鸿沟,如果简单混合两种预训练,会使得标注知识的信息要么淹没在无标数据中,要么就会出现严重的过拟合,因此我们需要全新的预训练范式来解决该问题。基于上述动机,我们期待能够通过一种新的训练方式,将人类知识注入到预训练对话模型中。这里我们提出半监督预训练对话模型 SPACE (Semi-supervised Pre-trAined Conversation ModEl) 。如下图所示,半监督预训练从迁移学习的角度来看,可以认为是一个前两种范式的自然延伸,通过构造半监督学习的损失函数来充分综合利用有限的标注知识和大量的无标数据。在半监督学习理论里 [11],模型既需要在无标数据上进行自我推断,根据结果进一步约束优化,也需要利用有标数据进行一定程度的有监督,指导自监督预训练的过程,同时避免模型参数陷入平凡解。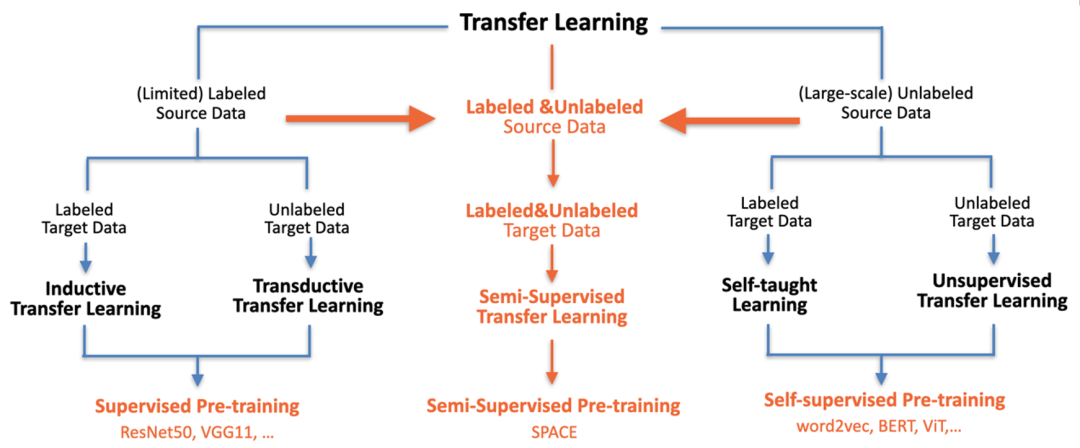
图5 三种预训练方式:有监督、自监督及半监督,参考[16]修改 如下图所示,传统的半监督学习主要是通过无标注数据来辅助有标注数据,从而减少学习所需要的标注样本量。而我们关注的不再是如何降低对标注数据量的依赖,而是如何更加高效地融入特定标注知识。 图 6 我们提出的半监督预训练与之前半监督的不同点
图 6 我们提出的半监督预训练与之前半监督的不同点
半监督预训练是我们 SPACE 系列模型的核心思路,基于这个思路,我们该从哪个方向进行探索呢?当前的预训练对话模型主要可以分为对话理解、对话策略、对话生成几个方向,对话理解和对话生成都有一些相关的工作了,而对话策略的研究却比较薄弱,但对话策略又是连接对话理解和对话生成的核心环节,它指导着对话生成的正确性,同时对于多轮对话能否完成目标(对话完成率)也至关重要。所以我们先从对话策略进行入手,将策略知识注入到预训练对话模型中。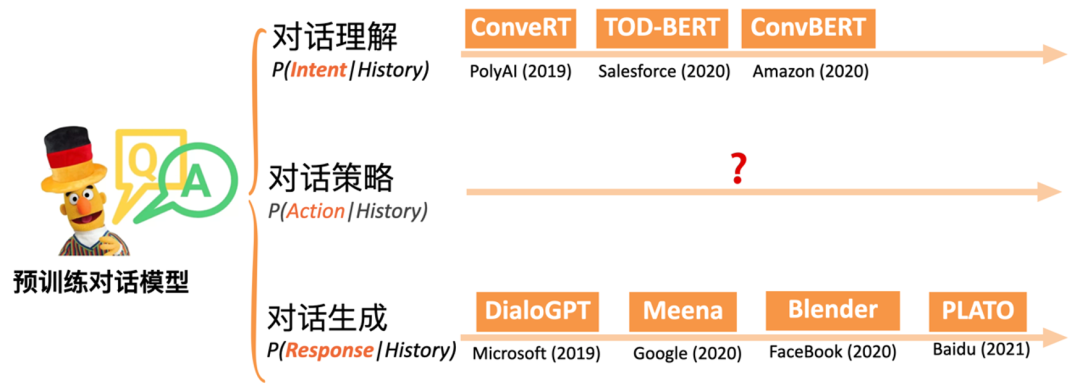 图 7 针对对话策略的预训练对话模型还处于空白
图 7 针对对话策略的预训练对话模型还处于空白
什么是对话策略呢?对话策略最早是 1995 年在语言学被提出,用来对人类的语言交流进行行为建模的,将对话动机或者对话行为抽象为具体的类型,在 wiki 百科中的解释为 “A dialog act is a tag for an utterance, in the context of a conversational dialog, that serves a function in the dialog”。随着领域的发展,人机对话也开始采取这种标签体系,称之为 dialog act (DA),比如哥伦比亚大学的 Zhou Yu 老师团队提出以用户为中心的 DA 体系,一共 23 个 DA 标签,凭借这套对话策略的标签,拿下了当年的 Alexa Prize 的冠军,证明了这种策略知识对于人机对话任务也是非常重要的。
图 8 对话策略(Dialog Act)的发展历史但是目前的 DA 标注体系都比较零散,每个研究的标注体系都不相同,毕竟用一个小规模的、具体的集合来描述整个人类的语言描述,还是非常有挑战的。为了推进这个方向的研究,我们将学术界面向任务型对话的策略体系进行了整合,最终梳理出 5 大类、20 小类的统一标签体系。最终我们打造出最大的统一 DA 的对话数据集 UniDA,共计 100w 条 utterance,同时我们还整理了学术界所有的大规模无标注语料 UniDIal,共计 3500w 条 utterance。
图 9 我们总结出的 DA 体系,基于此梳理发布了学术界最大的统一 DA 的对话数据集 UniDA目前我们已经整理好了用于预训练的知识和数据,接下来需要考虑如何设计模型。首先我们将对话策略进行显式建模,给定对话历史,直接预测下一轮系统端的 DA 标签。比如下面这个例子,用户首先说 “帮我查一下上个月的水费”,机器人说“好的,请问你的户号是多少?” 然后这个用户就会把他的水卡的号说出来。那么再下一句,机器人应该说什么呢?我们要预测机器人的这个对话策略,就是选择继续询问,或者选择回答信息,还是要进行澄清,这些行为就是模型就要预测机器人的这个对话策略。那么这样一个预测的过程,可以直接建模为分类问题进行处理。
如何将这个分类问题进行半监督训练呢?目前学界对于半监督的利用主要分为 3 种:基于判别式的方法,比如 self-prediction、co-training 等;基于生成式的方法,比如 VAE、GAN 等,还有基于对比学习的方法,比如 有负样本的对比和无负样本的对比。其中,在我们的实验中,基于判别式(self-prediction)和生成式(VAE)由于缺乏显式的 loss 约束及隐变量的不确定性,效果都不尽人意。
我们最后选择基于对比学习的半监督训练方法。具体的,针对无标对话数据,我们采用了 R-drop[12] 的思路,如下图所示,给定同样的对话输入 c(context),经过两次带有 dropout 的 forward 得到了两次经过随机扰动后在对话动作空间 (DA)上预测的不同分布,然后通过双向 KL 正则损失函数(L_KL)来约束两个分布。针对有标对话数据,我们则直接利用基础的有监督交叉熵 loss(L_DA)来优化对话动作预测。理论可以证明,在满足低密度假设下(即分类边界处于低密度分布),通过对同一个样本进行扰动后分类结果仍然具备一定程度上的一致性 (即分布接近或预测结果接近),那么最终基于一致性正则的半监督学习可以保证找到正确的分类面。最终模型的预训练损失将和回复选择任务(L_select)和回复生成任务(L_gen)进行联合优化。
最终 SPACE-1 借助半监督注入策略知识的能力,在这些经典的对话榜单上均大幅超过了之前的 SOTA 模型,端到端混合分数在 In-Car,MultiWOZ2.0 和 MultiWOZ2.1 分别提升 2.5、5.3 和 5.5 个点:
图 13 SPACE-1 在 MultiWoz 2.0 等数据集上带来显著提升以上的结果充分证明了半监督预训练的效果。进一步详细分析如下图所示,Success 是对话完成率指标,BLEU 是对话生成指标,对话策略对于这两个指标有重要影响,注入对话策略知识后的大模型,在这两个这两个指标上带来了显著提升。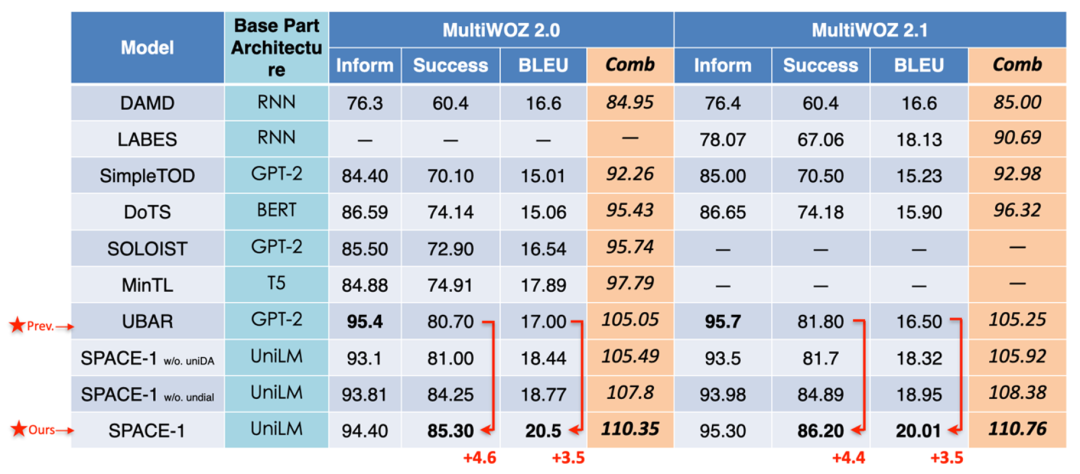
SAPCE-1 主要将对话策略知识注入到预训练模型的过程中,但是仍然存在一些局限,首先 DA 标签体系比较简单,因为只有 20 个类别;其次,DA 的标签体系是一个封闭集,虽然对于人机对话是非常重要的,但从知识的角度来看,仍然是比较简单。对于整个对话系统来说,语言理解所涉及的知识会更加复杂,比如一个 query “市中心有什么好吃的吗?”,首先这句话有意图信息(找餐馆),其次对于餐馆位置等属性一般作为是槽位信息。在广泛的对话场景下,对于意图和槽位的人类标注,其实也可以看做知识的一种形态。所以我们希望 SPACE-2 能完成从简单封闭集知识到复杂开放集知识的跃迁,很好的利用已有的标注数据。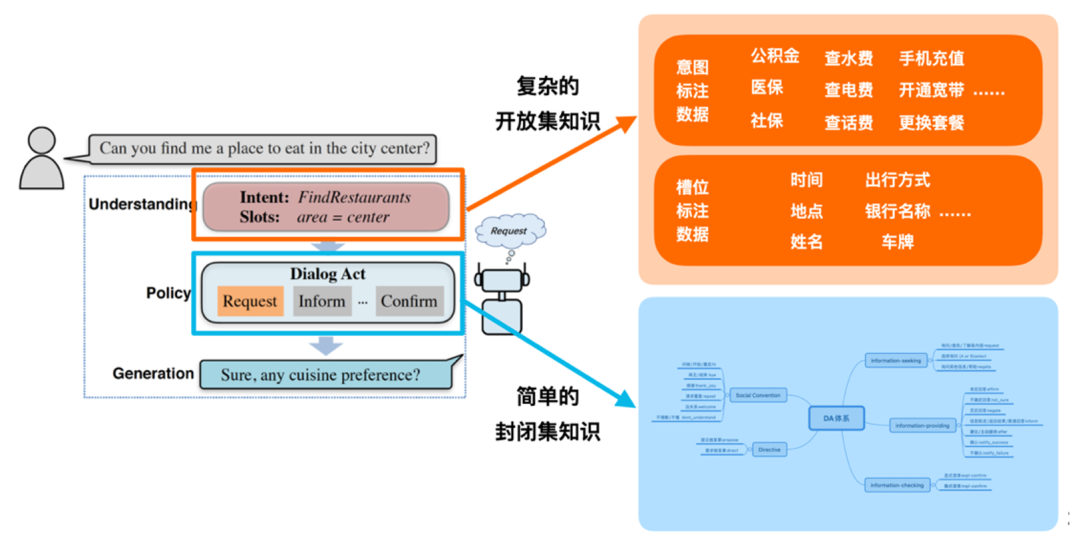
图 15 两种知识形态:简单的封闭集知识和复杂的开放集知识沿着这个思路,我们首先要解决一个难点,已有的复杂开放集知识不是一个简单的封闭集合的分类任务,不同数据集的体系更加复杂不一致。我们通过提出语义树结构对所有任务型对话数据集的用户侧理解标签进行统一,从 domaim、intent、slot、value 等四个层次进行树状标签的构建。比如对于 query “附近有好吃的川菜馆吗”,其 domain 为 restaurant,intent 是查找餐厅,slot 是菜系,value 是川菜,就可以完成一颗语义树的构建。利用这个思路,我们整合学术界已有的 32 个有标对话数据,提出 AnPreDial(300 万) ,同时整合已有的 19 个无标对话数据,提出 UnPreDial(1900 万),作为 SPACE-2 的预训练数据。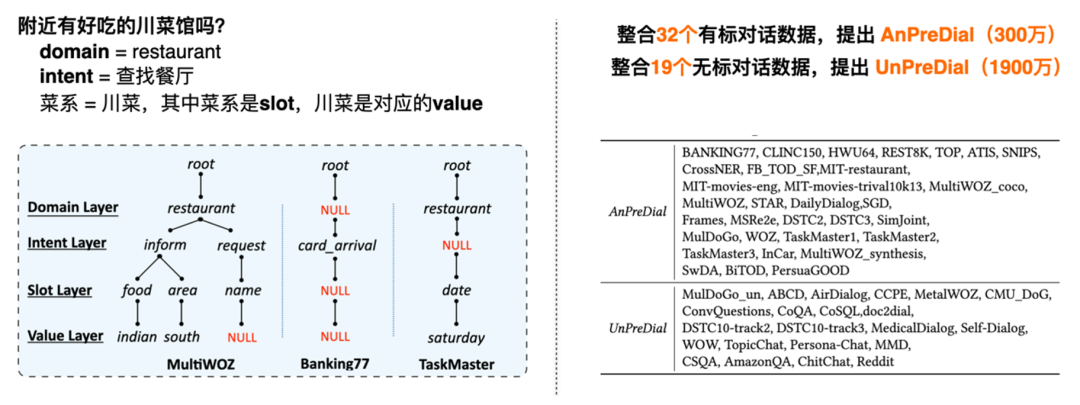
与 SPACE-1 类似,我们仍然采用半监督对比学习的思路进行知识注入,有标注样本采用有监督对比学习,无标注样本采用自监督对比学习。而对于有监督对比学习,当前的语义树知识不是独热(one-hot)的,而是可度量的相似度标签。比如 query A 表达的是“能不能帮我在城东找一家比较便宜的宾馆”,而 query B 表达的是“你能不能在城西帮忙找一家便宜的宾馆”,这两句话的语义树标签之间的相似度是可度量的,具体的度量方式我们通过两个 query 标签解析出的语义树进行计算,将语义数按照节点和路径的组合,拆分为 10 种不同的情况 {D, I, S, V, DI, IS, SV, DIS, ISV, DISV} 其中 D 表示 domain,I 表示 intent,S 表示 slot,V 表示 value。最终按照路径和节点的重合程度,计算 Jaccard 距离作为 soft label 值,最终作为半监督学习的标签。
因为两个样本之间,可能只有部分是相似的,所以根据语义树的特点,我们进一步提出了 Multi-view scoring 的学习策略,在最后预测的过程中加入不同子空间的映射矩阵,用不同子空间对部分相似的样本进行显式建模。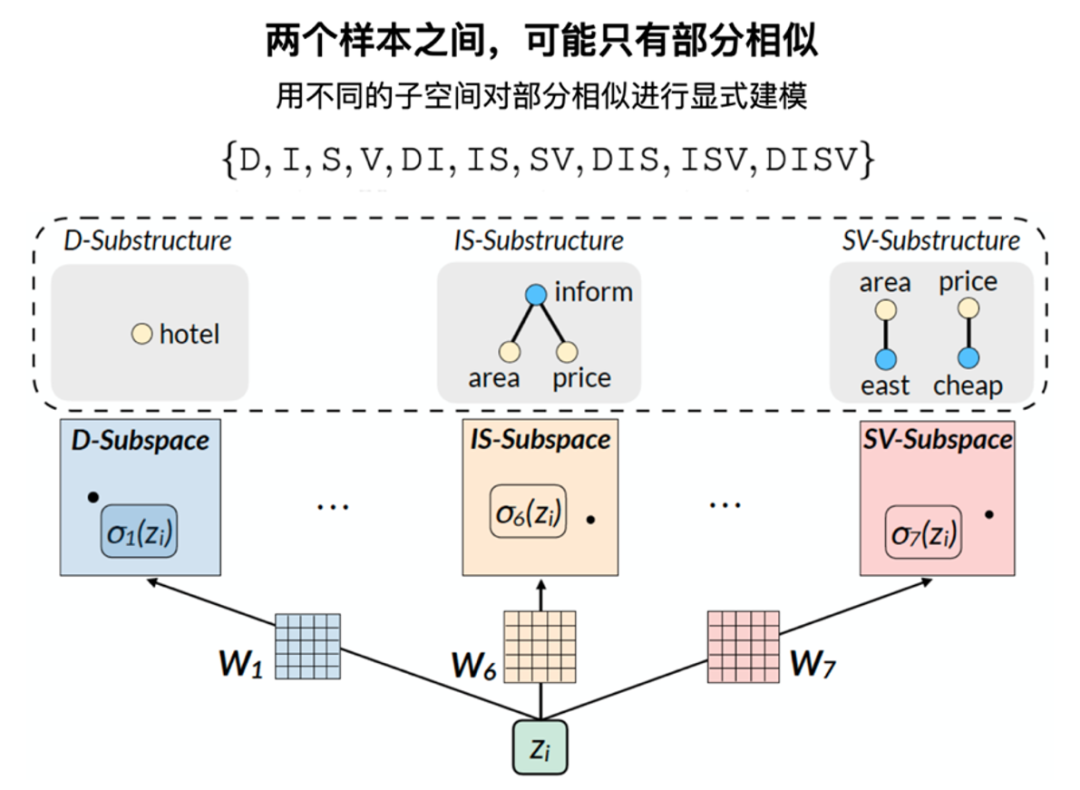
图 18 采用多视角(Multi-View)分别对不同的子结构进行显式建模通过这种策略,可以通过 soft label 度量 batch 内任意两个样本的相似度,最后通过 weighted 对比学习的方式进行优化。下图可以看出,相比于自监督的对比学习(自己和自己作为正例,batch 内其他样本作为负例)和全监督的对比学习(正负标签作为对比学习标签),SPACE-2 基于树结构的半监督对比学习方式,既能有效的利用标注信息,又能很弹性的退化为自监督对比学习,非常适合对话理解任务。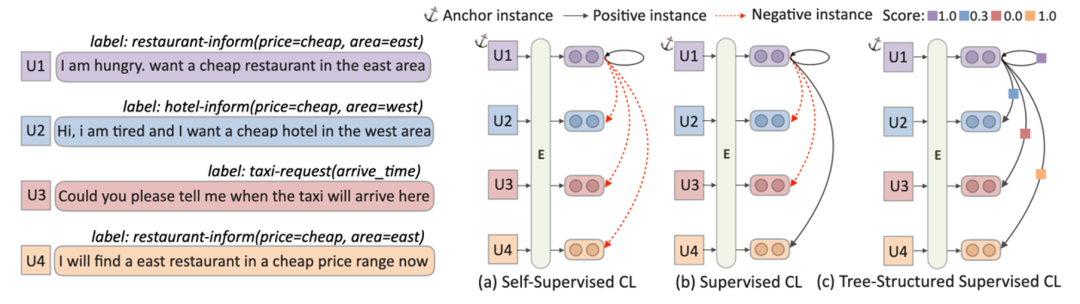
SPACE-2 在面向对话理解的榜单 DialoGLUE 上(意图识别、填槽、对话跟踪)全量测试和小样本测试总分均为第一,其中在全量测试上,SPACE-2 相比之前的 SOTA 提升 1.1%,在小样本测试上,SPACE-2 相比之前的 SOTA 提升 3.41,由此可以证明开放集知识对于对话理解的增益。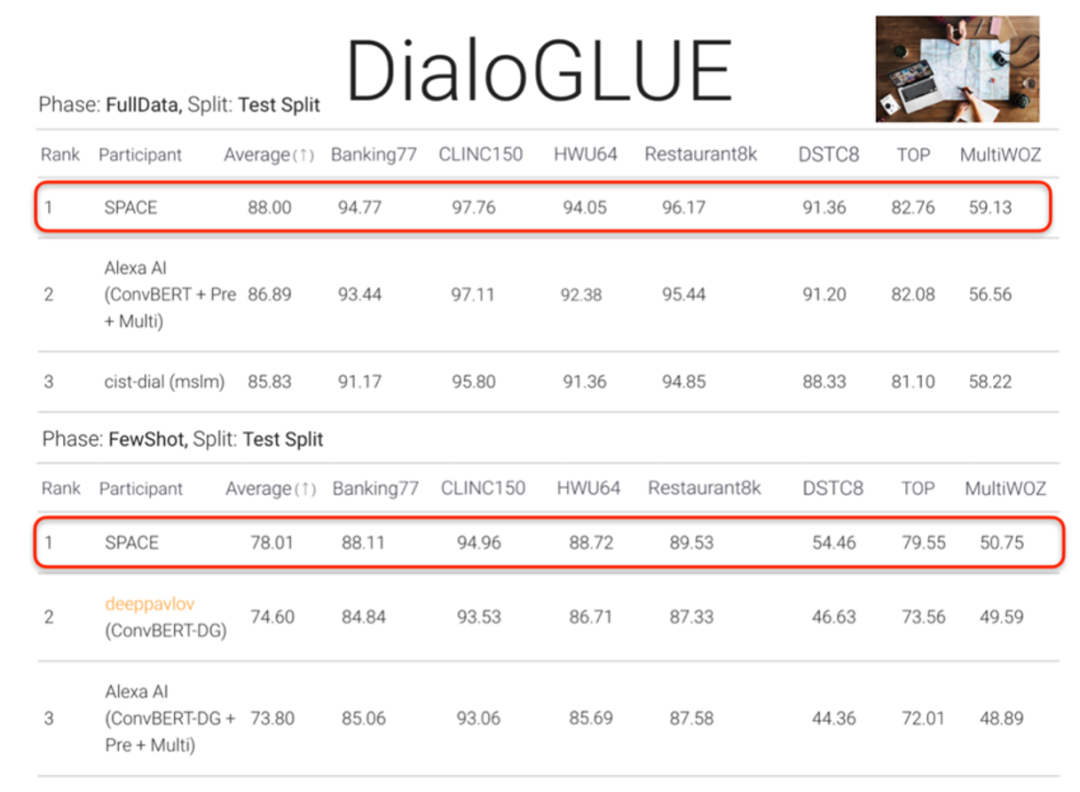
图 20 SPACE-2 注入了对话理解知识,在对话理解榜单 DialoGLUE 取得 full-data 和 few-shot 双榜单第一名- 首先,模型的泛化性有限,无法很好的泛化到其他对话任务中,比如面向对话理解的模型很难再对话策略上有很好的效果;
- 对话任务具有流程型和时序性,理解 -> 策略 -> 生成是有先后顺序及相辅相成的,同时建模多个任务将能更充分的挖掘数据特征;
- 不同任务的标签知识如果能够同时以半监督的方式注入到预训练模型中 ,标注信息的增多,对于模型的优化也更有帮助。
为了克服这些问题,所以我们提出了 SPACE-3,希望将对话理解、对话策略、对话生成都统一到一个预训练对话模型中。我们换个角度来看人机对话,首先多轮对话是流动的,是对话双方不停地进行交互,但之前的预训练对话模型都是从单侧(用户侧 or 系统侧)进行建模,没有考虑他们之间相互的影响。另外,语义树是对用户侧的语言(utterance)进行理解的,DA 是对系统侧的语言(response)进行理解的,那么就可以将理解知识和策略知识进行双侧理解统一建模。
基于这个思路,我们希望能够模拟人类对话的思考路径,通过三个 Decoder 依次做理解、策略和生成,中间的结果可以用在各类对话下游任务上。在模型技术选型上,我们采取 UniLM 作为 backbone,将 1 Encoder + 1 Decoder 扩展为 1 Encoder + 3 Decoder 的结构,其中 Dialog Encoder 作为基础编码器通过 MLM loss 完成基础语言理解,而三个 Decoder 各司其职,Understanding Decoder 通过半监督对比学习进行对话理解,Policy Deocder 通过语义策略正则 loss 进行对话策略建模,最后 Response Decoder 通过传统的生成 loss 进行对话生成。
策略 loss 的设计体现了我们对双侧理解的思想,首先在用户侧时刻,根据上下文和用户 utterance,经过 Policy Decoder 的预测的结果,和直接利用 Understanding Decoder 对下一轮 response 理解的结果,二者具有一致性。比如在下面的例子中,当模型接受 U1 + R1 + U2 为 context 的输入时 Policy Decoder 模块的结果,需要与 U1 + R1 + U2 + R2 为 context 的输入时 Understanding Decoder 模块的结果进行一致性约束,来引导模型对策略进行建模。 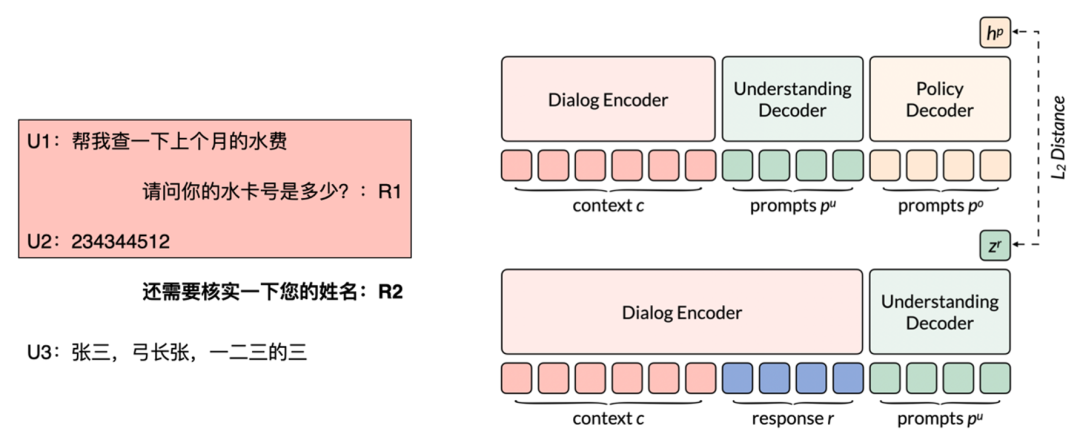
同样的,在用户侧时刻,根据上下文和系统 response,经过 Policy Decoder 的预测的结果,和直接利用 Understanding Decoder 对用户 utterance 理解的结果,二者具有一致性。当模型接受 U1 + R1 + U2 + R2 为 context 的输入时 Policy Decoder 模块的结果,需要与 U1 + R1 + U2 + R2 + U3 为 context 的输入时 Understanding Decoder 模块的结果进行一致性约束,来引导模型对策略进行建模。
最后,我们同时在对话理解任务、对话策略任务和对话生成任务上同时评测了 SPACE-3 的效果,在包含理解、策略和生成的 8 个数据集的综合评价上,取得当前最好效果。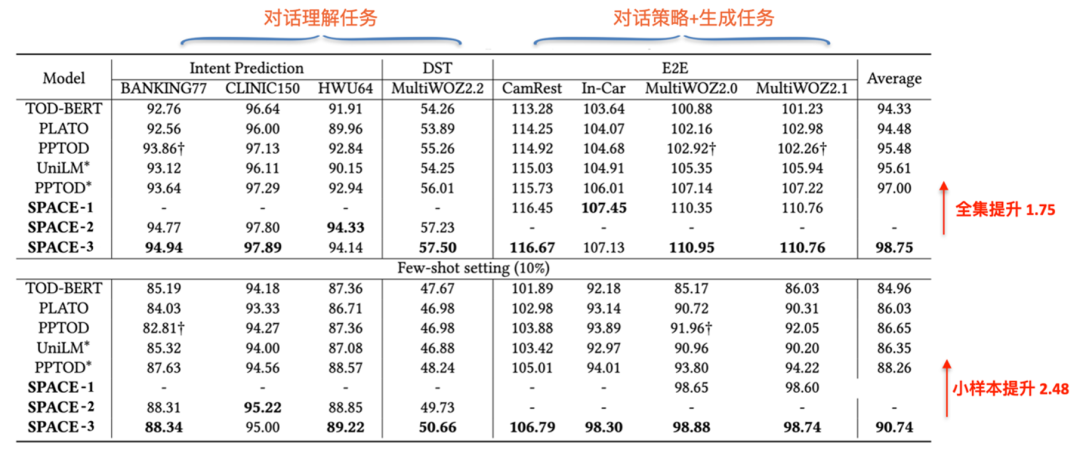
这一年多来,我们通过提出半监督预训练新范式,向预训练对话模型中注入人类标注知识,打造了 SPACE 系列模型,共在 11 个国际对话数据集取得 SOTA,并且三个工作分别侧重对话策略、对话理解及统一建模。相关的论文已经被顶级会议接收。其中,SPACE-1 融合对话策略知识,被 AAAI 2020 录用;SPACE-2 融合对话理解知识,被 COLING 2022 录用;SPACE-3 集理解、策略、生成一体,被 SIGIR 2022 录用。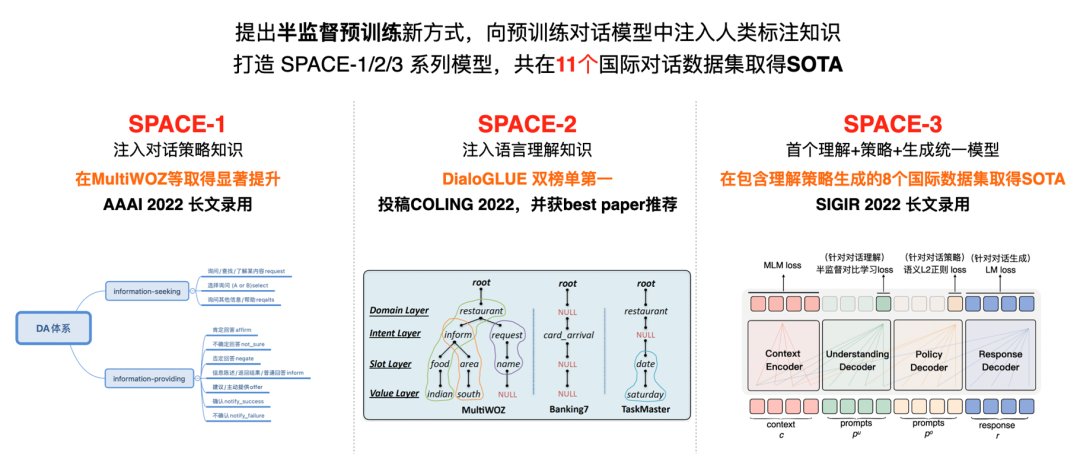
- 拓展更多任务:半监督预训练作为一个通用的预训练技术, 不仅可以用于对话任务,对于更多的 NLP 任务, 甚至其他模态的任务都有应用的潜力;
- 融入更多知识:本文中我们对分类标注知识和树形语义知识做了探索,除此之外还有很多其他知识形态,如何进行更好的形式化表示,统一地融入到一个预训练模型中也是一个开放问题;
- 设计更好算法:目前的探索是基于一致性正则化的半监督预训练方案,但整个半监督领域还有 self-taught, co-training, deep generative modeling 等诸多方法,如何综合利用或设计更优的算法是一个重要研究课题;
- 放松数据约束:半监督学习要求标注数据和无标数据具有类似的数据分布,这一要求在真实场景中具有局限性,如何设计泛化性更强的半监督学习方法,放松对于无标数据分布的假设,是未来的一个发展方向。
灵骏为本项目提供智能算力支持,显著性加速了 SPACE 大规模预训练过程。灵骏是阿里云自主研发的新一代智能计算服务,以软硬件一体的系统性创新优化,使端到端计算效率得到飞跃式升级。支持自然语言处理、图形图像识别、搜索广告推荐等多种应用场景,具备高性能、高效率、高资源利用率等核心优势,可为大模型等前沿 AI 技术提供高拓展可预期的计算服务。[1] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.[2] Brown T, Mann B, Ryder N, et al. Language Models are Few-Shot Learners. NeurIPS 2020.[3] Raffel et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR 2020.[4] Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need. NeurIPS 2017.[5] Henderson M, Casanueva I, Mrkšić N, et al. Convert: Efficient and accurate conversational representations from transformers. EMNLP-findings 2019.[6] Wu C S, Hoi S, Socher R, et al. TOD-BERT: pre-trained natural language understanding for task-oriented dialogue. EMNLP 2020.[7] Zihang Jiang, Weihao Yu, Daquan Zhou, et al. ConvBERT: Improving BERT with Span-based Dynamic Convolution. NeurIPS 2020.[8] Zhang Y, Sun S, Galley M, et al. DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation. ACL system demonstration 2020.[9] Adiwardana D, Luong M T, So D R, et al. Towards a human-like open-domain chatbot. arXiv preprint arXiv:2001.09977, 2020.[10] Roller S, Dinan E, Goyal N, et al. Recipes for building an open-domain chatbot. arXiv preprint arXiv:2004.13637, 2020.[11] Xiaojin Jerry Zhu. Semi-supervised learning literature survey. 2005.[12] Liang X, Wu L, Li J, et al. R-Drop: Regularized Dropout for Neural Networks. NeurIPS 2021.[13] He W, Dai Y, Zheng Y, et al. SPACE: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection. AAAI 2022.[14] He W, Dai Y, Hui B, et al. SPACE-2: Tree-Structured Semi-Supervised Contrastive Pre-training for Task-Oriented Dialog Understanding. COLING 2022.[15] He W, Dai Y, Yang M, SPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation. SIGIR 2022.[16] Xu H, Zhengyan Z, Ning D, et al. Pre-Trained Models: Past, Present and Future [J]. arXiv preprint arXiv:2106.07139, 2021.声纹识别:从理论到编程实战
《声纹识别:从理论到编程实战》中文课上线,由谷歌声纹团队负责人王泉博士主讲。目前,课程答疑正在持续更新中。课程视频内容共 12 小时,着重介绍基于深度学习的声纹识别系统,包括大量学术界与产业界的最新研究成果。同时课程配有 32 次课后测验、10 次编程练习、10 次大作业,确保课程结束时可以亲自上手从零搭建一个完整的声纹识别系统。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]