Meta打造首个「蛋白质宇宙」全景图!用150亿参数语言模型,预测了6亿+蛋白质结构
新智元报道
新智元报道
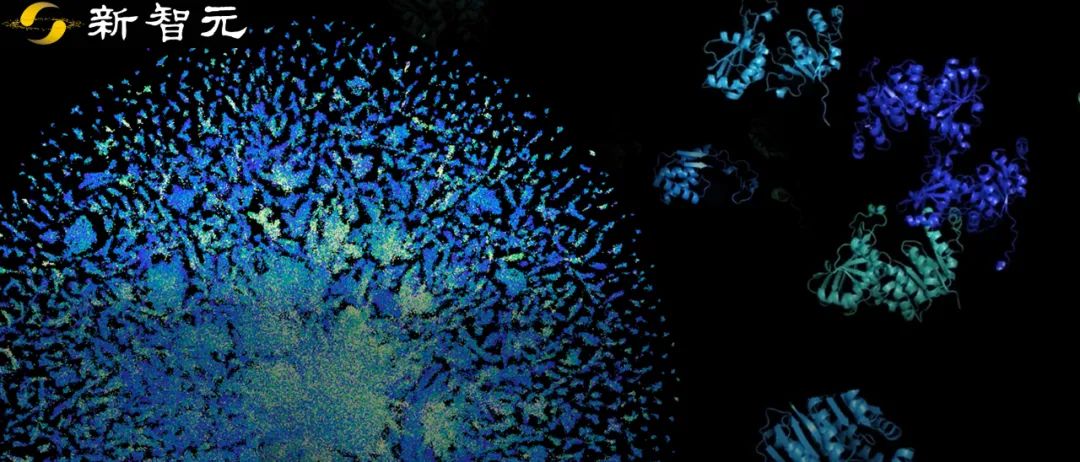
【新智元导读】Meta AI在蛋白质结构预测上又有新突破!利用大型语言模型 ,打造了一个超过6亿个宏基因组结构的数据库,让蛋白质结构预测提速60倍。
蛋白质宇宙的「暗物质」
蛋白质结构预测,提速60倍!
语言模型,真是「万能」的
读懂「蛋白质语言」,让生命更透明
微信扫码关注该文公众号作者
戳这里提交新闻线索和高质量文章给我们。
来源: qq
点击查看作者最近其他文章新智元报道
蛋白质宇宙的「暗物质」
蛋白质结构预测,提速60倍!
语言模型,真是「万能」的
读懂「蛋白质语言」,让生命更透明
微信扫码关注该文公众号作者