【新智元导读】2022年,谷歌在ML领域取得了哪些新进展?Jeff Dean发万字长文总结。
Google Research高级研究员兼高级副总裁Jeff Dean一文帮你总结!昨天,Jeff Dean代表Google Research社区发布一篇干货满满的长文,总结了谷歌在2022年激动人心的新进展。显然,大佬花了很久(也许是一年),酝酿了一个大的。在这次的第一篇中,Jeff Dean首先讨论了语言、生成、视觉和多模态模型。接下来,他还将讨论负责任的人工智能、算法和计算机系统,以及科学、健康和机器人技术等研究主题的新进展。在过去十年中,机器学习最令人兴奋的领域之一,无疑就是规模更大、功能更强的语言模型了。
一路走来,最瞩目的进展就是新的方法,比如序列到序列学习(seq2seq),以及谷歌开发的Transformer模型。这些方法,是过去几年语言模型领域大部分进展的基础。虽然语言模型的训练目标简单得令人吃惊(比如根据前面的token,预测文本序列中的下一个token),但当大模型在足够大、足够多样化的文本语料库上进行训练时,这些模型可以生成连贯的、有上下文的、听起来自然的响应。这些响应可以用于广泛的任务,比如生成创意性的内容、在不同语言之间进行翻译、帮助完成编码任务,以及以有用、信息丰富的方式回答问题。谷歌正在研究的LaMDA,就探索了这些模型如何产生安全、接地气和高质量的对话,以实现有上下文语境的多轮对话。
项目地址:https://blog.google/technology/ai/lamda/人该怎样与计算机互动?以前,我们会去适应计算机,用它能接受的方式与它互动。但现在,有了LaMDA这样的模型,人类与计算机的互动就有了一种崭新的方式——人类喜欢的自然对话模式。Jeff Dean表示,谷歌已经取得了很大进展,让LaMDA变得有用,且符合事实(合理猜测,Dean这是拉踩了一波ChatGPT )。
)。
随着模型规模的增加,跨任务的性能会提高,同时还会解锁新功能2022年4月,谷歌提出了PaLM,这是一个拥有5400亿参数的大型语言模型,使用Pathways软件基础设施构建,并在多个TPU v4 Pod上进行训练。PaLM的工作表明,对于在大量多语言数据和源代码上训练的大规模语言模型,仅仅以预测下一个token为目标进行训练,就能在各种自然语言、翻译和编码任务中达到SOTA,尽管它们从未被训练为专门执行这些任务。这项工作表明,增加模型和训练数据的规模,可以显著提高模型能力。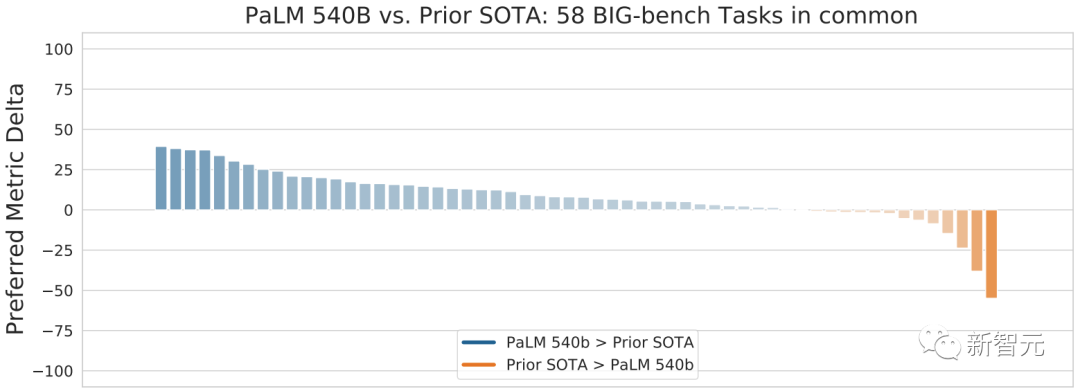
PaLM 540B参数模型与之前的SOTA在Big-bench的58项任务上的性能比较谷歌在大型语言模型(LLM)上取得了巨大的成功,这些模型是在源代码(而不是自然语言文本数据)上进行训练的。这些模型可以极大地帮助内部开发人员,详情可见「ML-Enhanced Code Completion Improves Developer Productivity」。谷歌用了一个5亿参数的语言模型,为10,000名在IDE中使用该模型的开发者提供了代码建议,所有代码的2.6%,都是来自于这个模型的建议,因此,这些开发者减少了6%的编码迭代时间。现在,谷歌正在研究这个模型的增强版本,希望推广给更多开发者。AI中经常遇到的挑战之一,就是建立能够进行多步骤推理的系统,将复杂的问题分解成较小的任务,并结合这些任务的解决方案,解决更大的问题。谷歌最近在思维链提示方面的工作,就鼓励模型在解决新问题时「展示工作」,这样就能帮助语言模型遵循逻辑思维链,并产生更有条理、有组织和准确的响应。就像四年级的数学老师会鼓励学生展示解决问题的步骤,而不是仅仅写下答案一样,这种方法不仅使解决问题的方法更具有可解释性,而且对于需要多个推理步骤的复杂问题,也更有可能找到正确的答案。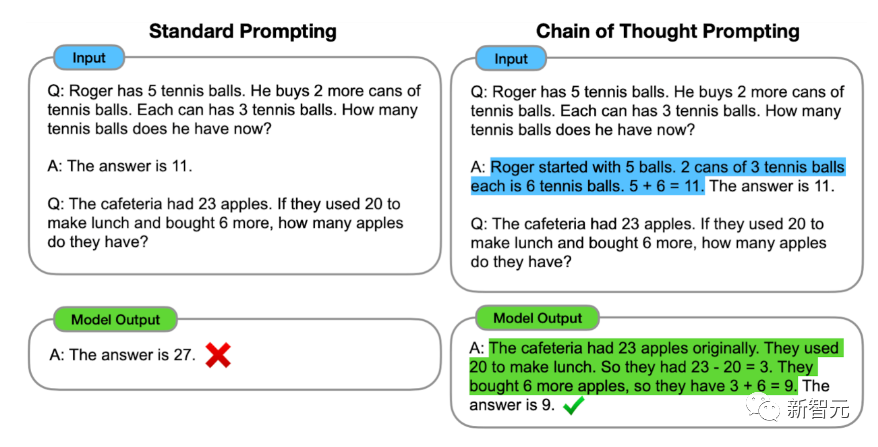
这种多步骤推理最大的益处就是,可以提高模型解决复杂数学推理和科学问题的能力关键问题在于,ML模型是否能够学会使用多步骤推理来解决复杂问题?对此,谷歌提出了Minerva模型,它以通用的PaLM语言模型为基础,在来自arXiv的大量数学文档和论文的语料库中对其进行微调,然后使用思维链提示和自洽解码。在各自数学推理和科学问题的基准套件上,Minerva都展示出了SOTA。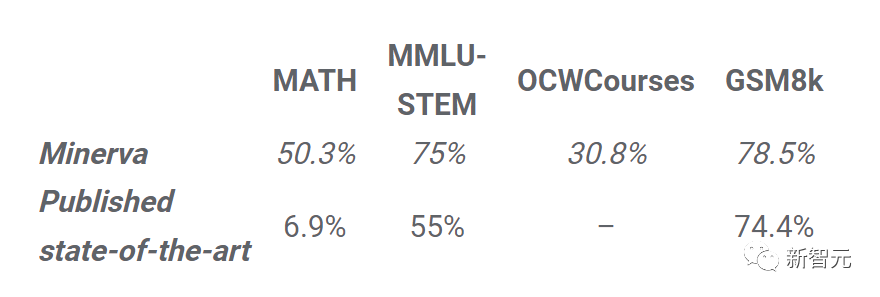
Minerva 540B显著提高了STEM评估数据集的最新性能思维链提示(chain of thought prompting)是一种向模型更好地表达自然语言提示和示例的方法,能够显著提高模型处理新任务的能力。类似的提示微调(prompt tuning),即在问题领域特定文本的语料库上对大型语言模型进行微调,也显示出了巨大的前景。
论文地址:https://arxiv.org/abs/2212.13138在「Large Language Models Encode Clinical Knowledge」一文中,研究者证明了通过提示微调,可以用较少的例子使通用语言模型适应医学领域,所产生的模型可以在美国医学执照考试问题(MedQA)上达到67.6%的准确率,比之前的SOTA高出17%以上。虽然与临床医生的能力相比仍有差距,但理解力、知识回忆能力和医学推理能力都随着模型规模和指令提示微调(instruction prompt tuning)的调整而得到改善,这表明LLM在医学领域具备极大的潜在应用场景。另外,在多种语言上训练的大型语言模型,也可以帮忙把一种语言翻译到另一种语言,即使它们从未被教导过要明确地翻译文本。传统的机器翻译系统,通常是依靠着并行(翻译)文本,来学习从一种语言到另一种语言的翻译。然而,由于平行文本只存在于相对较少的语言中,许多语言往往不被机器翻译系统所支持。在「Unlocking Zero-Resource Machine Translation to Support New Languages in Google Translate」、「Building Machine Translation Systems for the Next Thousand Languages」、「Towards the Next 1000 Languages in Multilingual Machine Translation: Exploring the Synergy Between Supervised and Self-Supervised Learning」这三篇文章中,谷歌研究员描述了一套技术,这些技术在使用在单语种(非平行)数据集上训练出的大规模多语种语言模型,为谷歌翻译增加了24种新语言,被3亿人所使用。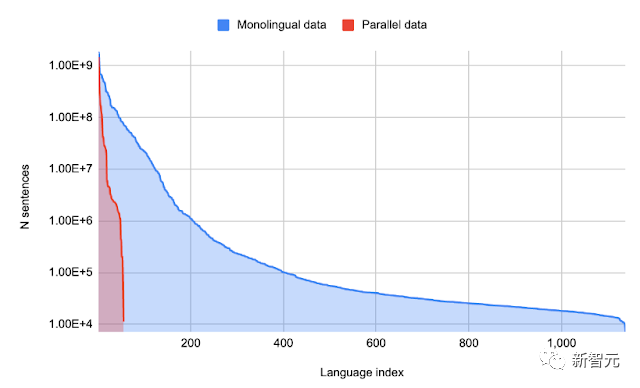
每种语言的单语数据量与每种语言的并行(翻译)数据量。少数语言有大量的平行数据,但有很长的语言只有单语数据另一种方法是利用软提示(learned soft prompt)进行表征。在这种情况下,不是构建新的输入token来表征提示,而是在每个任务中添加少量可调整的参数,这些参数可以从一些任务实例中学习。采用软提示的任务,通常都产生了高性能,同时还允许大型预训练语言模型在成千上万的不同任务中共享。这是更普遍的任务适配器技术的一个具体示例,它允许很大一部分参数在不同的任务中共享,同时仍然允许特定任务上的适应和调整。有趣的是,由于新功能的出现,语言模型的规模会随着规模的增加而显着增长。在「Characterizing Emergent Phenomena in Large Language Models」中,研究者对一个奇怪的现象进行了调查——这些模型在达到一定规模之前,无法非常有效地执行特定的复杂任务。然而,一旦发生了关键的学习量(因任务而异),他们准确执行复杂任务的能力就会突然大幅提升。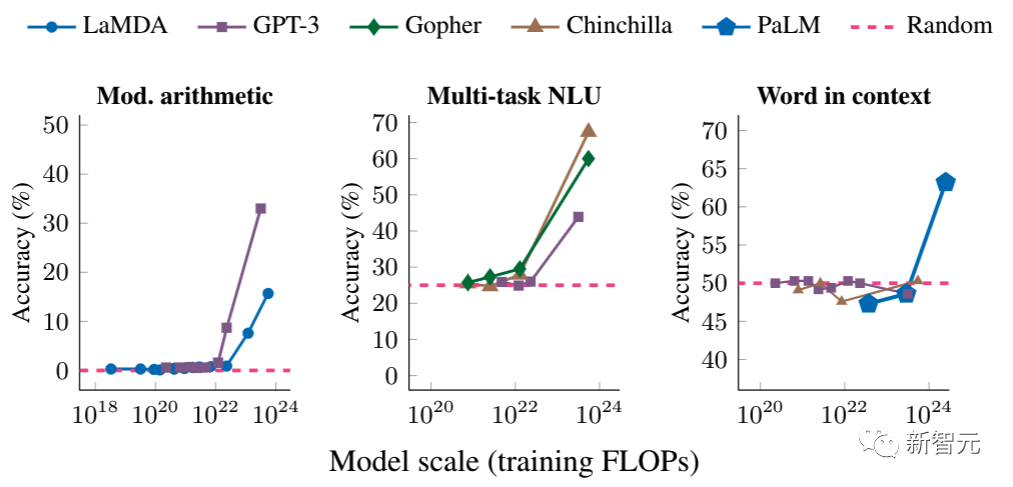
进行多步算术(左)、在大学水平考试中考高分(中)以及在上下文中识别单词的预期含义(右)的能力,都只出现在足够大的模型中,包括LaMDA、GPT-3、Gopher、Chinchilla和PaLM
这就提出了一个问题,即当这些模型得到进一步训练时,哪些新任务会变得可行。2022年,图像、视频和音频的生成模型的质量和能力已经显示出真正令人惊叹和非凡的进步。生成模型的方法多种多样,但共同点是必须学会对复杂的数据集(如自然图像)进行建模。2014年开发的生成式对抗网络(GAN),设置了两个相互作用模型:2. 鉴别器:同时接收生成的和真实的图像,并判断两者中哪个是生成的,哪个是真实的。每个模型都试图在与另一个模型的竞争中取得胜利,结果是两个模型在各自任务上的表现都越来越好。最后,生成模型就可以单独用于生成图像了。2015年,「Deep Unsupervised Learning using Nonequilibrium Thermodynamics」一文提出了扩散模型(Diffusion model)。
论文地址:https://arxiv.org/abs/1503.03585模型首先通过一个迭代的前向扩散过程,系统地、缓慢地破坏数据分布中的结构。然后,再通过学习一个反向扩散过程,从而恢复数据中已经丢失的结构,即使是在高水平的噪声下。其中,前向过程可以用来为反向扩散过程生成以各种有用的、可控制的模型输入为条件的噪音起点,这样反向扩散(生成)过程就变得可控了。也就是说,我们现在可以要求模型「生成一个柚子的图像」,这显然要比单纯地「生成一个图像」有用得多。之后,各种形式的自回归模型也被应用于图像生成的任务。2016年,「Pixel Recurrent Neural Networks」提出了一种递归架构PixelRNN,以及一种类似但更有效的卷积架构PixelCNN。这两个架构帮助奠定了使用深度神经网络进行像素级生成的基础。
论文地址:https://arxiv.org/abs/1601.06759相关的研究还有「Conditional Image Generation with PixelCNN Decoders」这篇。论文地址:https://arxiv.org/abs/1606.05328紧随其后的是,2017年在「Neural Discrete Representation Learning」中提出的VQ-VAE,一个矢量量化的自编码器。通过将VQ-VAE与PixelCNN相结合,可以产生高质量的图像。
论文地址:https://arxiv.org/abs/1711.009372018年提出的Image Transformer,则使用自回归Transformer模型来生成图像。
论文地址:https://arxiv.org/abs/1802.05751然而,所有这些技术所生成的图像与现实世界相比,质量都相对较低。直到最近,一些新研究才为更好的图像生成打开了大门。比如OpenAI的CLIP——一种联合训练图像编码器和文本解码器以预测「图像、文本」对的预训练方法。这种预测哪个描述与哪个图像相配的预训练任务,被证明是学习图像表征的有效和可扩展的方式,并在ImageNet这样的数据集上取得了出色的zero-shot性能。
论文地址:https://arxiv.org/abs/2103.00020
项目地址:https://openai.com/blog/clip/除了CLIP之外,生成式图像模型的工具也在不断增加。大型语言模型编码器已经被证明可以有效地将图像生成的条件放在长的自然语言描述上,而不仅仅是数量有限的预先设定的图像类别。大规模的图像训练数据集和附带的描述(可以反过来作为文本→图像的示例)提高了整体性能。所有这些因素加在一起,产生了一系列能够生成高分辨率图像的模型,即便是非常详细和奇妙的提示也可以。在此,Jeff Dean重点介绍了谷歌研究团队的两项最新进展:Imagen和Parti。左图来自Imagen:「皇家城堡的一面墙。墙上有两幅画。左边那幅是皇家浣熊国王充满细节的油画。右边那幅是皇家浣熊王后充满细节的油画。」右图来自Prti:「一只戴着摩托车头盔和披风的泰迪熊在纽约市的出租车上冲浪。数码照片。」
在2022年发表的「Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding」中,研究人员表明,一个通用的大型语言模型(如T5),通过在纯文本语料库上进行预训练,可以在图像合成的文本编码方面有着出色的表现。令人惊讶的是,在Imagen中增加语言模型的大小,比增加图像扩散模型的大小更能提高样本的保真度和图像-文本的一致性。
论文地址:https://arxiv.org/abs/2205.11487
项目地址:https://imagen.research.google/具体而言,Imagen通过在训练期间偶尔「放弃」条件信息来提高性能,并为基于扩散的图像生成带来了一些进展,包括「Efficient U-Net」和「无分类器引导」的新型内存效率架构。其中,无分类器引导迫使模型学会仅从输入数据中生成,从而避免因过度依赖调节信息而产生的问题。
论文地址:https://arxiv.org/abs/2207.12598对此,「Guidance: a cheat code for diffusion models」一文提供了更加直观的解释。文章地址:https://benanne.github.io/2022/05/26/guidance.html其次,Parti使用自回归Transformer架构来生成基于文本输入的图像像素。在2021年发布的「Vector-quantized Image Modeling with Improved VQGAN」表明,基于Vision Transformer的编码器能够显著改善矢量量化GAN模型VQGAN的输出。
论文地址:https://arxiv.org/abs/2110.04627这在2022年发布的「Scaling Autoregressive Models for Content-Rich Text-to-Image Generation」中得到了扩展,通过将Transformer编码器-解码器的参数增加到200亿个,来获得更好的结果。
论文地址:https://arxiv.org/abs/2206.10789此外,Parti还善于捕捉提示中的微妙线索,并且采用了上文所述的无分类引导对生成的图像进行锐化。用户的控制
上述进展使我们有可能根据文字描述生成逼真的静态图像。然而,有时仅靠文字并不足以使你创造出你想要的东西。举个例子,「一只狗在沙滩上被独角兽追赶」与「我的狗在沙滩上被独角兽追赶」。因此,谷歌在为用户提供控制生成过程的新方法上又做了后续的研究。在「DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation」中,用户能够对Imagen或Parti这样的模型进行微调,进而根据文本和用户提供的图像的组合生成新的图像。比如,用户可以将自己(或宠物)的图像放入生成的图像当中。
论文地址:https://arxiv.org/abs/2208.12242
项目地址:https://dreambooth.github.io/这一点在「Prompt-to-Prompt Image Editing with Cross Attention Control」中也得到了体现。用户可以通过文本提示让模型去填充被mask的区域,从而反复编辑图像,比如「将汽车变成自行车」这种。
论文地址:https://arxiv.org/abs/2208.01626
项目地址:https://imagen.research.google/editor/生成式视频
为视频创建生成模型是一个非常具有挑战性的领域,因为与图像不同的是,图像的挑战是将图像的理想属性与生成的像素相匹配,而视频则有一个额外的时间维度。视频中,每一帧的像素不仅必须与此刻应该发生的事相匹配,还必须与其他帧相一致——既要在非常精细的层面上(前后几帧的范围内,使运动看起来平滑自然),也要在粗略的层面上(如果我们想做一个两分钟的飞机起飞、盘旋和降落的视频,就必须制作成千上万个符合这个需求的帧)。今年,谷歌通过Imagen Video和Phenaki这两项工作,在这个目标上取得了相当多令人振奋的进展。在「Imagen Video: High Definition Video Generation from Diffusion Models」中,研究人员使用级联扩散模型生成高分辨率的视频。
论文地址:https://arxiv.org/abs/2210.02303首先,输入文本提示(一只戴着生日帽的快乐大象在海底行走),并用T5将其编码为文本嵌入。然后,一个基础的视频扩散模型以40×24的分辨率和每秒3帧的速度生成一个非常粗略的16帧视频。最后,由多个时间超分辨率(TSR)和空间超分辨率(SSR)模型进行上采样,生成最终的128帧,分辨率为1280×768,每秒24帧,共计5.3s的高清视频。2022年发布的「Phenaki: Variable Length Video Generation From Open Domain Textual Description」,引入了一个新的基于Transformer的模型来学习视频表征。
论文地址:https://arxiv.org/abs/2210.02399其中,文本调节是通过训练一个双向的Transformer模型来实现的,可以根据文本描述生成视频token。然后,再对这些生成的视频token进行解码来创建最终的视频。有了Imagen Video和Phenaki,我们还可以将两个模型结合起来,从Imagen的高分辨率单帧和Phenaki的长视频中获益。最直接的方法是使用Imagen Video来处理短视频片段的超分辨率,同时依靠自回归的Phenaki模型来生成长时标视频信息。生成式音频
除了面向视觉的生成模型外,谷歌在音频的生成模型方面也取得了重大进展。在「AudioLM, a Language Modeling Approach to Audio Generation」中,研究人员描述了如何利用语言建模的进展来生成音频,而不需要在注释的数据上进行训练。
论文地址:https://arxiv.org/abs/2209.031432020年,在名为「An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale」的文章中,谷歌研究团队开始使用Transformer架构进行计算机视觉的研究,而非卷积神经网络(CNN)。
论文地址:https://arxiv.org/abs/2010.11929虽然卷积的图像局部特征提取是许多计算机视觉问题的有力解法,但Transformer的注意力机制在图像处理方面显得灵活。图像的处理
然而,由于完全注意力机制会随着图像大小进行二次缩放,很难将其应用于高分辨率的图像处理中。为此,谷歌团队提出了一种新的multi-axis方法,改进原有的ViT和MLP模型,更好地适应高分辨率、密集的预测任务、同时,模型可以自然地适应不同的输入大小,具有高灵活性和低复杂度。为实现高级和低级视觉的不同任务,谷歌团队推出了两个模型:MaxViT和MAXIM。在「MaxViT: Multi-Axis Vision Transformer」中,研究人员探索了一种在视觉模型的每个阶段,结合定位和非定位信息的方法。
论文地址:https://arxiv.org/abs/2204.01697这种方法在ImageNet-1k分类任务和各种对象检测任务上的表现优于其他最先进的模型,而且它的计算成本要低得多。
在MaxViT中,multi-axis注意力机制使其复杂度呈线性实验显示,MaxViT显著提高了图像分类、目标检测、分割、质量评估等高级任务的最新技术水平。在「MAXIM: Multi-Axis MLP for Image Processing」中,谷歌推出了图像处理解决方案的第二个模型。
论文地址:https://arxiv.org/abs/2201.02973基于类似UNet的架构,MAXIM在低级成像任务(包括去噪、去模糊、去雾、去雨和弱光增强)上具有强劲的性能。
为了促进对高效Transformer和MLP模型的进一步研究,谷歌团队开源了MaxViT和MAXIM的代码和模型。MaxViT代码链接:https://github.com/google-research/maxvitMAXIM代码链接:https://github.com/google-research/maxim除了数据提取,对象监测也是图像处理的重要一环。在「Pix2Seq: A New Language Interface for Object Detection」中,研究人员探索了一种简单而通用的方法,从完全不同的角度处理对象检测。
论文地址:https://arxiv.org/abs/2109.10852与基于特定任务的现有方法不同,谷歌研究人员将对象检测转换为以观察到的像素输入为条件的语言建模任务。
Pix2Seq通过神经网络感知图像,并为每个对象生成一系列token与现有的高度专业化和优化的检测算法相比,Pix2Seq在大规模对象检测COCO数据集方面取得了更好地结果,通过在更大的对象检测数据集上预训练模型,可以进一步提高其性能。理解3D世界
计算机视觉的另一个挑战,在于如何让模型通过一张或几张二维图像,更好地理解物体在现实世界的三维结构。在「FILM: Frame Interpolation for Large Motion」一文中,研究人员演示了如何在相隔多秒的两张照片之间,通过插值来创建慢动作短视频。
论文地址:https://arxiv.org/abs/2202.04901在「View Synthesis with Transformers」中,研究人员展示了如何结合两种新的技术来合成场景的新视图,也就是光场神经渲染(Light Field Neural Rendering,LFNR)和可泛化的基于patch的神经渲染(Generalizable Patch-Based Neural Rendering,GPNR)。LFNR项目地址:https://light-field-neural-rendering.github.io/GPNR项目地址:https://mohammedsuhail.net/gen_patch_neural_rendering/LFNR使用学习组合参考像素颜色的Transformer,来准确重现与参考图像相关的效果。虽然LFNR在单个场景中效果很好,但它的新场景泛化能力有限。GPNR通过使用一系列具有规范化位置编码的Transformer,可以很好地克服这一点。这些Transformer可以在一组场景上进行训练,以合成新场景的视图。这些技术结合在一起,只需从场景的几张图像中就可以高质量地合成新场景,如下所示:在「LOLNerf: Learn from One Look」中,研究人员探索了仅从单个二维图像中学习高质量表征的能力。
论文地址:https://arxiv.org/abs/2111.09996通过对特定类别对象的不同示例进行培训,LOLNerf只凭一张图片,就能充分了解对象的预期三维结构。通过这项技术,机器模型能更好地了解三维世界——这是计算机视觉人的长期梦想!Dean介绍的这些机器学习领域变革性的进展,在改变数十亿谷歌产品的用户,这些产品包括搜索、智能助理、广告、云、Gmail、地图、YouTube、Workspace、安卓、Pixel、Nest和翻译。这些最新的进展切实影响着谷歌用户的体验,改变着人类与计算机互动的方式。语言模型让人机可以进行自然的对话,并且从计算机那里得到令人惊讶的回应。由于计算机视觉的新方法,计算机可以帮助人们在三维(而不是二维)的环境中进行创作和互动。由于生成式模型的新进展,计算机可以帮助人们创建图像、视频和音频。而自然语言理解方面的进展,让计算机可以理解你所要创造的东西,然后产生令你惊讶的结果!改变人机互动的另一个转变,是多模图模型能力的不断增强。谷歌正在努力创造一个能够流畅理解不同模式的单一模型,它可以理解每一种模式在上下文中代表什么,然后生成不同模式。比如,他们推出了一个统一的语言模型,他可以在100多种语言中执行视觉、语言、问题回答和物体检测任务,并且达到了SOTA。在未来,人们可以调动更多的感官,让计算机做他们想做的事情,比如,「用斯瓦希里语描述这张图片」。还有一些模型,可以通过不同的组合,生成由自然语言、图像和音频控制的图像、视频和音频。在文章最后,Dean表示,谷歌对用户和整个社会都负有责任,会竭尽全力保证这些AI技术的安全性。P.S 因为时间原因,多模态模型的部分本次未写入全文,敬请期待后续。https://ai.googleblog.com/2023/01/google-research-2022-beyond-language.html
