今日,谷歌研究院高级研究员及高级副总裁 Jeff Dean 代表谷歌研究社区,发表了一篇博客,回顾了 2022 年在语言模型、CV、多模态模型和生成 ML 模型等领域取得的新进展,并对 2023 年及之后的发展进行了展望。

机器之心对博客内容进行了简要的编译整理,全文如下:我一直对计算机很感兴趣,它能够帮助人们更好地了解周围的环境。过去十年,谷歌所做的大部分研究都在追求类似的愿景,帮助人们更好地了解周围的世界并完成工作。我们希望制造出更强大的机器,并与他人合作完成各种各样的任务,如复杂的信息搜索、创意、分析和合成、编写软件等等。同时想解决复杂的数学或科学问题,将世界信息翻译成任何语言、诊断疾病、了解物理世界以及开发更强大的机器人等。
我们已经在现有研究工作中展示了一些功能的早期版本,并将其中一些功能交付给触及数十亿用户日常生活的谷歌产品中。
从这篇博客开始,我将开启一个系列文章,将重点介绍 2022 年取得的一些振奋人心的进展,并描绘对 2023 年及以后的美好愿景。本文首先讨论语言模型、计算机视觉、多模态模型和生成机器学习模型。接下来的几周,我们将继续深入探讨负责任 AI、算法、计算机系统以及科学、健康和机器人等研究课题的新进展。过去十年,规模更大、性能更强的语言模型一直是机器学习研究中最令人兴奋的领域之一,如序列到序列学习和谷歌 Transformer 模型成为了过去数年该领域大多数进展的基础。当大模型在足够大和多样化文本语料库中进行训练时,可以生成连贯、上下文相关、听上去自然的响应,并用于创意内容生成、语言翻译等广泛的任务。谷歌关于 LaMDA 的工作探索了如何将这些模型用于安全、扎实和高质量的对话以实现上下文多轮对话。
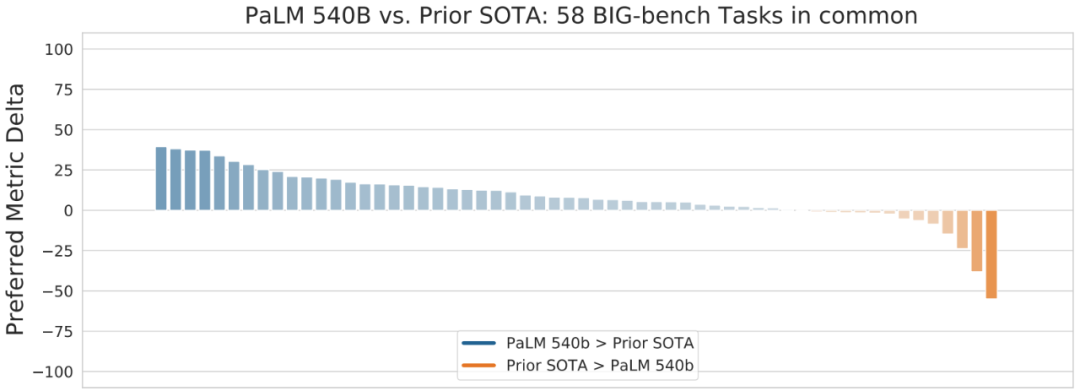
2022 年 4 月,谷歌描述了 PaLM 的工作,这是一个使用 Pathways 软件基础设施构建并在多个 TPU v4 Pods 上训练的 5400 亿参数的大型语言模型。强大的系统和算力投入带来了惊艳的结果。研究者在数百个语言理解和生成任务上评估了 PaLM,发现它在大多数任务上实现了 SOTA 小样本学习性能,可以出色地完成笑话解读、bug 修复、从表情符号中猜电影等语言、代码任务。
此外使用在源代码上训练的大型语言模型取得了巨大成功,为谷歌内部人员提供了很大帮助,如机器学习增强的代码补全提升了开发者效率。谷歌进行了规模上万人的内部测试,结果显示,该方法可以将开发人员的编码效率提升 6%。而且有趣的是,该模型相当小,参数量只有 5 亿。目前 2.6%的新代码都是通过接受 ML 代码补全建议生成的。谷歌正在开发此功能的增强版本,并希望推广给更多的开发人员。
人工智能面临的关键挑战之一是构建可以执行多步推理的系统,学习将复杂问题分解为更小的任务,并结合这些任务的解决方案来解决更大的问题。谷歌提出了思维提示链(chain of thought prompting),提示语言模型生成一系列短句,这些短句模仿一个人在解决推理任务时可能采用的推理过程。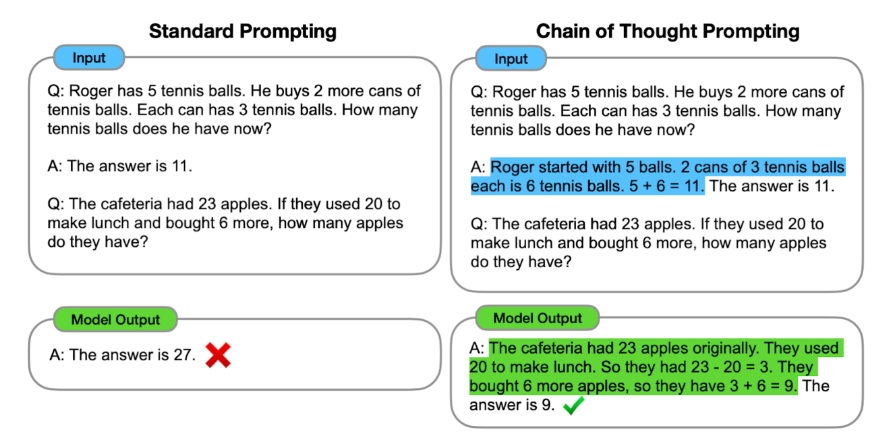
多步推理最有益和可衡量的领域之一是模型解决复杂数学推理和科学问题的能力。谷歌通过采用通过的 PaLM 语言模型并在 arXiv 的大量数学文档和科学研究论文上对它进行微调,然后使用思维提示链和自洽解码,并在跨多种科学和数学基准测试套件的数学推理和科学问题上实现了相较于 SOTA 方法的显著改进。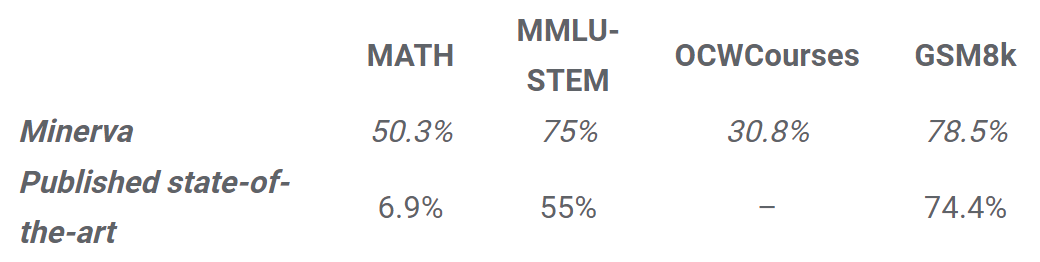
类似的还有 learned prompt tuning,其中大型语言模型在问题领域特定的文本语料库中进行微调并显示出巨大的潜力。在论文《Large Language Models Encode Clinical Knowledge》中,谷歌证明了 learned prompt tuning 可以使用相对较少的示例将通用语言模型适用于医学领域,并且得到的模型在美国医师执照考试题(MedQA)中达到了 67.6% 的准确率,比之前的 ML SOTA 高出了 17% 以上。
在多种语言上训练的大型语言模型可以帮助从一种语言翻译成另一种语言。谷歌解锁了零资源机器翻译以支持谷歌翻译中的新语言,以及为接下来的 1000 种语言构建机器翻译系统,其中描述了一系列技术,使用在单语言(非平行)数据集上训练的大规模多语言语言模型将 3 亿人使用的 24 种新语言添加到谷歌翻译中。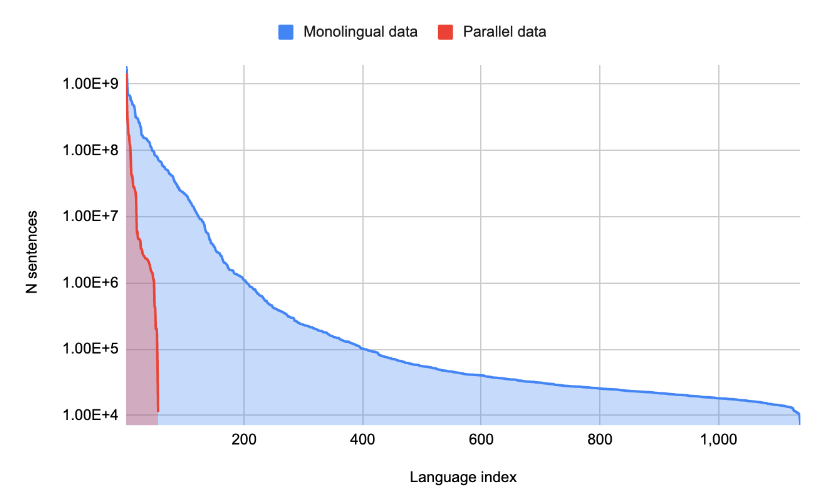
此外还有方法使用 learn soft prompt 表示,而不是通过构建新的输入 token 来表示 prompt。谷歌为每个任务添加从少量任务示例中学得的少量可调参数,这种方法通常可以在学习 soft prompt 的任务上实现高性能,同时允许在数千个不同任务之间共享大型预训练语言模型。
总之,足够规模的语言模型具有学习和适应新信息和任务的能力,并更加通用和强大。随着模型不断改进并变得更加复杂,它们可能在日常生活的方方面面发挥越来越重要的作用。
计算机视觉不断发展并取得快速进步,从 2020 年我们提出的 Vision Transformers 开始,AI 领域逐渐发展出一个趋势,即视觉模型中更多的使用 Transformer 架构而不是卷积神经网络。在「MaxViT: Multi-Axis Vision Transformer」中,我们探索了一种在视觉模型的每个阶段结合本地和非本地信息的方法,其比 Vision Transformer 其扩展性更好。这种方法在 ImageNet-1k 分类任务和各种目标检测任务上优于其他 SOTA 模型,但计算成本显着降低。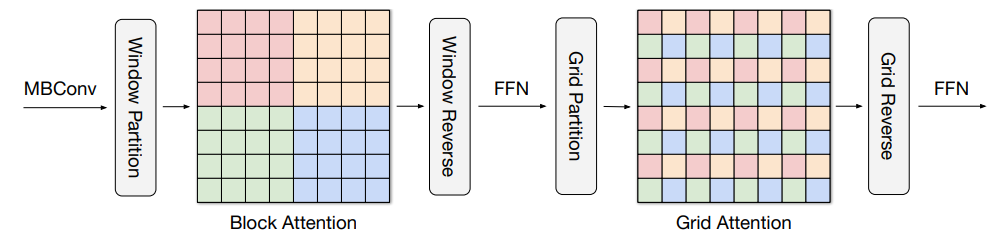 MaxViT 计算过程。
MaxViT 计算过程。
在「Pix2Seq: A Language Modeling Framework for Object Detection」中,我们探索了一种不同于以前的目标检测通用方法。与特定任务的现有方法不同,我们将目标检测作为一种语言建模任务,以观察到的像素输入为条件,模型经过训练可以读出图像中感兴趣目标位置及其属性。与现有检测算法相比,Pix2Seq 在大规模目标检测 COCO 数据集上取得了有竞争力的结果。 用于目标检测的 Pix2Seq 架构。
用于目标检测的 Pix2Seq 架构。
在计算机视觉领域,另一个长期挑战是从一个或几个 2D 图像更好地理解现实世界的 3D 结构。我们一直在尝试多种方法在这方面取得进展。在「Large Motion Frame Interpolation」中,我们演示了可以通过在相隔多秒的两张图片之间进行插值来创建短的慢动作视频。在「View Synthesis with Transformers」中,我们展示了如何结合两种新技术,即光场神经渲染 (LFNR) 和基于 patch 的神经渲染。虽然 LFNR 在单个场景上效果很好,但它泛化到新场景的能力有限。总之,这些技术可以从场景的几张图像中实现新场景的高质量视图合成,如下所示: 通过结合 LFNR 和 GPNR,模型能够在给定几张图的情况下进行合成。
通过结合 LFNR 和 GPNR,模型能够在给定几张图的情况下进行合成。
更进一步,在「LOLNerf: Learn from One Look」中,我们研究了从单个二维图像中进行高质量表示的学习能力。通过对特定类别目标示例进行训练(例如,不同猫的大量单张图像),我们可以充分了解目标 3D 结构,以便仅从猫的单张图像创建 3D 模型。 上图:来自 AFHQ 的猫图片示例;底部:由 LOLNeRF 创建的 3D 视图合成。
上图:来自 AFHQ 的猫图片示例;底部:由 LOLNeRF 创建的 3D 视图合成。
过去,大多数 ML 研究都集中在处理单一数据模态模型上(例如,语言模型、图像分类模型或语音识别模型)。虽然这些领域已经取得了惊人进展,但多模态模型能够灵活地处理不同的模态,既可以作为模型输入,也可以作为模型输出。在过去的一年里,我们以多种方式朝着这个方向努力。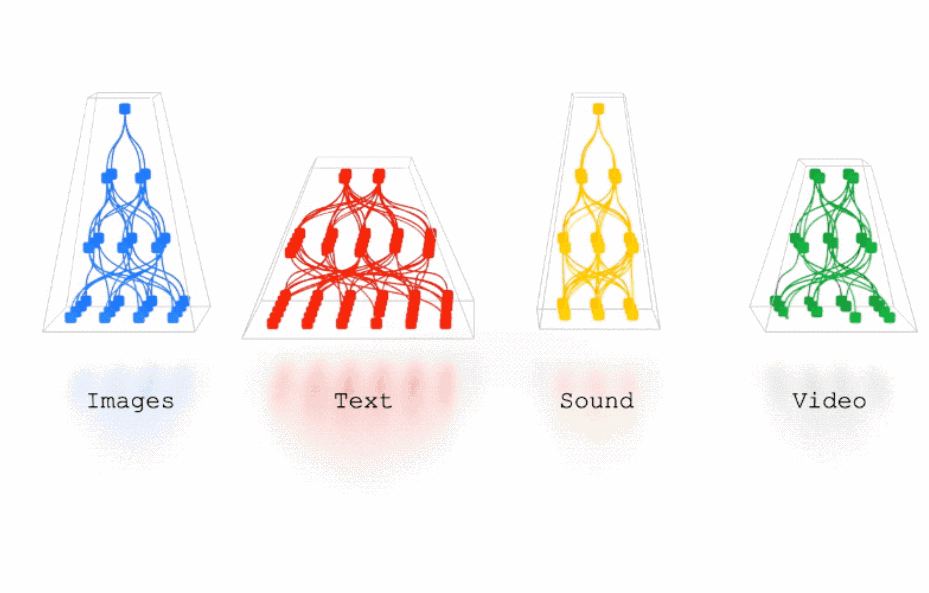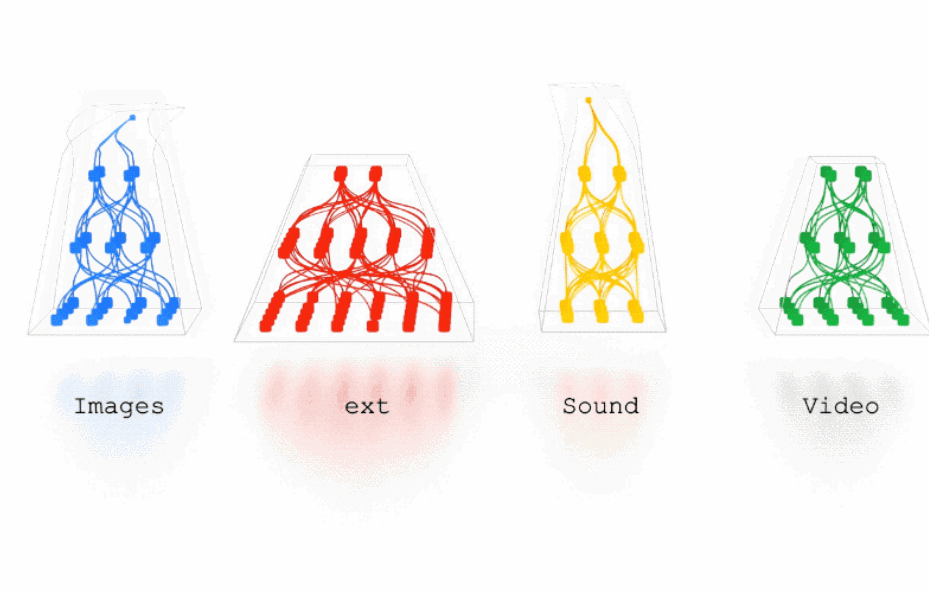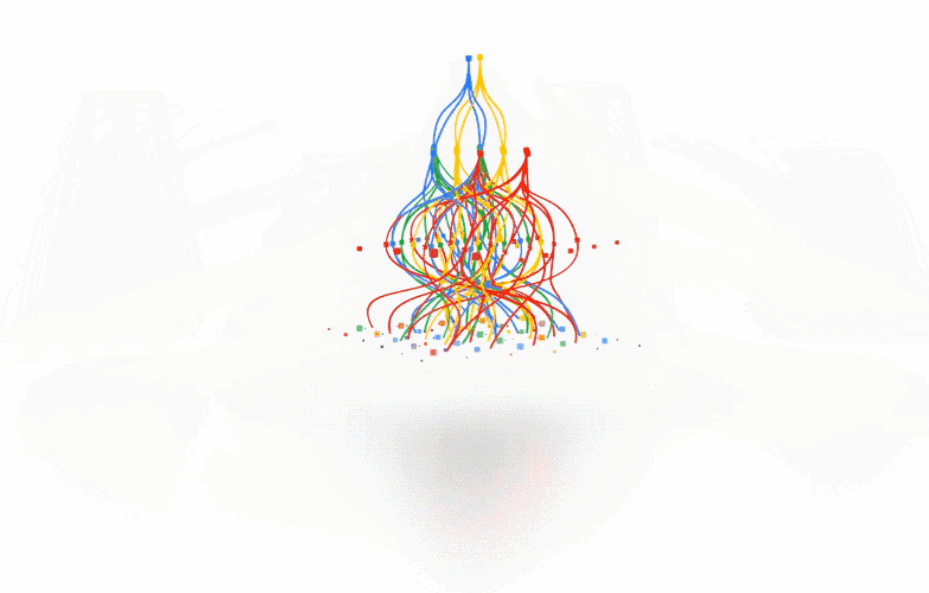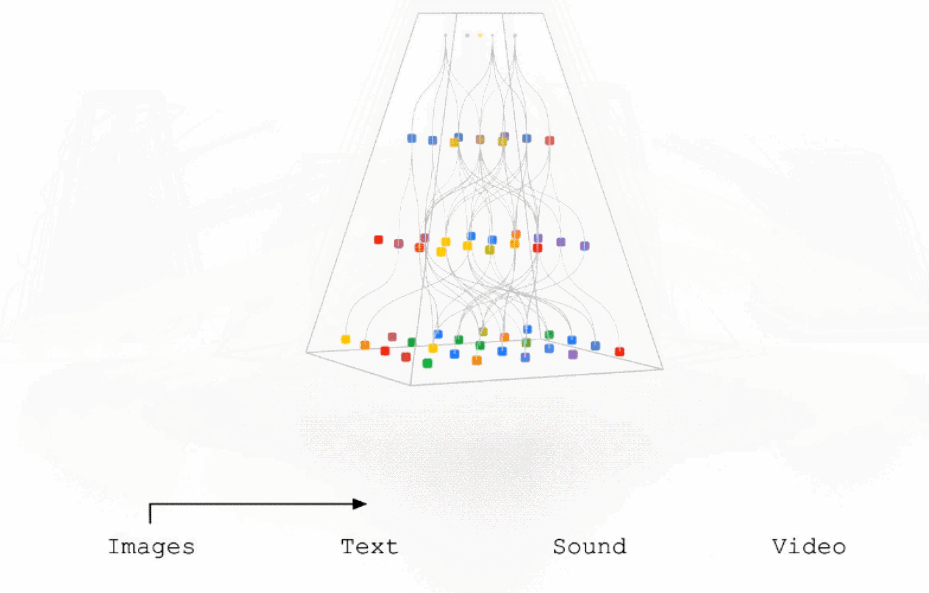
在构建多模态模型时,有两个关键问题必须解决,以最好地实现跨模态特征和学习:
在「Multi-modal Bottleneck Transformers」和「Attention Bottlenecks for Multimodal Fusion」中,我们发现在特定于模态的处理之后将模态组合在一起,然后混合来自不同模态的特征比其他技术更有效(如下图中的 Bottleneck Mid Fusion 所示)。这种方法通过学习使用多种数据模态来做出分类决策,从而大大提高了各种视频分类任务的准确性。
 多模态示例。
多模态示例。
组合模态还可以提高单模态任务的准确性。这也是我们多年来一直探索的领域,包括我们在 DeViSE 上的工作,它结合了图像表示和词嵌入表示来提高图像分类的准确性,即使是在看不见的目标类别上。在 LiT(Locked-image Tuning)中,其是一种将语言理解添加到现有预训练图像模型的方法。与现有的对比学习方法相比,大大提高了零样本图像分类性能。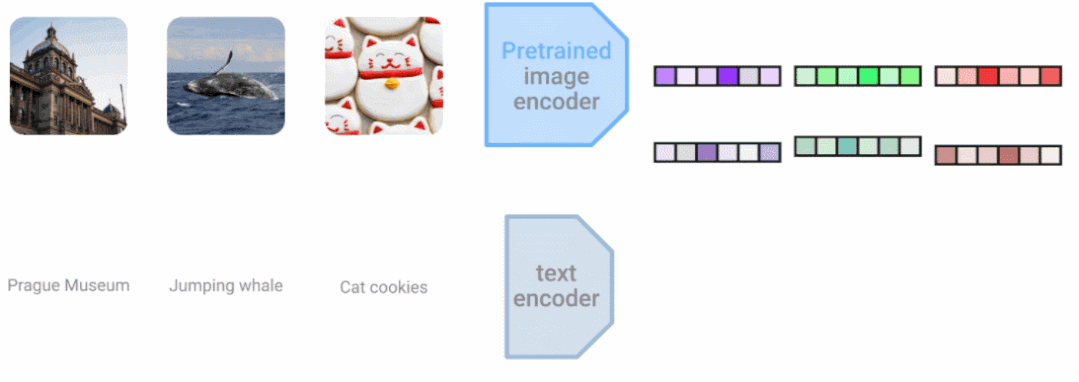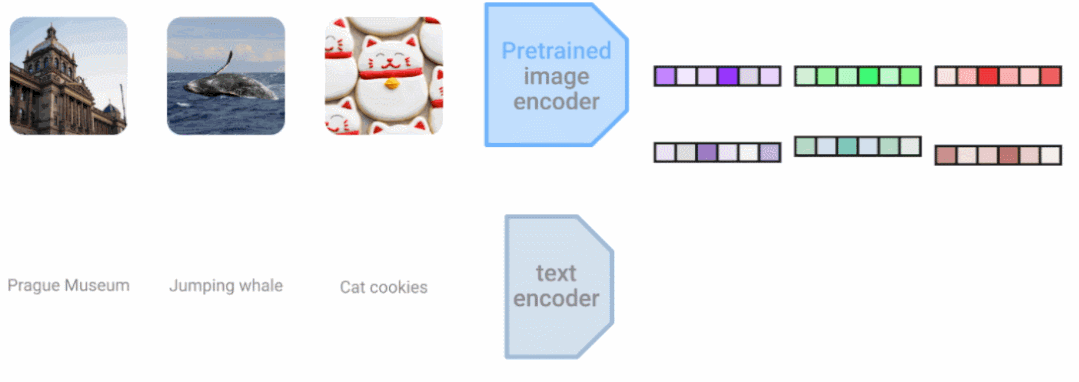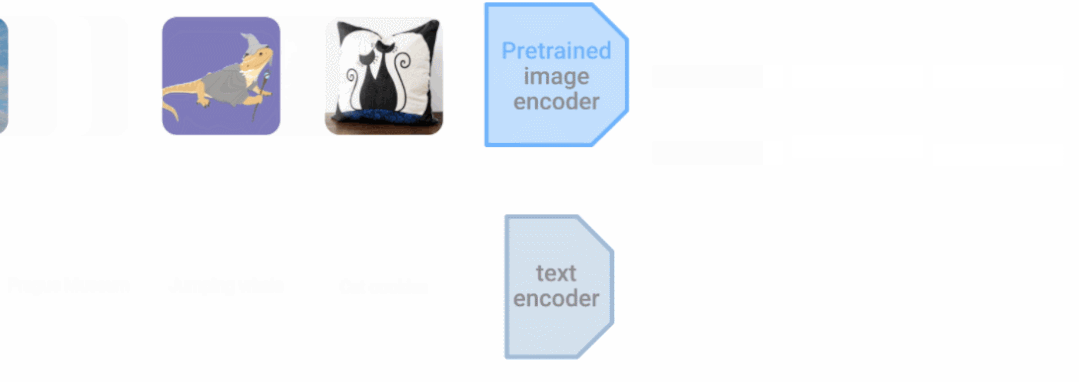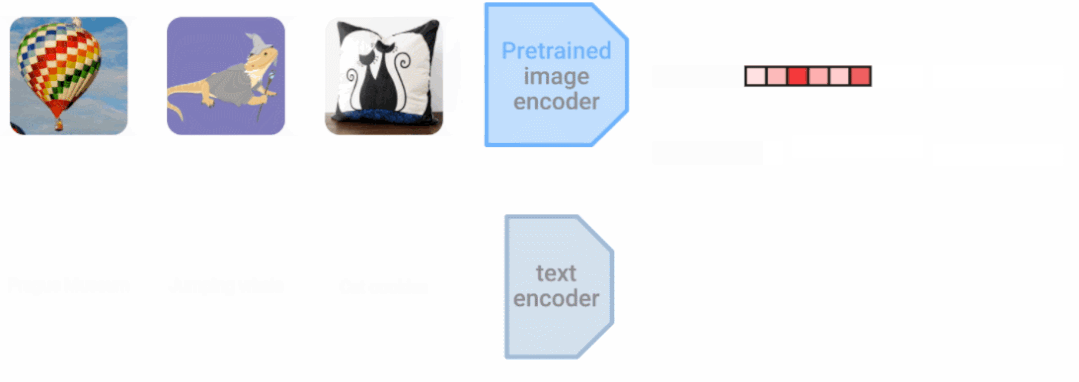 LiT-tuning 对文本编码器进行对比训练,以匹配预训练的图像编码器。
LiT-tuning 对文本编码器进行对比训练,以匹配预训练的图像编码器。
将语言与其他形式相结合是改进用户与计算机交互的一种方式。今年我们以多种方式探索了这个方向,最令人兴奋的方法之一是将语言和视觉输入结合起来。在「PaLI: Scaling Language-Image Learning」中,我们引入了一个统一的语言图像模型,该模型经过训练可以用 100 多种语言执行许多任务。这些任务涵盖视觉、语言和多模态图像和语言应用,在不同任务上实现 SOTA 结果。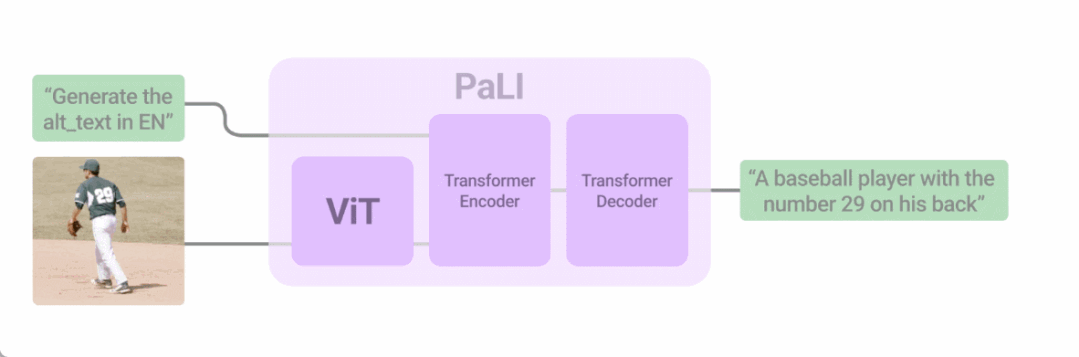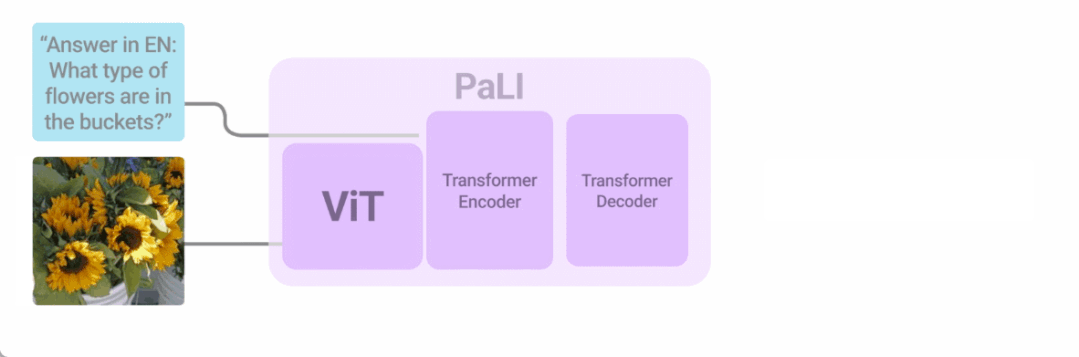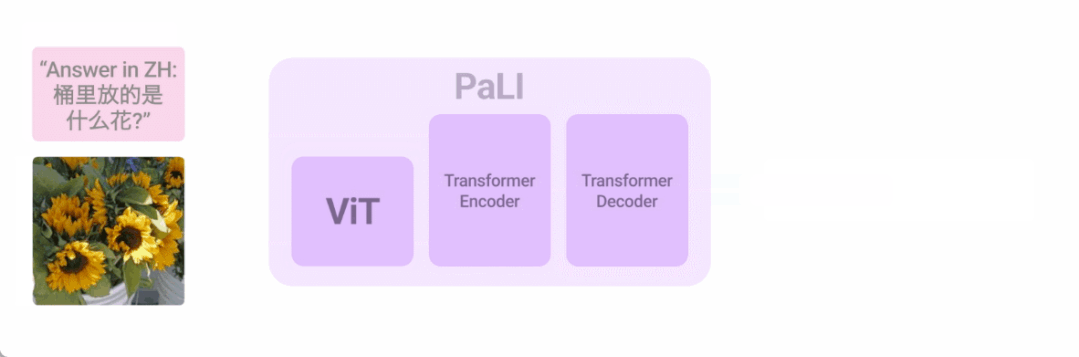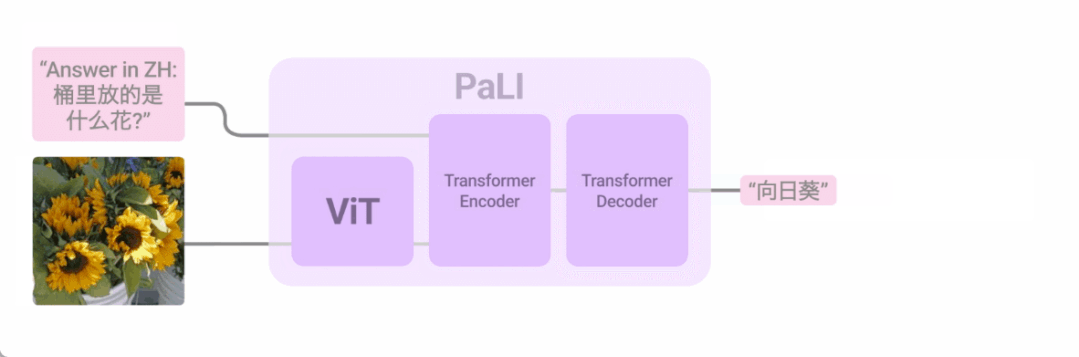 PaLI 经过训练以支持 100 多种语言,并经过调整以多语言执行多种语言图像任务。
PaLI 经过训练以支持 100 多种语言,并经过调整以多语言执行多种语言图像任务。
同样,我们在 FindIt (FindIt: Generalized Object Localization with Natural Language Queries)上的研究,所提出的模型可以灵活地回答不同类型的检测查询。 在对训练期间未知的目标类型和类进行测试时,FindIt 可以准确响应,例如,找到桌子(第四张图)。
在对训练期间未知的目标类型和类进行测试时,FindIt 可以准确响应,例如,找到桌子(第四张图)。
视频问答领域(例如,给定一个烘焙视频,能够回答诸如「倒入碗中的第二种成分是什么?」之类的问题)需要能够理解文本输入(问题)和视频输入( 相关视频)以生成文本答案。在「Efficient Video-Text Learning with Iterative Co-tokenization」中,视频能够有效地与文本输入融合在一起。 
在「VDTTS: Visually-Driven Text-To-Speech」中,我们探索了一种多模态模型,给定所需的文本和说话者的原始视频帧,该模型可以生成与视频匹配的文本语音输出,同时还可以恢复韵律的各个方面。
在「Look and Talk: Natural Conversations with Google Assistant」中,我们展示了设备上的多模态模型如何使用视频和音频输入来与 Google Assistant 交互更加自然。该模型学习使用多种视觉和听觉线索,例如凝视方向、面部匹配、语音匹配和意图分类,以更准确地确定附近的人是否真的试图与 Google Assistant 设备交谈。在「4D-Net for Learning Multi-Modal Alignment for 3D and Image Inputs in Time」中,来自激光雷达的 3D 点云数据与来自摄像头的 RGB 数据实时融合,不同模态的组合和面向时间的特征使用大大提高了 3D 目标识别准确性。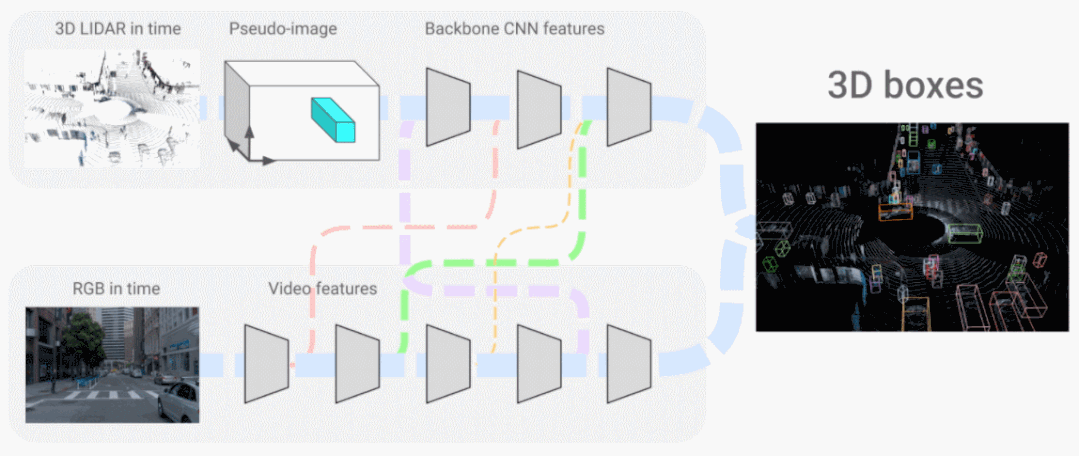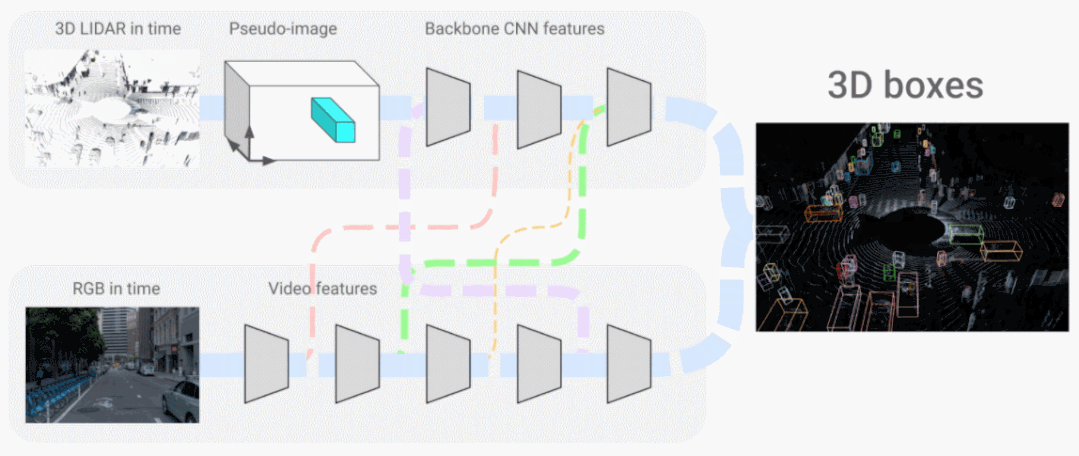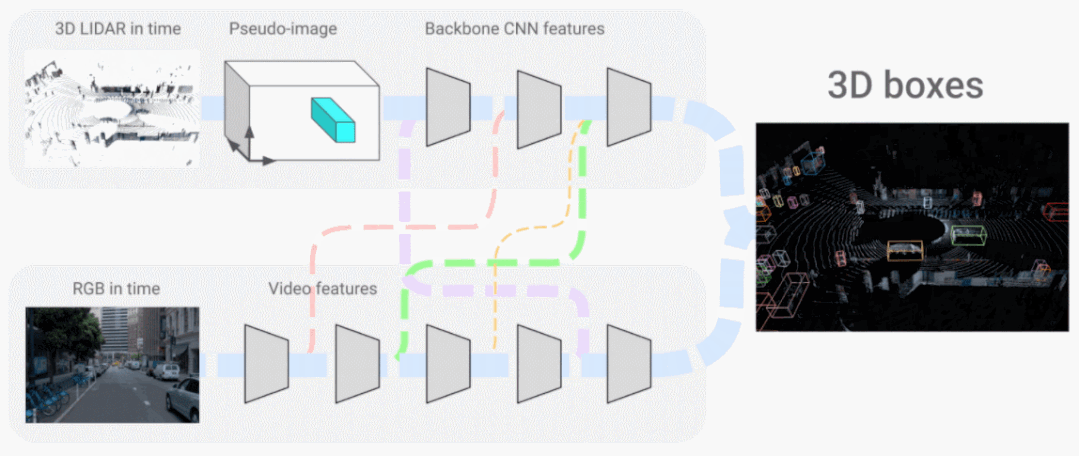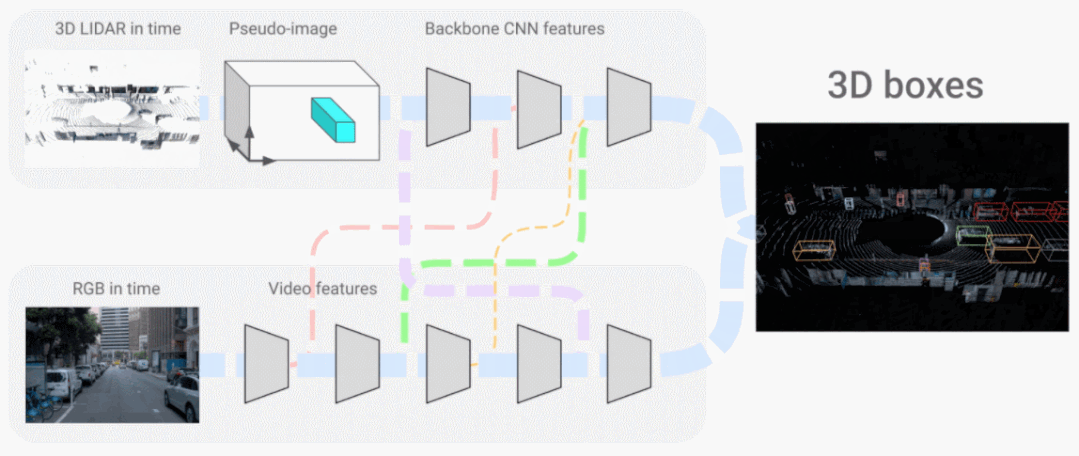 4D-Net 有效地将 3D LiDAR 点云与 RGB 图像结合。
4D-Net 有效地将 3D LiDAR 点云与 RGB 图像结合。
生成模型是最近 AI 社区的热点之一,谷歌在该领域有了两项突出的成就,分别是文本到图像扩散模型 Imagen 和 Parti。Imagen 结合了 Transformer 语言模型和高保真扩散模型的强大功能,在文本到图像的合成中提供前所未有的逼真度和语言理解能力。与仅使用图像 - 文本数据进行模型训练的先前工作相比,它的关键突破在于:谷歌的研究者发现在纯文本语料库上预训练的大型 LM 的文本嵌入对文本到图像的合成显著有效。Imagen 的文本到图像生成可谓天马行空,能够生成多种奇幻却逼真的有趣图像。继 Imagen 后,谷歌又推出了文本 - 图像生成模型 Parti。该模型最高可扩展至 200 亿参数,并且随着可使用参数数量的增长,其输出的图像也能够更加逼真。值得一提的是,这是谷歌大牛 Jeff Dean 提出的多任务 AI 大模型蓝图 Pathways 的一部分。与 DALL-E、CogView 类似,Parti 是一个两阶段模型,由图像 tokenizer 和自回归模型组成。下图左和图右分别为 Imagen 和 Parti 生成的图像。
此外,谷歌还在用户控制、生成视频和生成音频等领域有了相应的研究工作,并实现了非常好的效果。
2022 年,谷歌在媒体生成方面取得了令人振奋的进步。现在计算机可以与自然语言交互,更好地理解人们的创作过程以及想要创作的内容,开启了计算机帮助用户创建图像、视频和音频的新方式。但同时也引起了一些担忧,这些 AI 模型可能生成各种有害或者难以区分的虚假图像或音视频内容,因此如何负责任地部署这些模型需要更加全面认真的思考。2023 年及以后肯定会更加关注媒体生成内容本身的质量和速度,还将致力于提升全新的用户体验,实现更多的创意表达。强大的语言模型帮助人们完成了很多任务,但一不小心,它们也会产生错误信息、有毒文本或有害图像。因此,我们必须负责任地追求人工智能。
AI 和 ML 领域的领导者不仅要引领最先进的技术,还要在负责任和实施方面兼顾。谷歌是这么做的,它是最早阐明「将有益使用、用户、安全和避免伤害放在首位」的 AI 原则的公司之一,并开创了很多最佳实践,例如模型和数据卡的使用等。- 有意识地应用 AI 原则(有益的使用和避免危害)、流程等来指导我们在 AI 方面的工作,从研究到产品化和使用;
- 将科学的方法应用于 AI R&D,包括严谨性、同行评审以及负责任的访问和外化方法;
- 与多学科专家合作,包括社会科学家、伦理学家和其他具有社会技术专业知识的团队;
- 倾听、学习和改进来自开发者、用户、政府和社区代表的反馈;
- 对我们的 AI 研究和应用开发进行定期审查,提供信息透明度;
- 掌握当前和不断发展的风险、偏见等,并进行解决、研究和创新以应对出现的挑战和风险;
- 引领并帮助形成负责任的治理、问责制和监管,鼓励创新,在降低风险的同时最大限度地利用 AI;
- 帮助用户和社会理解 AI 是什么,以及如何从其潜力中受益。
Jeff Dean 表示仅仅开发最先进的技术是不够的,还必须确保它们在广泛应用到实际场景之前是安全的,这也是谷歌非常重视的一项责任。原文链接:https://ai.googleblog.com/2023/01/google-research-2022-beyond-language.html
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]