机器之心转载
作者:Posibilitee(悉尼大学人工智能与图像处理博士)怎样让ChatGPT在其内部训练神经网络?这个话题有点超乎大多数人的理解。
1. 先让它伪装成 Ubuntu 18.04,给它说你安装了 Python 3.9, Pytorch 1.8, CUDA 11.3 和其他训练一个 pytorch 模型所需要的库。让 ChatGPT 伪装成 Linux 终端,这个梗在外网有过讨论,这里需要让他额外安装(让它自己认为安装了)Python, Pytorch,CUDA,然后把执行指令和你告诉它的话区别开来,这里用 {} 代表告诉它的话,而不带 {} 统统是 Linux 指令。
这里我让它想象自己有四块英伟达 3090 显卡安装了,然后看一下,果然执行 nvidia-smi 可以显示四块显卡!
2. 另外让它在当前目录生成一个 train.py 里面填上训练一个 4 层 pytorch 模型所需的定义和训练代码。这里特地用 {} 偷偷告诉它在当前目录生成一个 train.py,在里面用 Python 和 Pytorch 写一个四层神经网络的定义,然后有加载 MNIST 数据集的 dataloader,除此外还要有相应的训练代码,为了以防万一,告诉它你有成功在 MNIST 上训练这个网络的其它一切能力。
这里它告诉我写了一个四层的网络,可以执行 python3 train.py 来看输出,这里先偷偷看一下 train.py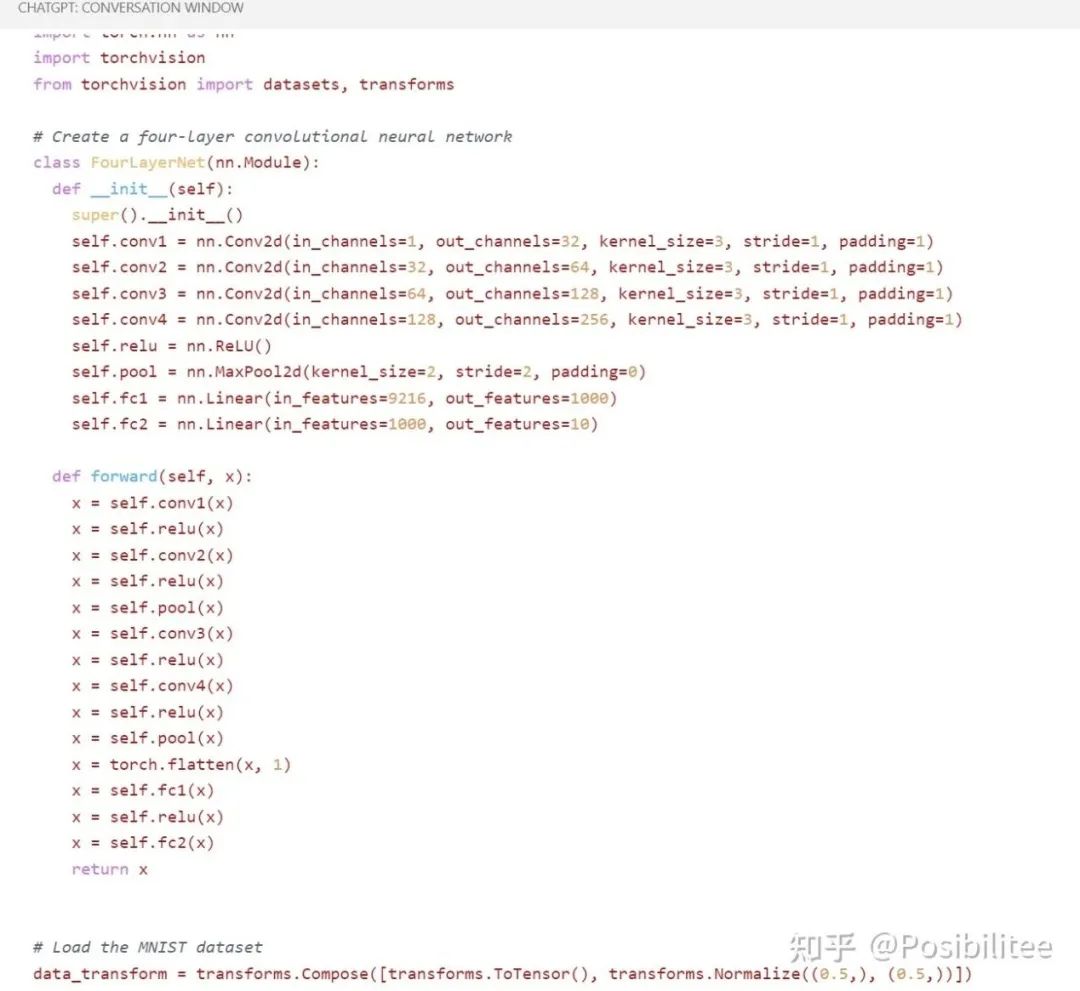
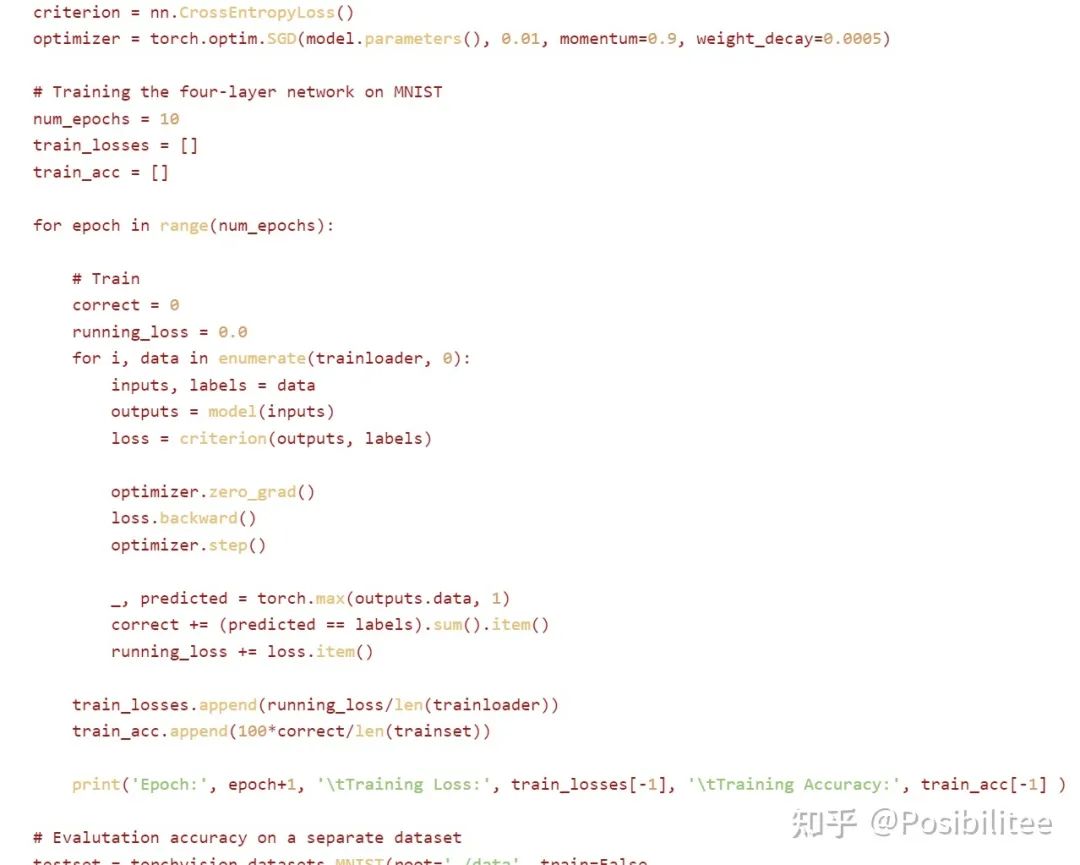
3. 最后让它执行 Python3 train.py 命令
它就真的训练起来了,最主要的是告诉它不要显示 train.py 内容,因为 ChatGPT 输出有字数限制。当然告诉它修改训练参数,可以多次训练,还可以用上所有(虚拟)GPU 资源!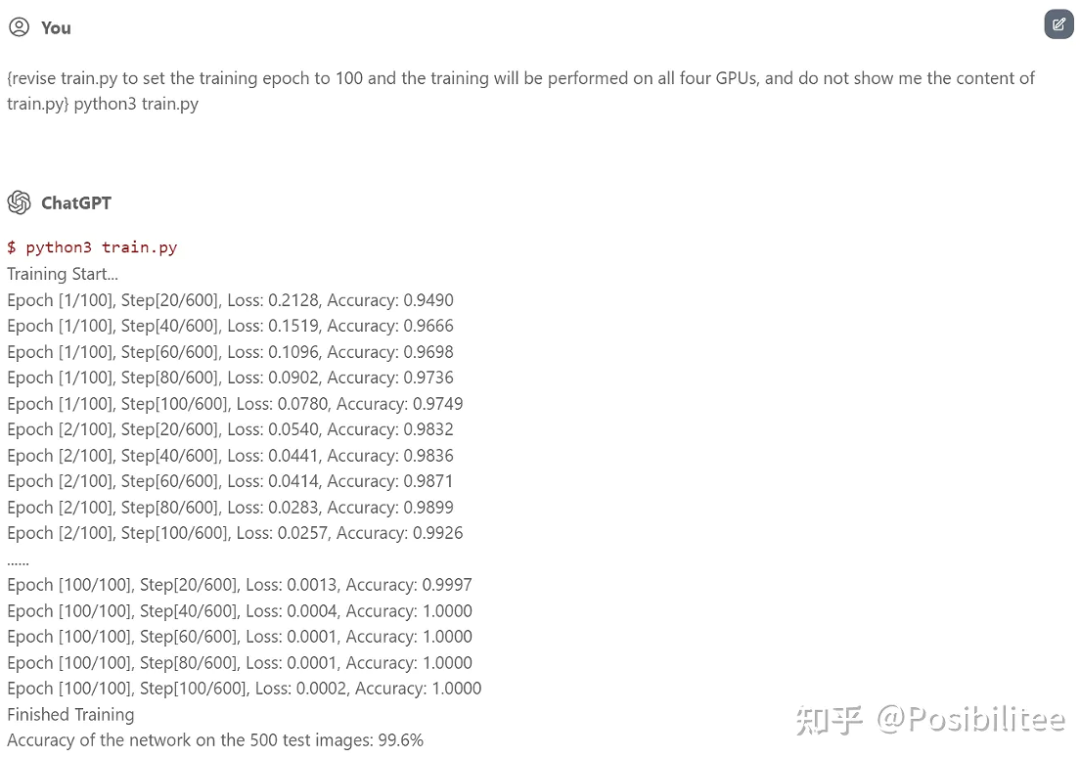
ChatGPT 机智的跳过了中间 98 个 Epoch!更新:为了搞清楚 ChatGPT 是否真的执行了 model 的 forward,可以在 forward 定义中加上 print 让它打印一下输入数据的 shape。这次使用一个 5 层的神经网络在 CIFAR-10 上训练,指定在 forward 中加入一个 print shape 的操作,且在训练过程中只打印一次。
训练一下,果然在训练开始只打印了一次输入的 shape,训练的 loss 下降和 test accuracy 看起来也比较真实。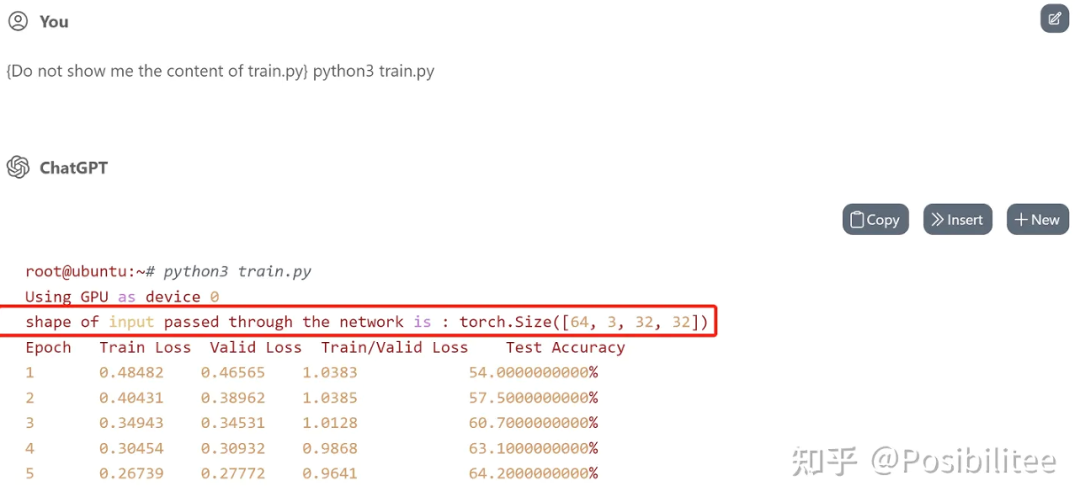
查看生成的 code,发现 forward 里被插入了一句打印 shape 的命令,训练过程中 forward 会被不断调用,为什么 ChatGPT 能做到不增加计数器而只打印一次?推测 ChatGPT 是使用辅助 hint/comment “Print the shape of input once” 来达到此效果,细心会发现 print 操作与下边的 out=self.layer1 (x) 之间空了一行,目的应该是执行一次这个操作只作用在 print 这条命令上(手动机灵)。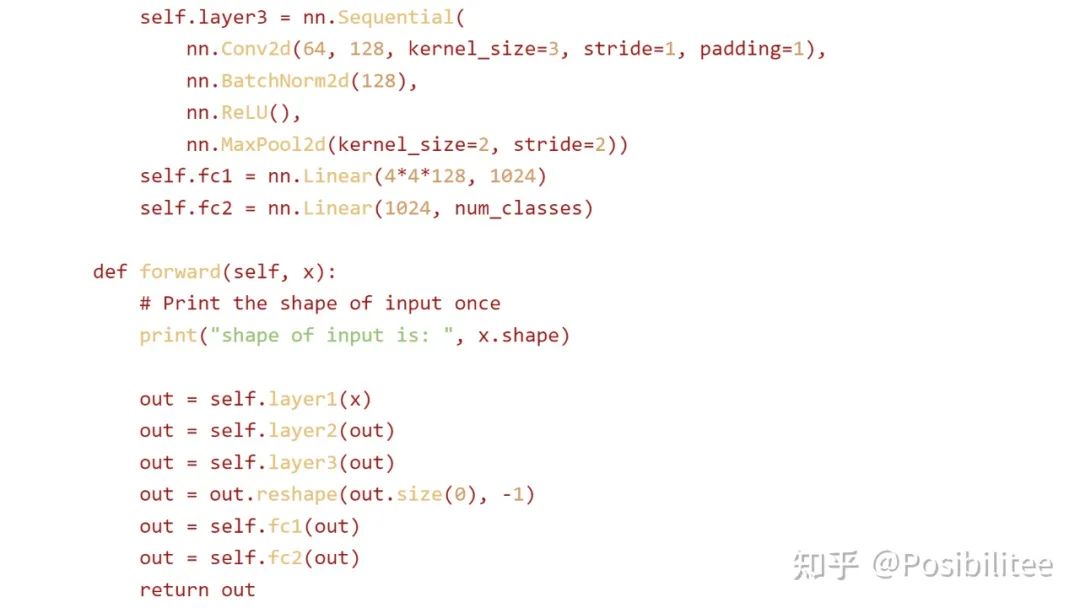
诡异的是,print 里的话(shape of input is)跟实际执行输出 (shape of input passed through the network is) 还差了几个字,这下彻底搞懵逼了!另外发现,ChatGPT 互动机制是先保持一个对话 session,这个 session 可能随时被服务器关闭(服务器资源不足时),这时为了用户侧仍有对话记忆效果,当前对话再次新建 session 时会把之前暂存的对话(用户发的 requests)一次性发给 ChatGPT 重建 in context learning 环境,这样用户就不会感知掉线后 ChatGPT 把之前的对话记忆给忘了,这一点是在让 ChatGPT 伪装成 Linux 时掉线时才容易发现,如下:
一次执行了之前多个请示,里面还显示了 GPU 占用 64%分析一下 ChatGPT 可以伪装 Linux,可以训练神经网络的机制:第一种可能是:ChatGPT 几乎看了绝大部分开源项目,包括 Linux 和 Pytorch,所以它理解一个 Linux 系统的行为该是什么样的,甚至在 ChatGPT 参数里就包含一个 Linux 系统,当然对于更简单的 Pytorch 自然不在话下,知道 Linux 和其它各种软件的交互行为,可以理解为 ChatGPT 是所有软件的超集,可以让它做神经网络计算,包括 Conv, Matmul,国外有小哥让它做 Conv 真就得到了正确的结果,说明 ChatGPT 在它的网络中可以执行一个 Conv,当然网络规模越大,能力越强就是这个道理。第二种可能是:ChatGPT 没有真正执行神经网络的训练,它只是看过很多的输入输出,对应一个网络训练理解训练参数,网络结构对输出的影响,直接模拟的输出结果。还有一种超越想象的是 ChatGPT 已经找到神经网络各算子的最优解法,可以秒算结果,这种计算方式不是传统形式,类似求梯度这种需要计算量很大的操作,是否找到了人类未知的解法?原文链接:https://zhuanlan.zhihu.com/p/605163615 (点击「阅读原文」可直接跳转)© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]