【新智元导读】当社会的焦点都放在打造「ChatGPT级」应用时,热潮之外我们还应做什么。
自2022年11月,ChatGPT上线后,一路开挂。短短两个月,用户量破亿。与此同时,国外微软、谷歌、Meta等科技巨头纷纷下场,发布自家AI产品和模型,可谓来势汹汹。当大家都在狂热追逐催生更多的「ChatGPT级」应用时,或许应该回归理性思考。要看到,ChatGPT背后的大模型只是海平面上的冰山一角,而水平面下的人工智能技术底层创新才是重中之重。2月28日,智源研究院最新发布了FlagOpen飞智大模型技术开源体系,践行的正是这个理念。
ChatGPT的难或它的成功,不在于我们看到的Chat部分,更重要的是下面有一个很强的基座——GPT3.5。如果没有预训练的语言大模型,也就出现不了ChatGPT。此外,从stateof.ai总结的2022年人工智能现状报告中也可以看出,开源模型可谓是寥寥无几。除了EleutherAI的GPT-J/GPT-NeoX外,还有Meta推出的OPT、BigScience开源的集1000多人研发的BLOOM等。但有趣的一点是,最终让生成式AI迎来大爆发,并且催生出所有人都为之狂热的ChatGPT的,还是开源的Stable Diffusion。从PC时代Linux打破Wintel联盟的垄断,到iOS的封闭生态和Android的准封闭生态下RISC-V开源的崛起。其实Linux和RISC-V已经告诉我们如何解决,只是这一次,我们需要从开始就走开源开放的道路。从这个角度来看,人工智能范式的转变,开源大模型功不可没。
正如吴恩达所提出的「更好的机器学习=80%的数据 + 20%的模型」,数据是提升大模型的关键要素。当前,大型语言模型的思路就是,尽可能把大量的数据通过Transformer架构进行机器学习,进而从数据中获取足够多的能力。就在前几日,Meta发布了开源大语言模型LLaMA,只用1/10参数就打败了GPT-3。而其中用到的训练数据就高达1.4万亿个token。但问题在于,互联网上的数据并非可以拿来即用,因此在大模型的训练过程中使用人工标注就非常重要。尤其对于像ChatGPT这样的语言模型,一不小心就出口成脏,甚至发表性别歧视、种族主义等有害内容。巨大的数据集让GPT-3模型拥有强大的能力同时,但也让它背负了最大的诅咒。对语料库进行清洗并没有捷径,即便是一个由数百人组成的团队也需要数十年的时间才能手动浏览完庞大的数据集。那么,接下来的问题是,到底什么样的模型才是一个好的大模型?若仅是单纯比较参数大小,就会缺失了效率等维度。若只看跑分高低,就也看不出落地的效果。因此,真正公正、开放的评测基准和工具不仅可以兼顾理解和生成等自然语言处理领域,而且还要能够回应行业AI模型的差异化、特点鲜明等现状。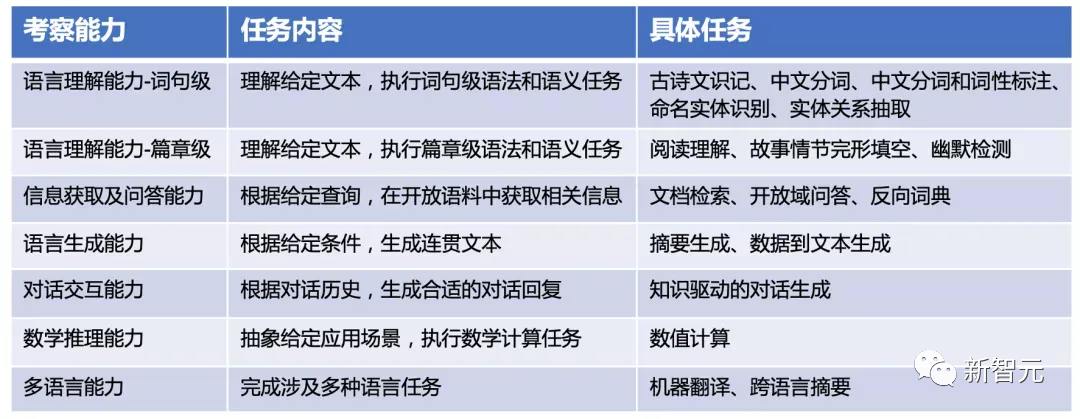
回到最初的问题,如果想要创造性地造出「ChatGPT级」的大模型,刚刚提到的开源模块,例如模型算法、数据处理工具、模型评测工具等,都是必不可少的。由智源研究院与多家企业、高校和科研机构共建的大模型技术开源体系FlagOpen,在努力做相关建设。FlagOpen:打造大模型领域的「新Linux」生态
据介绍,FlagOpen这个开源算法体系和一站式基础软件平台,并不是要去做一枝独秀的大模型,而是更希望将积累的大模型技术栈贡献给整个社区,打造大模型研究的开源创新环境。其中,FlagOpen包括了算法(FlagAI)、数据(FlagData)、评测(FlagEval)等关键性开源组件。而从上文的分析中不难看出,这些实际上都是实现大模型创新的重要组成部分。具体来看,FlagOpen在算法方面推出的FlagAI,集成了全球各种主流大模型算法技术,如语言大模型OPT、T5,视觉大模型ViT、Swin Transformer,多模态大模型CLIP等,以及以及多种大模型并行处理和训练加速技术,支持高效训练和微调。并且还有智源研究院提供的「悟道2.0」通用语言大模型GLM,「悟道3.0」视觉预训练大模型EVA,视觉通用多任务模型Painter,文生图大模型AltDiffusion(多语言),文图表征预训练大模型(多语言)等等。项目地址:https://github.com/FlagAI-Open/FlagAI
在数据方面,FlagOpen构建了全球最大WuDaoCorpora语料库,中文世界首个开放数据标注平台OpenLabel,以及集成了清洗、标注、压缩、统计分析等功能的FlagData。项目地址:https://github.com/FlagOpen/FlagData
而在模型评价方面,学术界一直缺乏能涵盖多种模态领域、多种评测维度的统一化评测体系和项目。尤其在AIGC的发展浪潮下,如何对生成任务进行更高效、更客观的评价,是阻碍大模型落地的重要制约。为此,智源研究院联合了多个高校团队,共同打造了覆盖多个模态领域、包含评测维度的评测工具FlagEval。理论上可以为自然语言处理、计算机视觉等领域的模型训练与部署提供了性能数据层面的有力支撑。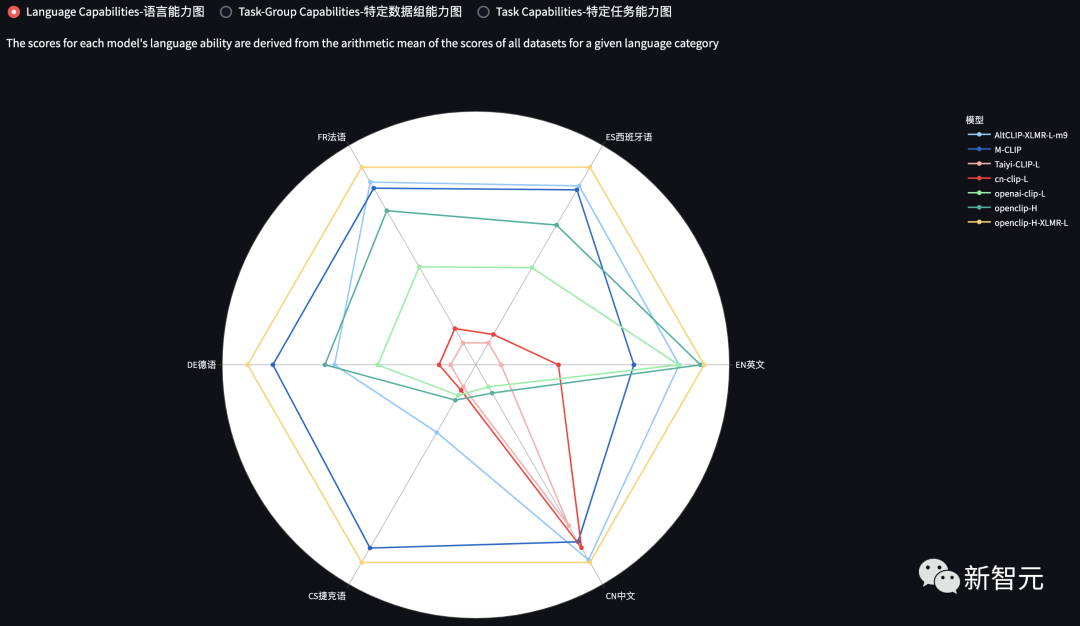
项目地址:https://github.com/FlagOpen/FlagEval最后,FlagOpen甚至还在非常容易被忽视的AI硬件评测方面,提出了不以排名为核心目标的FlagPerf。虽然很少被人提及,但实际上我们在这一领域面临着诸多挑战——AI软硬件技术栈异构程度高、兼容性差,应用场景复杂多变等等。而FlagPerf探索的,便是一套开源、开放、灵活、公正、客观的AI硬件评测体系。基于此,则可以进一步地建立支持多种深度学习框架、最新主流模型评测需求、易于AI芯片厂商插入底层支撑工具的AI系统评测生态。目前,FlagPerf已经和天数智芯、百度PaddlePaddle、昆仑芯科技、中国移动等展开了深度的合作。项目地址:https://github.com/FlagOpen/FlagPerf在FlagOpen的加持下,开发者可以快速开启各种大模型的尝试、开发和研究工作,企业可以低门槛进行大模型研发。FlagOpen本身也在努力实现对多种深度学习框架、多种AI芯片的完整支持。
ChatGPT就像造出的发电机一样可以发电,但也不过仅是点亮了一个街区。若让它走进千家万户,建设起全球的电网,仍然有很长的路要走。这背后的思路说明了,不论是企业,还是学界、各种资源协同焦点都应该放在不断创新、进行大量的技术研究,以及广泛的合作上。目前来看,越来越多的产品不同程度上是建立在开源基础之上,这是一个大趋势。它的优势就在于集约化,不用重复的研发投入。开源,站在「巨人的肩膀」上搞研发,是人类智慧汇聚的一种方式,是让产业更快发展的一种方式。这个时代需要一个像Linux操纵系统平台一样的体系,集算法、模型、数据、工具、评测于一体的体系。智源人工智能研究院,不仅是中国最早进行大模型研究的学术机构之一,也致力于推动人工智能开源开放生态建设。2020年,智源启动「悟道」大模型项目,集结100多名中国人工智能领域顶尖学者进行大模型攻关研究,基于「悟道」项目创造了一系列大模型研究创新成果。在生态贡献方面,智源牵头发布了FlagOpen大模型技术开源体系,推进大模型时代的「新Linux」开源开放生态建设。结合当下ChatGPT热潮,智源研究院院长黄铁军认为,AI现象只是大模型技术「海平面以上」的冰山一角,其超强的智能能力来源于其依托的千亿级参数规模的基础语言大模型,深藏于「海平面以下部分」的基础大模型技术研发体系才是更值得关注的部分。我们应该从长远考虑,打好根基,形成完整的大模型技术体系及强大的资源能力,未来才能催生出更多的「ChatGPT级」的现场级应用。
恰恰,FlagOpen就是为了建立大模型技术体系而开展的基础性工作,通过开源开放的形式促进各类机构共创共享,形成良好生态,共同打牢大模型发展根基。目前,FlagOpen已经与Linux基金会、Stability AI等全球开源代表组织与机构积极合作,加快建设面向全球的大模型技术开源生态。就像Linux、Risc-V,以及PyTorch转入Linux基金会一样,我们需要这样的开源。而FlagOpen大模型技术开源体系,很可能就是开启大模型时代「新Linux」生态的那一把钥匙。https://mp.weixin.qq.com/s/i9z_Z4Rk32u1oAomFFHCEQ
