近段时间,当红炸子鸡 chatGPT 仅凭一己之力,让大模型这个概念深入人心。无数网友在网上问到:“chatGPT 来了,失业还会远吗?” 毫无疑问,所有人都被大模型及其引发的世界范围的科技热潮挟裹着一路向前。不过同时也有人提出,模型的规模是否一定要做得越来越大?细分行业是否一定是使用通用大模型?垂类大模型是否有机会?对此大家意见不一。前不久海外一款名为 ZMO.AI 的生成式营销软件,B 端用户月活迅速突破百万,营收 3 个月内 ARR 增长至 300 万美金的消息,让小编看到垂直领域中,从大模型变异、优化后得到的领域专家模型会有更优的表现。和大家喜闻乐见的艺术风,动漫风的 AIGC 内容不同,营销领域更强调内容的真实性和可控性。ZMO.AI 针对营销产品的真实场景生成,不仅可以 100% 完全可控的保留产品的细节,依据指令生成成千上万不同风格的背景,其逼真度更是堪比大片的商用场景图,无论是光影还是清晰度,都完胜超过 10 年经验的 PS 大师。在这项 Marketing Copilot 产品中,用户只需上传一张产品图,便可从拍摄,到海报制作,到后期投放优化全部嵌入 AI workflow 的自动化流程,利用 AI 强大的创造力和分析能力实现运营秒秒钟优化。ZMO 用多年在营销领域的 Know how 和专业场景数据,让垂类大模型去更好的适应营销用户,并实现了飞速增长。
Marketing Copilot 网址:https://www.zmo.ai/marketing-copilot/ZMO.AI 在营销生成领域扎根已久,在行业内收集了大批高质量的业内数据集,其原生内容生成平台将营销人群作为主要服务对象,强化产品中背景生成,海报生成和数据优化的 AI 能力并为 B 端用户提供 Marketing Copliot,此举为 ZMO 赢得超过百万月活的高价值小 B 端用户并在开启商业化后达到 3 个月达到 300 万美金 ARR 的增长。和其他纯玩目的的 AI 绘画用户不同,B 端的用户面对的是非常专业的场景,无论是对质量的要求,还是对可控性,准确性的要求和 C 端用户相比都极高,这也许也是类似于 ZMO 这样专业化的 AI 内容产品能获得成功的原因。Rowdy 是英国创业公司 e-Bike 的 CEO, 他们是一个不到 10 人的小团队,旗下产品 e-bike 主打电动自行车防盗系统。据 Rowdy 介绍,对于小公司,网站搭建和博客撰写所需要的大量素材非常昂贵,AIGC 的出现大大解放了他们的生产力。不过 Rowdy 发现大量的 AIGC 网站往往是艺术美学风格,和他所需要的真实照片风格相去甚远,而 ZMO.AI 的真实照片风格逼真度非常高,并且分辨率可以达到 4-8k, 已经完全看不出来是 AI 生成的图片了。 这半年来,Rowdy 的团队一直在用 zmo 的产品为网站设计和公司博客配图,每周能生成 200 多张照片。据 Rowdy 描述,“相比于价格高昂的拍摄来说,二十几英镑的软件费用简直太划算了。” 图为 Rowdy 使用 ZMO.AI 生成素材后的公司网页
图为 Rowdy 使用 ZMO.AI 生成素材后的公司网页
Nila 是一家跨境电商的负责人,他们的户外沙发在欧美地区增长非常迅速,不过她也遇到了营销的难点。"对于沙发这种大件拍摄是一件非常痛苦的事情,因为不仅运输成本很高,搭建拍摄场景同样又慢又贵。" 在使用 ZMO.AI 的产品前,Nila 每一次的拍摄都会花十几万到几十万的成本,前前后后折腾一个多月才能上线。“万一内容表现不好,还需要重新拍摄,这里的时间和金钱损失都非常大。” 然而 Nila 发现网上盛传的 Midjourney 或者很多其他的 AIGC 产品完全满足不了她的需求,因为生成的图片中产品的细节会变化,无法 100% 保持原样。Nila 说到 “乍一眼看是差不多的,但仔细比对发现花纹,logo, 材质都不完全一致,货不对板商家是肯定不会使用的。”Nila 在 twitter 上发现 ZMO.AI 这款软件不仅可以完全保持产品的所有细节,还可以逼真的生成光影,无论从分辨率还是真实度上都能完全满足运营人员的需求,这是其他 AIGC 软件所无法达到的。自从 Nila 团队工作流用上 ZMO.AI 后,每一个 SKU 的出图量从原来的不到 10 张瞬间暴涨到 200 张,并且开始借助 Marketing Copliot 大量进行 AB 测试和迭代,将原来三四个月的优化周期缩短到了 2-3 周,销售额更是增长了 3 倍。和 Rowdy 不同,Nick 是美国一家专业营销代理的营销经理,负责帮助广告主搭建官方社媒账号和设计广告素材,Nick 的客户既有线上电商客户,也有传统实业甚至餐饮行业的用户。” 尤其是疫情之后,所有商家都离不开线上营销,但高质量素材确实是一个难题 “ Nick 如是说到。“大多数人根本请不起摄影师或者设计师,都是自己 P 图,或者用 canva 搞定模板。” AIGC 的确能很大程度上解决大家的痛点,但 Nick 发现大多数 AIGC 产品生成的图片中,产品的细节无法保持一致,并且风格和商家想要的风格相去甚远。Nick 提到 “我在 twitter 上看到 ZMO.AI 的场景生成不仅可以完全保持产品的所有细节,还可以生成 4k 以上的光影逼真的真实大片效果,很适合用作产品图。”
不仅如此,让 Nick 最为惊叹的是 ZMO 的 Marketing Copilot 功能完全重新定义的营销人的工作流。“只需要上传产品图,从拍摄,到海报,到内容优化,全能自动化搞定!真实一个成熟的 AI, 能自己做营销了,哈哈” Nick 将客户以前数据表现良好的素材上传到了 Marketing Copilot 训练了自己的专有化生成模型,这样模型的输出就能更符合自己客户的受众喜好和品牌调性。Marketing Copilot 的模型往往会先需要 1-2 周的内容方向自适应调教,反复进行生成素材 -- 数据反馈 -- 素材优化的流程,之后便能生成针对特定产品、特定用户人群浏览量和转化率更高的内容,在这个过程中来自高质量营销数据的反馈功不可没,并且这些数据是私密的,商家完全有控制权。在 Nick 看来 Marketing Copilot 不再是一个简单的内容生成工具,而是改变营销流程的一整套解决方案,通过 AI 更强的分析能力和生成能力,极大的缩短营销各个环节的消耗和协作生产,并以最终数据为导向 24 小时不停歇的优化整个营销内容。Nick 表示团队确实 AI 出现后在考虑缩减一部分营销人员。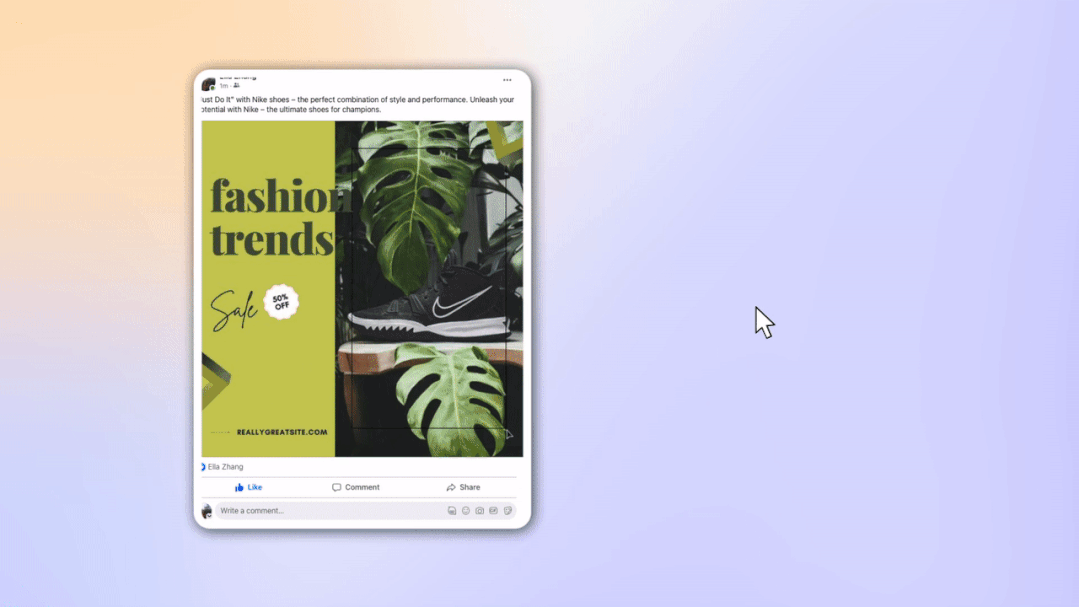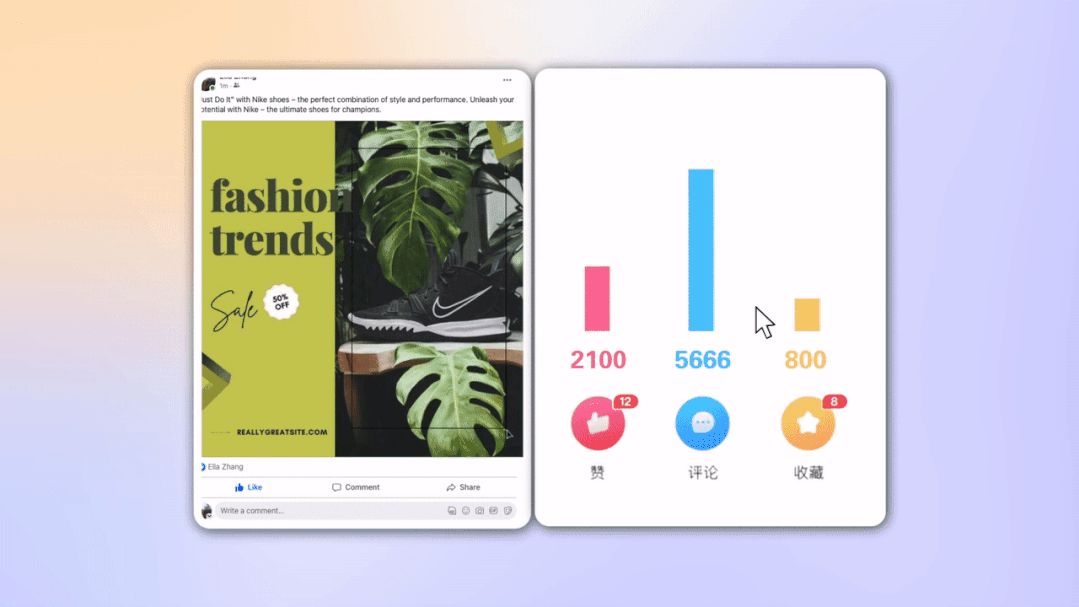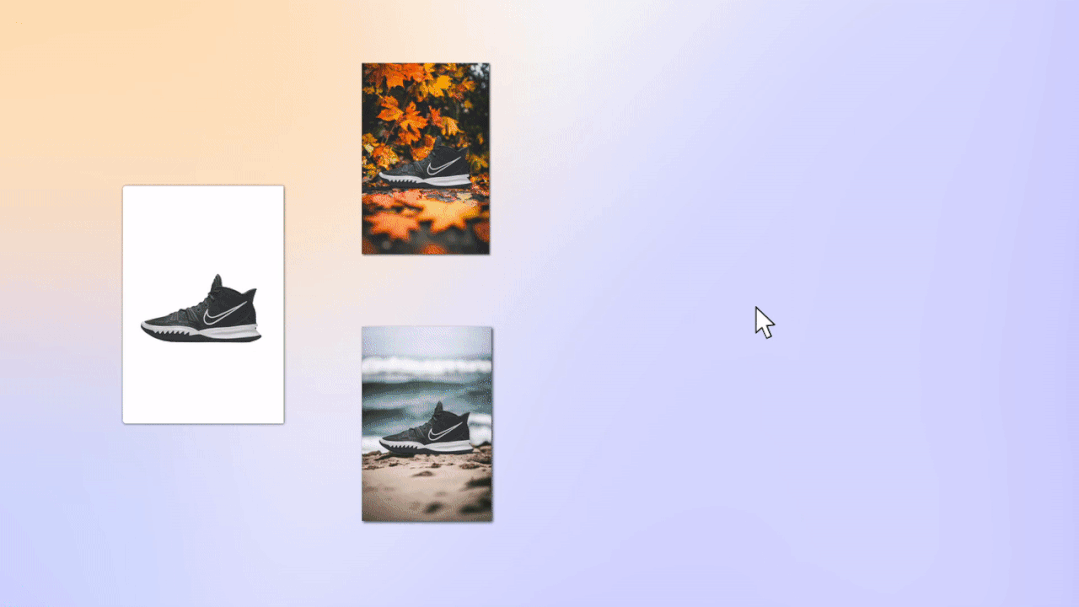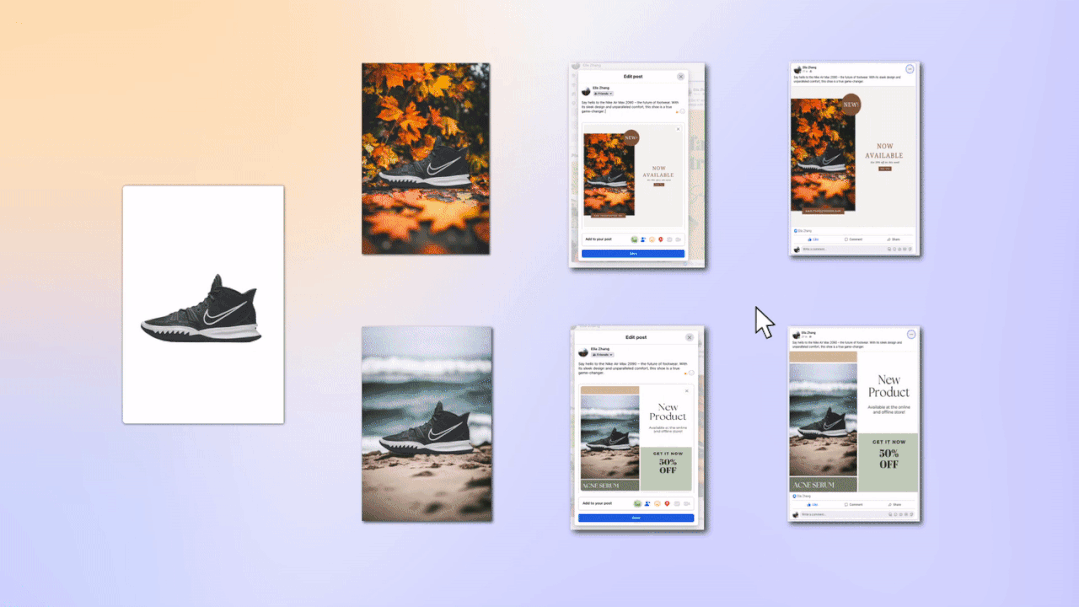
Marketing Copilot 网址:https://www.zmo.ai/marketing-copilot/终极的 AI workflow 到底应该是什么样的,当下下结论为时尚早,但很可能不只是一个空白文本框,后面还连着一个不属于你的 API。当下对于创业公司更重要的是做出能解决商家痛点的产品和用户一起不断迭代,而非空谈和迭代 demo 视频。ChatGPT 能取得如此出色的效果,离不开 RLHF(Reinforcement Learning from Human Feedback)的训练框架。实际上,RLHF 的概念早在 2017 年就由 OpenAI 联合 DeepMind 提出 【1】。其核心思想是在大型预训练模型的基础上,通过人类标注的反馈信息来对模型进行优化,从而进一步提高模型的表现,使之更接近人类认知水平。ChatGPT 的显著提升证明了 RLHF 的有效性。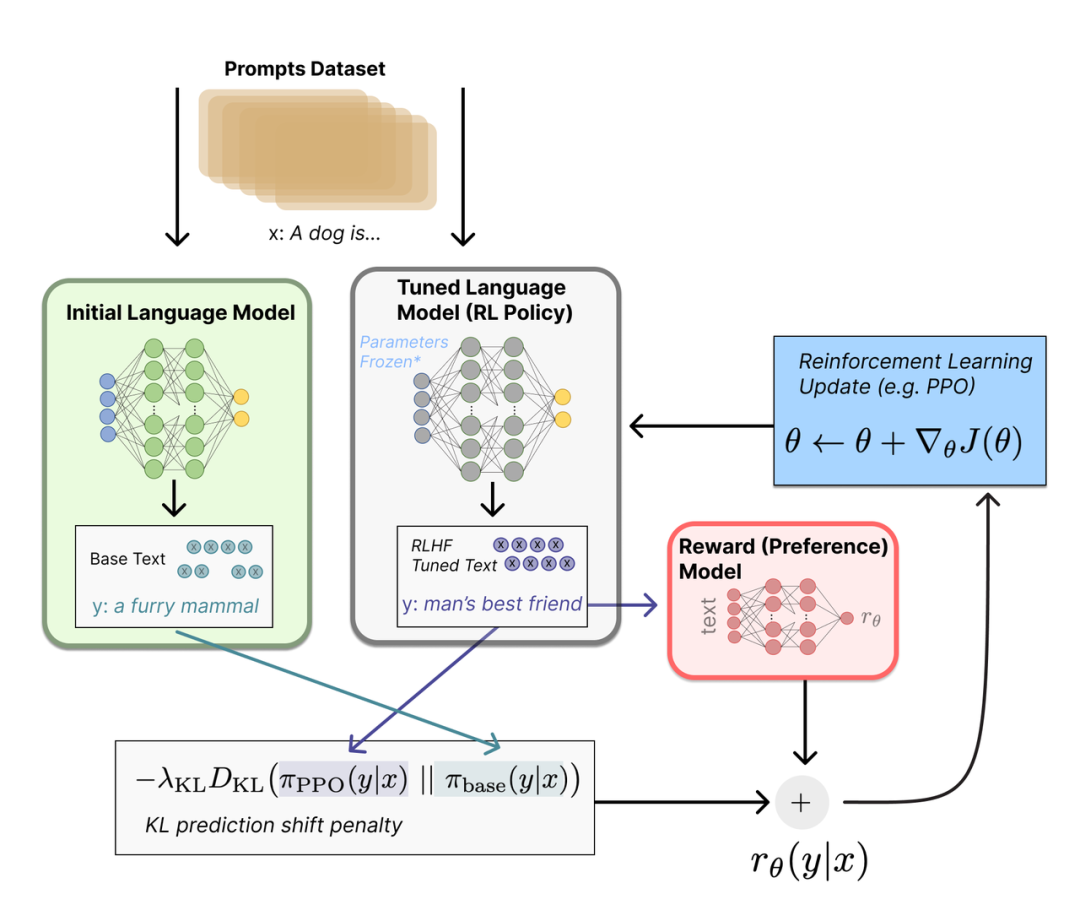
传统的 RL(Reinforcement Learning)假设智能体通过采取行动与环境交互获得反馈,通常通过模拟仿真软件来实现环境。而 RLHF 通过人类反馈信息来优化模型,因此更适用于人机交互场景,如 ChatGPT。但由于需要人工参与,RLHF 的数据标注成本非常高。考虑到数据质量对模型表现的关键影响,RLHF 的数据标注人员必须是专业化的,并且数据集也必须经过精细设计,兼顾多样性和质量。因此,ChatGPT 的高质量数据集,结合 GPT3.5 的先验知识(1750 亿个参数)和 RLHF 的训练框架,才使其能够与人类同频道进行交流。在 RLHF 中,最关键的两个问题是如何设计奖励模型(RM)和如何利用 RM 的反馈来优化模型。OpenAI 提供了一个非常好的先例,首先通过人工标注高度一致的偏序数据来训练一个打分模型作为 RM(例如使用 ELO rating 或其他 learn to rank 方法),然后结合 OpenAI 在 2017 年提出的 PPO(Proximal Policy Optimization)【2】方法对模型进行优化。为了更好地保留模型的先验知识并防止模型过度拟合奖励,还需要在优化目标中添加梯度约束(例如 KL 散度)。此外,RM 和模型两者可以互相迭代优化。在 OpenAI 的竞争对手 Anthropic 的论文中【3】,提出可以在模型优化后的版本上继续优化 RM 来平衡无害性和有效性。目前许多新出炉的垂类大模型,也都尝试了将这一方法拓展到不同领域中。- 论文 1:“Deep reinforcement learning from human preferences” by OpenAI (2017)链接:https://arxiv.org/abs/1706.03741
- 论文 2:“Proximal Policy Optimization Algorithms” by OpenAI (2017)链接:https://arxiv.org/abs/1707.06347
- 论文 3:“Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback”,by Anthropic 2022链接:https://arxiv.org/pdf/2204.05862.pdf
目前大模型参数规模已超千亿,数量级还在不断上升,这样巨大的算力需求量,让算力和芯片的紧缺问题引起国内的重视和焦虑。是否所有领域最后都会被大模型 take all, 在垂直领域中大模型是否是最优解,一些垂类大模型公司给出了不同的看法。Character.AI 专注于 UGC 的个性化聊天机器人,中期月活用户数量达到千万量级,估值达到 10 亿美金。Charater.AI 搭建了端到端的全工程栈,从模型的开发,训练,到数据的收集,终端应用整条价值链。值得关注的是,Character.AI 开发了自己的类似于 GPT 的 Pre-trained 模型,这种 Pre-trained 模型拥有高效的 LLM 推理算法,推理成本远远低于 ChatGPT。相比于其他纯应用型公司,垂类大模型公司在成本上具有明显的竞争优势。Character.AI 的底层模型基于神经语言模型(神经网络语言模型)包含解码器,类似于 GPT 和 LaMDA,并且使用了八位整型来做计算,比平时大家用 16 或 32 位浮点数,效率有 4 倍 - 2 倍的提升,与 GPT3 相比,对话质量更好。八位整形是一种数据类型,它表示一个整数占用 8 个二进制位(bit),也就是一个字节(byte)。八位整形在大模型训练上可以减少内存消耗、提高计算速度,因为它比 16 位、32 位或 64 位的浮点数占用更少的空间。除此之外,和通用大模型相比,Character.AI 的模型更强调 customized 和 RLHF (反馈优化). 不同形象的聊天的机器人会针对特定人设,比如 Lady Gaga 或 Trump 进行基于大量对话、文章、新闻报道或其他数据的 Finetune, 让这个角色输出内容更有个性化。同时,将 RLHF 深刻的嵌入到模型中,通过用户和形象的对话交互来不断迭代优化模型风格。ZMO.AI 的创始人张诗莹也强调了这种用户反馈,“ZMO 模型的内容生成方向受到营销类用户的大量反馈后,确实表现出更倾向于 Instagram 风格的生成的内容方向,类似于模型具有了不同的审美。”
毫末智行专注于自动驾驶认知大模型,旗下的 DriveGPT 模型参数达到了 1200 亿,通过引入量产驾驶数据,训练初始模型,再通过引入驾驶接管 Clips 数据完成反馈模型 (Reward Model) 的训练,然后再通过强化学习的方式,使用反馈模型去不断优化迭代初始模型,形成对自动驾驶认知决策模型的持续优化。为了将驾驶场景变为和自然语言一样的 token, DriveGPT 基于毫末智行的 CSS 场景库理论基础上,使用 BEV 网格将整个空间离散化,同时将每个网格定义为一个固定大小的词表。这样,输入就可以表示已发生场景的 Token 序列,并根据历史生成未来的 Token 序列。同时,毫末也提到了在自动驾驶这个垂类场景中独特的反馈模型。和通用场景的用户反馈不同,DriveGPT 的反馈模型使用带有偏序关系的 Pair 样本对来训练,这些样本对来自于接管 Case,毫末将与人类驾驶结果相似的模型结果作为正样本,与被接管轨迹相似的作为负样本,这样来构建偏序对集合,再利用 LTR (Learning To Rank) 的思路去训练 Reward Model,进而得到一个打分模型。自动驾驶是一个庞大而复杂由多个 AI 组件组成的系统,用通用大模型来替代从规划组件,检测组件到数据标注组件,极可能使得准确性和质量大打折扣。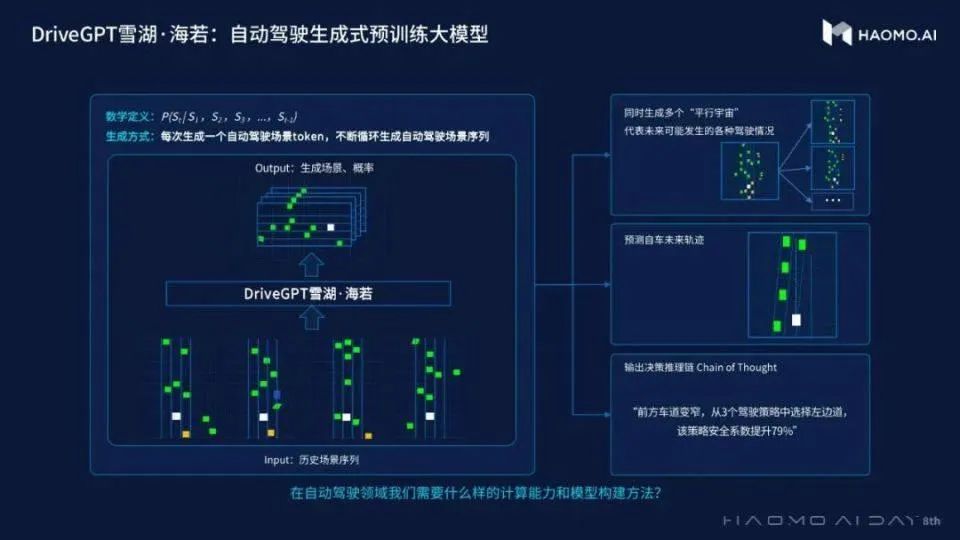
就在前段时间,大名鼎鼎的 Bloomberg 也加入了垂类大模型的战局,推出了 Bloomgberg GPT. 和 to C 场景不同,金融领域需要更高的准确性和可靠性,所以 Bloomberg GPT 在模型层数和参数量上会有明显增加,并采用混合精度的训练策略。
BloombergGPT 将 Context Attention 引入解码器,以生成连贯且与输入文本高度相关的输出。而在编码器部分,B 采用了 Self-Attention 来捕捉输入文本的全局依赖关系。这使得模型能够更好地理解金融领域的长距离依赖和复杂结构。同时在模型的预训练阶段,除了使用通用的大规模文本数据,还会特意加入大量金融领域的数据,如金融新闻、报告、研究论文等。这种 Domain Adaptation 有助于模型在预训练阶段就学习到丰富的金融知识。相比于 chatGPT 这种通用大模型,BloombergGPT 在金融相关任务重表现出较高的性能和专业性,比如实时金融数据处理,能更好的服务于金融领域的需求。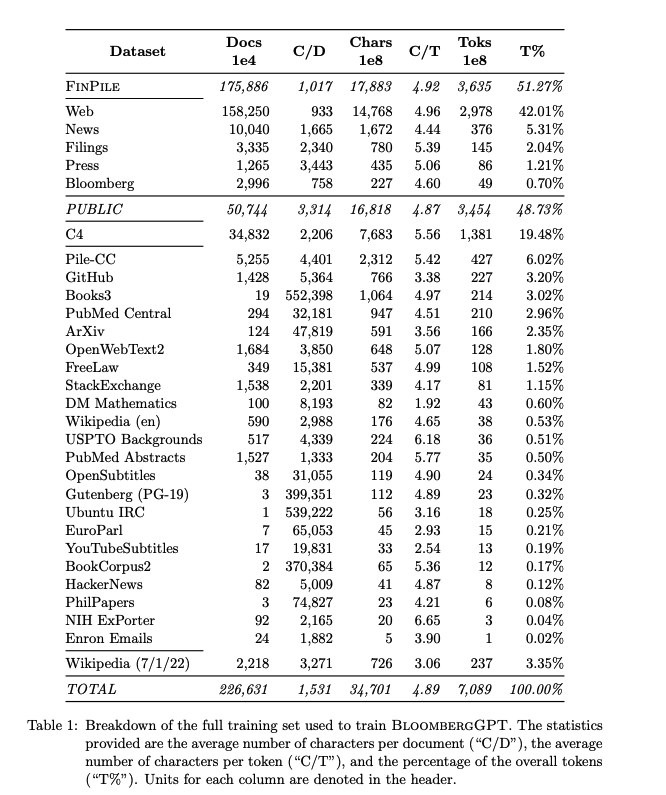
在 ZMO.AI 的场景中,营销场景的专业数据同样重要,真实照片的质量和分辨率能达到目前的高度,很大程度上归功于 ZMO 自有的 6000 万高清营销照片数据集。在 ZMO.AI 的联和创始人马里千看来,虽然基础大模型在许多任务上可以表现出平均人类的水平,但它们在特定垂直领域中表现不佳。这是因为这些领域的领域知识不是常识,相关数据也不容易从互联网上获取。例如,ZMO 为了完整的保留产品细节会需要用到自研的高精度 Matting 算法,Matting 是一项复杂的视觉任务,它涉及准确估计每个像素的 alpha 值,以从图像和视频中提取前景对象。这可能会因为复杂的背景、光照条件和物体透明度等因素而具有挑战性。此外,这项任务的标注是困难、特定和昂贵的,ZMO 花费了一年的时间和高昂的成本才获得这些高精度的标注数据。” 在我们的使用案例中,我们可能会专注于抠图特定对象(例如产品),这可能不是通用大模型的优势所在。“马里千如是说到。AIGC 概念爆火,成千上万的创业者纷纷入局,不过目前许多 AIGC 的产品大多面向灵感触发和可玩性层面,像 ZMO 这样直接面向商用落地的较为少见。和 to C 的 App 不同,商用用户需要更精准的控制、对结果可预期、以及文字排布等场景,并且不同行业除了对质量要求不同,对于输入和输出方式都有维度上的不同,如何构架更符合行业需求的垂类大模型结构,让模型去适应用户,ZMO 在营销场景给出了自己的答案。比如 ZMO 搭建了自有的模型框架来适应营销中互动率点击率这种特别的反馈机制,可以从庞大的数据中抽取真正有价值的监督信号,迭代调整模型参数。这种反馈机制可以将包含了用户对内容质量、潮流、美学等方面的偏好信息,通过基于 RLHF(人类反馈强化学习)的方式纠正模型偏见,生成更符合用户期望的内容,搭建自己更高的护城河。同样在另一个营销人必用的领域海报生成,ZMO 也自研了独特的模型框架。不同于一般的图像生成,海报生成需要考虑多种元素的协调和信息的传达。目前主流的文生图大模型是通过整图生成的方式直接输出最终结果,这种方式不可避免地存在两大缺陷:生成的图像缺乏可编辑性,容易缺失细节质量。为了解决这个问题,ZMO 基于 LLMs 自研了一套 top-down 的可编辑海报图像生成技术,它能够根据用户的偏好和需求,先统一规划各个元素的风格与内容,再通过 layer-wise 的方式逐层生成,再通过美学反馈机制微调得到最终结果,从而生成风格、布局、文字等方面都符合要求的海报。诚然,Character.AI, 毫末智行,BloombergGPT 和 ZMO 都在验证一件事情,大模型终究是需要细分场景的数据和规则的,在特定场景中需要大量专门优化通用大模型来提升生成质量,并且符合这个专业场景的可控输入和输出才能真正的落地使用。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]