

谷歌语音模型USM目前已支持100多种语音自动识别。智东西3月7日报道,根据谷歌官网,谷歌的通用语音模型USM目前已实现升级,支持100多个语种内容的自动识别检测。去年11月,谷歌曾计划创建一个支持1000个语种的AI模型USM。谷歌将其描述为“最先进的通用语音模型”,拥有20亿个参数,经过涵盖1200万小时的语音、280亿个句子和300多个语种数据集的预训练。USM的强大效果目前已在Youtube的字幕生成中展现出来,可自动翻译和检测如英语、汉语等主流语种,还能识别出阿萨姆语这种小众语种,可以说“精通方言”。根据谷歌博客,与OpenAI的大型通用语音模型Whisper相比,USM的数据训练时长更短,错误率更低。
当微软和谷歌还在为谁家的AI聊天机器人更智能而争论不休时,我们需要清楚,语音模型的用途远不止于此。外媒The Verge的记者称,除了相传将在今年的I/O开发者大会中展示的20多款AI驱动产品之外,谷歌目前还在朝着更高目标迈进——构建一个支持1000种语种的机器学习模型。在周一发布的更新中,谷歌分享了更多有关USM的信息,谷歌称,这是构建支持1000种语言的通用语音模型的“关键第一步”。USM已被YouTube用于生成字幕,它还支持自动语音识别(ASR),可自动检测和翻译语言,不仅包括普通话、英语等广泛使用的语言,还包括阿姆哈拉语、宿务语、阿萨姆语等冷门语言。目前,谷歌称USM可支持检测100多个语种,并将作为构建更大的系统的“基础”。不过,这项技术似乎还有些遥远,谷歌在I/O开发者大会期间对阿拉伯语的错误表述就已证明。谷歌研究院科学家张宇(Yu Zhang)和软件工程师詹姆斯·秦(James Qin)在谷歌博客上发文称,为了实现USM这个雄心勃勃的目标,他们目前需要解决ASR面临的两个重大挑战。一是传统的学习方法的缺乏可扩展性。语音技术扩展到多语种的一个基本挑战是需要足够的数据来训练高质量的模型,使用传统方法时,需要手动将音频数据进行标记,既耗时又价格高昂,对于那些小众冷门的语种而言,也更难找到预先存在的来源收集。因此,研究院后续准备将传统学习方法转变为自我监督学习,利用纯音频来收集数据。二是在扩大语言覆盖范围和质量的同时,模型必须以计算效率更高的方法来改进。这就要求学习算法更加灵活、高效、泛化。这些算法需要使用来源广泛的数据,并在不用完全训练的情况下更新模型,再推广到新的语言中。
据该团队发表的论文称,USM使用的是标准的编码器-解码器架构,其中解码器是CTC、RNN-T和LAS,编码器使用的是Conformer或卷积增强变换器。其中,Conformer使用的关键组件是Conformer块,由注意力模块、前馈模块和卷积模块组成,应用一系列Conformer块和投影层以最终嵌入。第一步是使用BEST-RQ来对涵盖数百种语种的语音音频进行自我监督学习,已经在多语言任务上展示了最先进的结果,在使用了大量的无监督音频数据后的证明结果是有效的。第二步需要使用多目标监督预训练来整合来自于其他文本数据的信息。该模型引入了一个额外的编码器模块来输入文本,并引入额外层来组合语音编码器和文本编码器的输出,并在未标记语音、标记语音和文本数据上联合训练模型。最后一步需要USM对下游任务进行微调,包括ASR(自动语音识别)和AST(自动语音翻译)。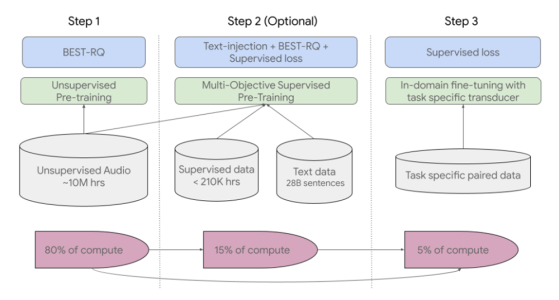
▲USM的整体培训渠道
对于USM的有效性,团队通过Youtube Caption的多语言语音数据进行微调来验证。受监督的Youtube数据包括有73种语种,每个语种的数据不到3000小时。尽管监督的数据有限,但USM在73个语种当中实现了平均低于30%的单词容错率(WER),与当前内部最先进的模型相比降低了6%。与进行了近40万小时数据训练的大型模型Whisper相比,USM的错误率更低,它在18个语种中的解码错误率仅有32.7%,而Whisper有40%。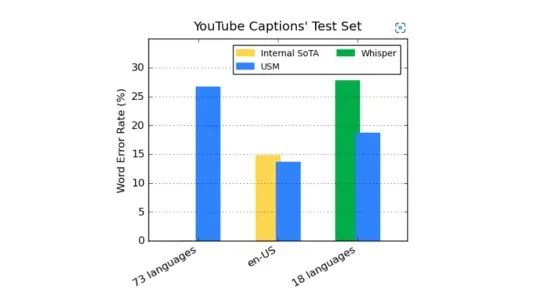
▲在WER低于40%的情况下,USM在其支持的语言上优于Whisper
在公开可用的数据上,与Whisper相比,USM在CORAAL(非裔美国人使用的英语)、SpeechStew和FLEURS这三个语言数据集上都显示出了更低的单词容错率。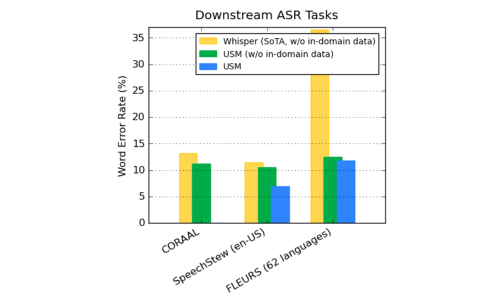
▲在ASR基准上比较USM(有或没有域内数据)和Whisper的结果。
对于语音翻译,团队在CoVoST数据集上微调USM,在有限的监督数据上实现了最好的性能。为了评估模型性能的广度,他们根据资源可用性将CoVoST数据集中的语言分为高、中、低三类,并计算每个部分中的BLEU分数(机器翻译评价指标),根据最终展示出的结果,USM在所有细分市场上的表现都优于Whisper。他们认为,谷歌若想实现连接全球信息并使每个人都能自由访问的愿景,USM的开发将会是关键的一步,USM的基础模型框架和训练通道已经打下了一个基础,他们要做的就是在此基础上将语音模型扩展至1000种语言。
目前,USM已支持100多个语种,未来将持续扩展到1000多个,届时将会吸引到更大一部分用户进行体验,真正实现将信息分发到全球各个角落。信息时代,科技进步将会进一步帮助各个国家地区的语言和文化突破地域的限制,很大程度上解决信息茧房带来的困扰。(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)