语言是人类社会最自然、最有效的交流方式之一,是人类文化融合和信息传播的主要工具。随着全球化与信息化时代的到来,国际间的交流以及信息传播呈现爆发式增长,让计算机理解不同语言并实现语言之间的自动翻译成为人类社会的迫切需求。
语音作为一种自然、便捷且传递信息丰富的语言承载形式,是人类与机器交互的理想方式。
道格拉斯・亚当斯在小说《银河系漫游指南》中提到过一种叫做巴别鱼的神奇生物:体型很小,靠接受脑电波为生。人们可以携带它,它从脑电波中吸收精神频率,转化为营养,再向携带者的思想中发射一种心灵感应信号。如果每个人耳朵里都有一条巴别鱼,就能够让你听懂任何异国语言,达到无障碍交流。
现实中的「巴别鱼」技术 —— 自动语音到语音翻译是指让机器自动完成从一种语言的语音信号到另一种语言的语音信号的翻译过程,比如下面展示的英语到中文翻译的 demo:
原始英文音频:(a great sense of wonder, spontaneity, imagination and creativity.)
目标中文音频:(一种伟大的惊奇感、自发性、想象力和创造力。)
原始英文音频:(now the idea of freedom is inseparably connected with the conception of autonomy.)
目标中文音频:(现在自由的概念与自治的概念密不可分。)
该技术有很广泛的应用场景,例如视频出海、即时通讯、国际贸易等,可以帮助人们打破语言的障碍,更加高效地沟通和交流。一般来说,翻译任务要求确保翻译内容的准确性。针对语音到语音的翻译任务来说,如果能够做到输出的音频音色一致、情感一致、韵律一致、风格一致等效果,可以带来更加友好的用户体验。下面展示一些具有更高应用潜力的翻译效果:
音色一致:
目标英文音频:(The fishermen are inactive, tired and disappointed.)
原始英文音频:(Did he buy or borrow the book?)目标法语音频:(A-t-il acheté ou emprunté le livre)
风格一致:
原始中文音频:(师父,我这就去和他比个高低!)
目标英文音频:(Master, I'll go deal with him right now!)
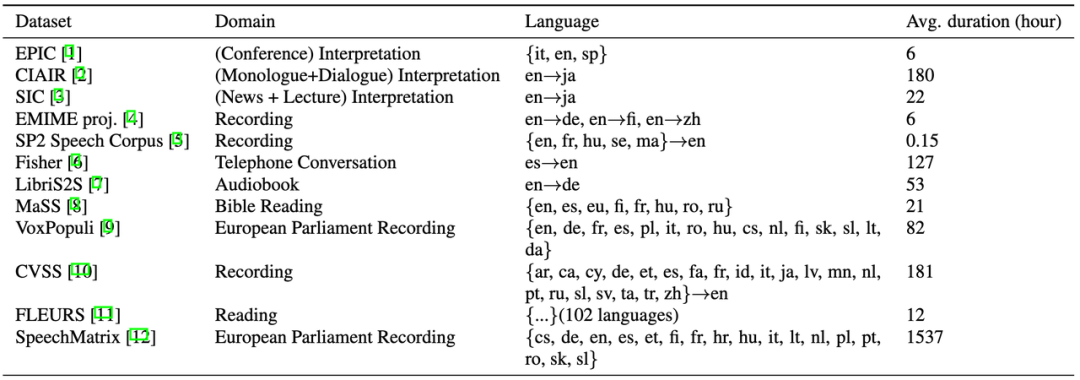
语音到语音翻译的数据集
目前,用于语音到语音翻译全流程对齐的标注数据还比较少。随着端到端的研究范式逐渐流行,越来越多的数据集将会被创造出来。这里整理了一下目前已有的数据集,可以用于训练或者测试。
自动语音到语音翻译通常有两种实现方式。传统的 AI 系统是通过多个单独的模块串联实现,主要包括语音识别、机器翻译和语音合成等,典型的链路如下图所示。

对于级联系统,由于上游模块的输出和下游模块的输入存在不一致,系统会出现错误累积,随着级联模块越来越多,下游累积的误差越多,最终导致整个链路不可用。因此,为了改进整个 AI 系统的可用性,在两两连接的模块之间加入了一些中间件模块。以语音识别和机器翻译的中间件为例,比较常见的处理模块包括 ITN (Inverse Text Normalization)、自动断句、自动标点、口语规范化等。另外每个模块为了适配上游模块引入的错误,以及适配下游模块的输入格式,通常也会对常规模型做一些改进策略。以机器翻译为例,比较典型的提升策略包括鲁棒性机器翻译、基于上下文的翻译、可控机器翻译等。端到端的建模范式近年来开始流行,即通过一个统一的模型直接把源语言的语音信号转化为目标语言的语音信号。端到端的系统有更低的延迟,同时能够缓解级联系统独立模块引入的错误传播问题,对保留源语言音频的声学和韵律信息也有显著优势。另外端到端翻译能够用于没有书写体系的语言的翻译,比如一些中文方言等。

目前,对于端到端语音到语音翻译的研究根据使用的中间声学特征的不同,分为基于连续特征的方法,以及基于离散单元的方法。基于连续特征的方法主要包括 translatotron [13] 和 translatotron2 [14]。Translatotron 包括一个语音编码器,一个说话人编码器、一个频谱解码器,以及两个辅助的音素预测任务。Translatotron2 包括一个语音编码器、一个语言解码器、一个声学合成器以及一个连接前三者的注意力模块。这个单独的注意力模块能够同步提供来自原语音的声学信息,以及目标文本的语言信息,能够在翻译过程中,保留细粒度的非语言的信息。基于离散单元的方法 [15-17] 通常先利用预训练的声学模型(例如 Hubert [18])进行 Speech2Unit 过程,翻译成离散单元,然后利用基于 unit 的声码器生成音频。这种离散单元能够对声学信息和语言信息进行一定程度的解耦。端到端建模方法因为有较大的应用前景,近年来逐渐引起学术界和工业界的关注。但是端到端训练对数据需求比较大,训练数据不足是目前该领域研究中主要的挑战之一。基于伪标注技术的数据增广方法 [19-22] 能够有效缓解这一挑战,比较常见的做法是利用机器翻译引擎得到伪标注的翻译标签,或者是利用语音合成引擎得到伪标注的音频标签等。对语音到语音翻译的端到端评估也是最近流行的研究主题。评测一般包括两个方面,翻译的质量和合成音频的质量。通常来说,人工评估的方法更加可信。但人工评估需要耗费较高的人力和经济成本,构建端到端、可信赖的自动评估指标也是模型快速迭代的需要。最常见的自动翻译质量评估方法是 ASR-BLEU,需要使用一个目标语言的 ASR 模型识别出合成音频的转写文本,再基于该转写文本和参考文本(或者是参考音频的转写文本)计算 BLEU。这个过程会引入 ASR 模型的识别误差,同时指标结果依赖所使用的 ASR 模型,不同研究工作之间无法直接比较数值。近期,Meta 提出了不依赖文本的语音翻译评估指标,BLASER [23],能够直接对跨语言的音频计算翻译得分。随着 AIGC 的日趋流行,音视频翻译也将会是机器翻译新的风口。能够创新出很多不同的玩法,也有可能衍生出不同的产品形态。在数据的爆炸式增长,以及同样增速显著的算力的加持下,端到端建模方法有希望成为新的落地方案。不管是学术界,还是工业界,新的研究范式都是新的赛道,也意味着新的挑战和机遇。未来的机器翻译不再是简单地和文本进行交互,需要得到更多多模态的信息,才能更好地服务于人类。国际口语机器翻译评测 (The International Conference on Spoken Language Translation,IWSLT) 是国际上最具有影响力的口语机器翻译评测比赛之一,主要致力于解决语音翻译技术在实际应用中存在的挑战和问题。第 20 届评测比赛于 2023 年 1 月份拉开序幕,最终的评测结果提交时间在四月份。正式会议将于 2023 年 7 月 13 日至 14 日与 ACL 2023 在加拿大多伦多一起举行,并采取线上线下的混合会议形式。评测报名地址:https://iwslt.org/2023/#registration。关于 IWSLT 2023 的详细信息可以登录评测官网查看:https://iwslt.org/2023/。组委会也提供了评测的交流论坛用于接收比赛的资讯:[email protected] 。字节跳动 AI Lab 火山翻译团队负责组织英中语音到语音翻译评测赛道,并且将提供训练数据和基线。[1] An Approach to Corpus-based Interpreting Studies: Developing EPIC (European Parliament Interpreting Corpus)[2] CIAIR Simultaneous Interpretation Corpus[3] Large-Scale English-Japanese Simultaneous Interpretation Corpus: Construction and Analyses with Sentence-Aligned Data[4] The EMIME Bilingual Database[5] Design of A Speech Corpus for Research on Cross-lingual Prosody Sransfer[6] Improved Speech-to-text Translation with the Fisher and Callhome Spanish-English Speech Translation Corpus[7] LibriS2S: A German-English Speech-to-Speech Translation Corpus[8] Mass: A Large and Clean Multilingual Corpus of Sentence-aligned Spoken Utterances Extracted from The Bible[9] Voxpopuli: A large-scale Multilingual Speech Corpus for Representation Learning, Semi-supervised Learning and Interpretation[10] CVSS Corpus and Massively Multilingual Speech-to-Speech Translation[11] FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech[12] SpeechMatrix: A Large-Scale Mined Corpus of Multilingual Speech-to-Speech Translations[13] Direct Speech-to-Speech Translation with A Sequence-to-Sequence Model[14] Translatotron 2: High-quality Direct Speech-to-Speech Translation with Voice Preservation[15] Direct Speech-To-Speech Translation With Discrete Units[16] UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units[17] Textless Direct Speech-to-Speech Translation with Discrete Speech Representation[18] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units[19] Leveraging Unsupervised and Weakly-supervised Data to Improve Direct Speech-to-Speech Translation[20] Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation[21] Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation[22] Improving Speech-to-Speech Translation Through Unlabeled Text[23] A Text-Free Speech-to-Speech Translation Evaluation Metric
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]