

论文标题:
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
论文链接:
https://arxiv.org/abs/2303.14524
推荐系统已被广泛部署用于自动推断人们的偏好并提供高质量的推荐服务。然而大多数现有的推荐系统仍面临诸多缺陷,例如缺少交互性、可解释性,缺乏反馈机制,以及冷启动和跨域推荐。本文中提出了一种用 LLMs 增强传统推荐的范式 Chat-Rec(ChatGPT Augmented Recommender System)。通过将用户画像和历史交互转换为 Prompt,Chat-Rec 可以有效地学习用户的偏好,它不需要训练,而是完全依赖于上下文学习,并可以有效推理出用户和产品之间之间的联系。通过 LLM 的增强,在每次对话后都可以迭代用户偏好,更新候选推荐结果。此外,产品之间的用户偏好是相关联的,这允许更好的跨域产品推荐。Chat-Rec 为运用 ChatGPT 等对话 AI 进行多种推荐情景的应用提供了有希望的技术路线。
通过Prompt链接LLM和传统推荐系统
如图 1 所示,Chat-Rec 将用户与物品的历史交互、用户档案、用户查询 和对话历史 (如果有的话)作为输入,并与任何推荐系统R接口。如果任务被确定为推荐任务,该模块使用 R 来生成一个候选项目集。否则,它直接向用户输出一个响应,如对生成任务的解释或对项目细节的要求。提示器模块需要多个输入来生成一个自然语言段落,以捕捉用户的查询和推荐信息。这些输入如下:1. 用户与物品的历史交互,指的是用户过去与物品的互动,比如他们点击过的物品,购买过的物品,或者评价过的物品。这些信息被用来了解用户的偏好并进行个性化推荐。2. 用户画像,其中包含关于用户的人口统计和偏好信息。这可能包括年龄、性别、地点和兴趣。用户资料有助于系统了解用户的特点和偏好。3. 用户查询 Qi ,这是用户对信息或建议的具体要求。这可能包括他们感兴趣的一个具体项目或流派,或者是对某一特定类别的推荐的更一般的请求。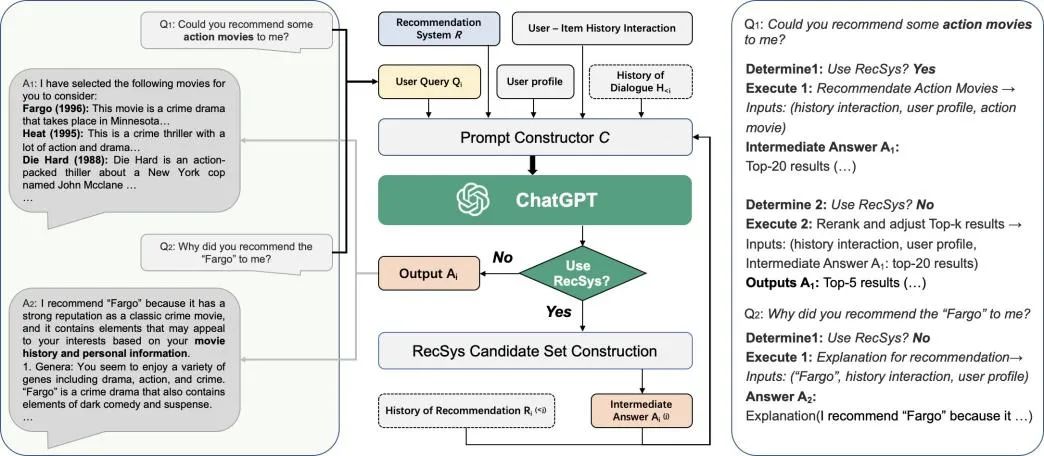
▲ 图1:Chat-Rec 的框架。左边显示了用户和 ChatGPT 之间的对话。中间部分显示了 Chat-Rec 如何将传统的推荐系统与 ChatGPT 这样的对话式人工智能联系起来的流程图。右侧描述了该过程中的具体判断。
传统的推荐系统通常会生成少量经过排序的候选产品,每个产品都有一个反映系统推荐信心或结果质量的分数。然而,但由于产品集规模巨大,现有系统的性能仍有很大改进空间。本文提出了一种使用 LLMs 的方法,通过缩小候选集的范围来提高推荐系统的性能。通过 LLMs,我们将用户的资料和历史交互转换为 Prompt。一旦 LLMs 了解了用户的偏好,推荐系统生成的候选集就会提供给 LLMs。LLMs 可以根据用户的偏好进一步过滤和排序候选集。这种方法可以确保向用户展示一个更小、更相关的物品集,增加他们找到自己喜欢的东西的可能性。如图 2 所示。它显示了不同用户和 LLM 之间的两段对话。其中,用户资料和历史用户被转换为个性化推荐的相应提示,但这部分提示的输入对用户来说是不可见的。左边的对话显示,当用户询问为什么推荐这部电影时,LLM 可以根据用户的喜好和推荐电影的具体信息做出解释。右边的对话显示,Chat-Rec 可以根据用户的反馈进行多轮推荐。关于电影细节的问题也可以用具体的方式回答。LLM 在推荐电影时还考虑到了伦理和道德问题。
有了关于产品的文字描述和资料信息,不管是新产品还是老产品,LLM都能有效地将这些产品相互联系起来,这为我们提供了解决持续的冷启动推荐问题的机会。大型语言模型可以利用其包含的大量知识来帮助推荐系统缓解新项目的冷启动问题,即推荐缺乏大量用户互动的项目。为了解决 ChatGPT 无法及时获取最新的物品信息(现在可以通过插件来实现了),本文引入了关于新项目的外部信息,利用大型语言模型来生成相应的嵌入表征并进行缓存。当遇到新的物品推荐时,计算物品嵌入与用户请求和偏好的嵌入之间的相似性,然后根据相似性检索最相关的物品信息,并构建一个提示输入到 ChatGPT 进行推荐,如图 3 的下半部分所示。这种方法允许推荐系统与 ChatGPT 一起工作,以更好地推荐新项目,从而提高用户体验。LLMs 增强型推荐系统可以用来缓解一些在传统系统中很难解决的问题,例如跨领域推荐。预先用互联网上的信息进行训练的 LLMs 实际上可以作为多视角的知识库。除了一个领域的目标产品,如电影,LLMs 不仅对许多其他领域的产品有广泛的了解,如音乐和书籍,而且还了解上述各领域的产品之间的关系。例如,如图 4 所示,当关于电影推荐的对话结束,用户询问关于其他类型作品的建议。LLM 可以根据用户对电影的喜好,对书籍、电视剧、播客和视频游戏进行推荐。这表明 LLM 有能力将用户的偏好从电影转移到其他项目上,从而实现跨领域的推荐。这种跨领域的推荐能力有可能大大扩展推荐系统的范围和相关性。
实验中使用的数据集是 MovieLens 100K,随机筛选了 200 个用户组成数据集。
实验表明,Chat-Rec 可以根据用户偏好进一步优化推荐系统推荐的候选集。Chat-Rec 框架在 NDCG 和 Precision 指标上都能超过 LightGCN,其中 davinci-003 的效果最好。Chat-Rec 最重要的能力是优化推荐系统的候选集,将用户可能喜欢但在推荐系统的候选集中被放在后面的电影排到前面。这需要应用 LLMs 的电影知识,理解用户的偏好,以及两者之间的匹配关系的能力。为了证实这一发现,在同一对话中再次询问 LLMs 关于那些出现在推荐系统前 5 名但没有出现在 LLMs 前 5 名的电影。LLMs 的反馈表示,用户不太可能会喜欢这部电影,或者很难确定用户是否会喜欢这部电影,并给出了明确的理由。不一致的情况显示,Chat-Rec 的建议是完全基于对用户偏好和电影信息的理解。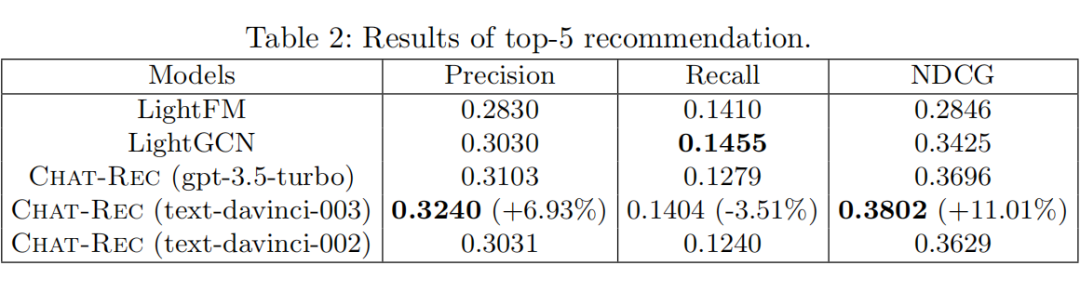
LLMs 可以有效地从用户画像和历史互动中学习用户偏好,而不需要任何的训练,就可以准确预测用户对候选电影的评分。text-davinci-003 取得了最好的结果,
测试了不同 Temperature 和 Prompt 下模型的效果。“w/random”指在提供给 LLM 作为候选集提示输入之前,对推荐系统生成的 20 个候选集进行随打乱,而 “w/top1”则表示在构建提示时,不把排序第一的推荐作为初始背景知识,而是直接要求 LLM 从候选集中选择5部电影。结果表明,在对候选集的顺序进行打乱后,效果略有下降。当不使用 top1 的结果作为背景知识时,会有更大性能下降。同样的结论在不同的 Temperature 下都可以得到。▲ 图5:不同Temperature和Prompt的消融实验Chat-Rec 的提示中没有明确提到推荐系统的存在,推荐系统的功能只是提供一个候选集。然而,候选集的设计会大大影响 Chat-Rec 的性能。而实验表明,Chat-Rec 的提示设计可以有效地将推荐系统的知识隐式地注入到 LLMs 中。这种隐性知识反映在候选电影集的排名顺序中,使用 Top1 作为背景可以进一步加强这种信息。这种隐性知识可以在语境学习中被 LLMs 捕获,并能提高推荐性能。


如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
