©PaperWeekly 原创 · 作者 | 梁钜豪
单位 | 香港中文大学(深圳)& 深圳市大数据研究院
研究方向 | 自然语言处理、信息检索
前言
传统的检索模型往往假设一个任务只对应一个模型(one-to-one),这种范式已经无法满足大量、细化、复杂的检索场景。本文提出了一种新的检索范式:模块化检索。该检索范式通过检索模块的组装来生成新的检索模型,形成了模块和模型之间的多对多关系(many-to-many)。这种模块化思路为检索任务处理带来了强大的泛化性与可解释性。值得一提的是,本文是首篇在检索领域中提出引入模块化思路的研究。本文还提出了一种简单且有效的模块化检索的实现方法 REMOP(Retrieval with Modular Prompt tuning),即利用深度提示(deep prompt tuning)这种参数高效方法来实现检索模块,每一个检索模块对应着一个或多个任务属性。作者还提出了基于任务描述的任务-模块映射方法以及基于可叠加梯度技术的模块合成方法。通过多个探索实验,作者验证了检索模块的三种模块运算的可行性、泛化性和可解释性,并在 BEIR benchmark 上验证了 REMOP 在分布外任务上(OOD)的零样本学习能力。结果表明,REMOP 不仅具有强大的泛化性和可解释性,而且在 OOD 任务的零样本学习能力也达到了最先进的水平。Modular Retrieval for Generalization and Interpretation论文链接:
https://arxiv.org/abs/2303.13419
模块化检索
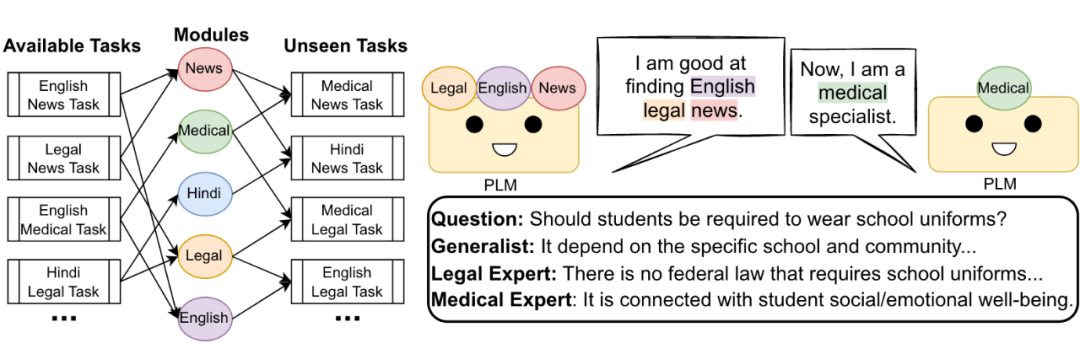
2.1 动机与目的
目前,针对不同的任务,通常的做法是训练一个专门的模型来处理该任务,这种方法是有效且直接的。但是,随着人们生活水平和科技水平的提高,对生成新模型的需求越来越多。例如,对于不同职业的人而言,对于同一个查询所反馈的最佳检索内容并不会完全相同,这意味着为每个不同的用户训练一个单独的检索模型是不现实的,也很费时费力。因此,本文提出了一种新的检索范式:模块化检索。该方法利用模块化学习的方法应用于检索任务中,通过灵活的模块组合的方式得到任务定制的检索模型。这种方法将任务-模型的一对一结构转换为模块-模型的多对多结构,具有更好的泛化能力和可解释性。
2.2 模块化检索的定义
给定一个检索任务,以及一组训练好的检索模块,模块化检索将检索任务分解为若干个任务属性,并根据这些任务属性挑选出对应的检索模块。将这些检索模块与预训练好的语言模型相结合,得到一个全新的针对目标任务定制的检索模型,这个过程不需要额外的训练。
2.3 检索模块与模块运算
本文根据检索模块的功能,定义了两种模块类型:原子模块和复合模块。原子模块指的是只能用于单一类别检索任务的检索模块,而复合模块指的是可以用于多种检索任务的模块。为了使模块可以更灵活地组合成新的检索模型,本文定义了三种基本的模块运算能力:1. 模块缩放 Module Scaling:对已训练的模块进行权重调整,以表示对应的任务属性在目标任务中的重要程度;2. 模块加法 Module Addition:将两个不同的(原子或复合)模块相加,得到一个新的模块,该新的模块同时拥有前两个模块对应的检索能力;3. 模块减法 Module Subtraction:与模块加法相反,模块减法的目的在于去除已训练模块中不需要的部分,从而得到更广泛应用于领域的检索模块。
方法实现:REMOP
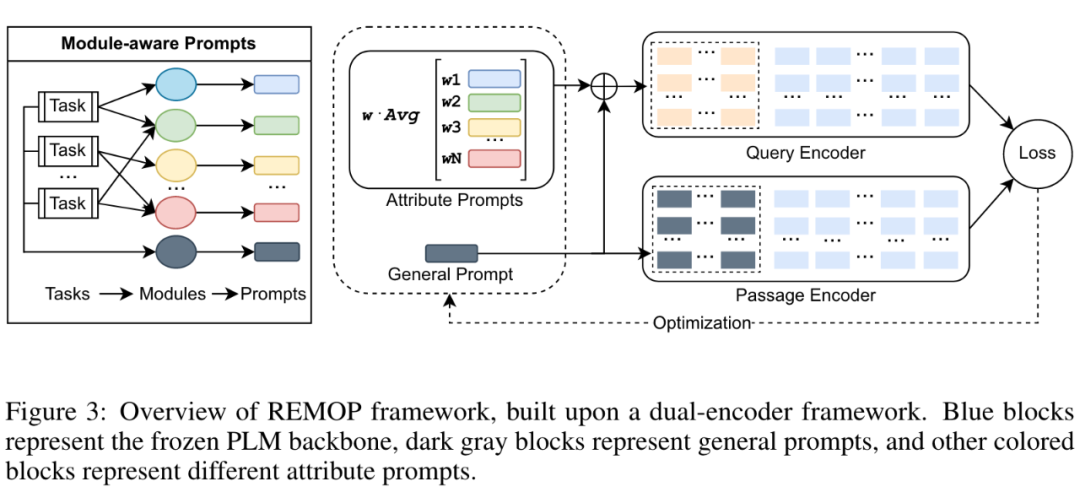
3.1 模型结构
如上图所示,REMOP 是一种基于 dual-encoder 结构的 DPR 模型。它的任务是根据给定的查询(query),检索最相关的文本段落(passages)。该方法分别对查询和段落进行编码,然后在编码空间中搜索与查询最接近的段落,最接近的段落被视为对该查询的检索结果。与传统的 DPR 模型相比,REMOP 额外的引入了与模块化学习相关的组件:一个通用的检索 prompt 和多个针对属性的检索 prompt,由 deep prompt 实现。通用 prompt 用于查询编码器和段落编码器,而属性 prompt 仅作用于查询编码器。这种策略可以有效节省计算和存储资源,对于相同的 passages,只需要进行一次编码即可适应不同的查询场景。
3.2 检索模块的实现及训练方式
Deep Prompt 是一种常用且有效的 parameter-efficient 方法,可以通过训练少量的参数达到与全体参数训练一致的效果。本文作者利用 Deep Prompt 结构实现了检索模块。在实现中,一个检索模型由一个预训练的语言模型、一个通用 prompt 和若干个属性 prompt 组成。预训练好的语言模型被冻结并不参与训练,通用 prompt 用于存储不同类型任务之间的通用知识,而属性 prompt 单独存储不同的任务属性知识。这种实现方法为未来可能存在的大量任务属性知识学习提供了存储和计算的高效性。训练过程被分为两个阶段。第一阶段使用通用的检索任务(例如 MSMARCO 任务),单独训练 general prompt,以让其学习通用的检索能力。第二阶段联合训练多个 attribute prompts,并使用较小的学习率微调 general prompt。这样可以使 general prompt 更好地桥接多个 attribute prompts 和预训练模型,从而有效解决模块化学习中不同模块之间的兼容性问题。此外,这种多个 attribute prompts 的联合训练方法也能有效降低训练成本。
3.3 任务分解与模块合成

如何正确地将任务分解为模块是模块化学习的关键之一。本文根据各个任务的指示(task instructions)将任务分解为多个任务属性。例如,将 SciFact 数据集根据其任务指示 “Retrieve a scientific paper sentence to verify if the following claim is ture” 分解为 science 和 fact-checking 两个任务属性。然后,将对应的两个检索模块与预训练好的大模型组合起来,形成针对该数据集的一个检索模型。如何组装训练模块也是一个关键点。在 REMOP 方法中,各个检索模块是由 Deep Prompt 结构实现的。因此,本文利用了在联邦学习中常见的加权平均方法(weighted averaging)对各个模块进行融合。同时,本文给出了一个基于梯度累加的模型融合的直觉解释:不同的 attribute prompt 相当于基于 general prompt 的针对特定任务属性的累积梯度。通过不同 attribute prompt 的累加,可以理解为模型在不同属性任务集合中按顺序进行训练。
实验与分析
4.1 模块运算可行性探究
在本部分中,作者对模块化检索范式中定义的三种模块运算进行了实验分析:模块缩放、模块加法与模块减法。在模块缩放实验中,作者利用不同的缩放权重对模块进行调整,在 100k 的合成数据中进行训练,并在额外的 1k 的合成数据中进行测试。结果表明,当模型缩放权重设为 0.5 时,模型在大多数任务中表现最佳。在模块加法的实验中,作者对比了平均求和与直接相加的模块相加结果,发现平均求和的实现方法中,两个模块平均融合的性能可以超出只使用单个模块的性能。在模块减法的实验中,实验结果也同样说明了模块减法的有效性。
4.2 模块化检索在零样本学习的表现
在零样本学习任务 BEIR 中,REMOP 展现了优秀的泛化能力及可解释性。如上图所示,与传统的精调语言模型(DPR-vanilla, fine-tune all parameters)相比,REMOP 在使用更少的训练参数量的情况下展现了相当的零样本学习的检索能力。而与只使用单一的 prefix prompt 模型(DPR-prompt)相比,REMOP 在所有任务上的表现都高于 DPR-prompt,这表明,模块化之后的检索模型,针对不同任务的属性,有效地提升了零样本学习能力。
相关工作
本文是第一篇正式将模块化学习引入到检索模型中的工作。在此之前,模块化学习已经在许多机器学习领域中展现了其独特的泛化性和可解释性。DEMIX [1] 使用专家层(expert layer)实现领域模块(domain module);ATTEMPT [2] 工作中训练了多个针对任务的 prefix prompt,并按照一定的权重组合以处理下游任务;MAD-X [3] 和 AdapterSoup [4] 两篇工作利用 adapter 结构来实现模块化。下图展示了 REMOP 与几个相关工作的优劣对比,可以看出,相对于传统的检索模型 DPR、DPTDR 而言,REMOP 利用模块化学习的思想提高了检索模型的泛化能力、可解释性。而相比于其他模块化学习的方法而言,REMOP 利用针对任务属性的深度提示(task-attribute-specific deep prompt)实现检索模块,通过模块的组合方式得到新的定制化检索模型,同时兼顾了模型的泛化性、可解释性以及参数高效性(对低资源任务的友好)。
总结
本文提出了一种新的检索范式:模块化检索。通过组合检索模块的方式搭建新的检索模型,该模型能够与目标任务高度适配。作者利用深度提示训练提供了一种简单且有效的模块化检索实现方法 REMOP。该方法展现了优秀的泛化能力和可解释性,并在零样本学习任务中表现出优秀的效果。[1] Suchin Gururangan, Mike Lewis, Ari Holtzman, Noah A Smith, and Luke Zettlemoyer. Demix layers: Disentangling domains for modular language modeling. arXiv preprint arXiv:2108.05036, 2021.[2] Akari Asai, Mohammadreza Salehi, Matthew E Peters, and Hannaneh Hajishirzi. Attentional mixtures of soft prompt tuning for parameter-efficient multi-task knowledge sharing. arXiv preprint arXiv:2205.11961, 2022.[3] Jonas Pfeiffer, Ivan Vuli ́c, Iryna Gurevych, and Sebastian Ruder. Mad-x: An adapter-based framework for multi-task cross-lingual transfer. arXiv preprint arXiv:2005.00052, 2020.[4] Alexandra Chronopoulou, Matthew E Peters, Alexander Fraser, and Jesse Dodge. Adaptersoup: Weight averaging to improve generalization of pretrained language models. arXiv preprint arXiv:2302.07027, 2023.
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
