从 ChatGPT 到 AI 画图技术,人工智能领域最近的这波突破或许都要感谢一下 Transformer。
今天是著名的 transformer 论文提交六周年的日子。

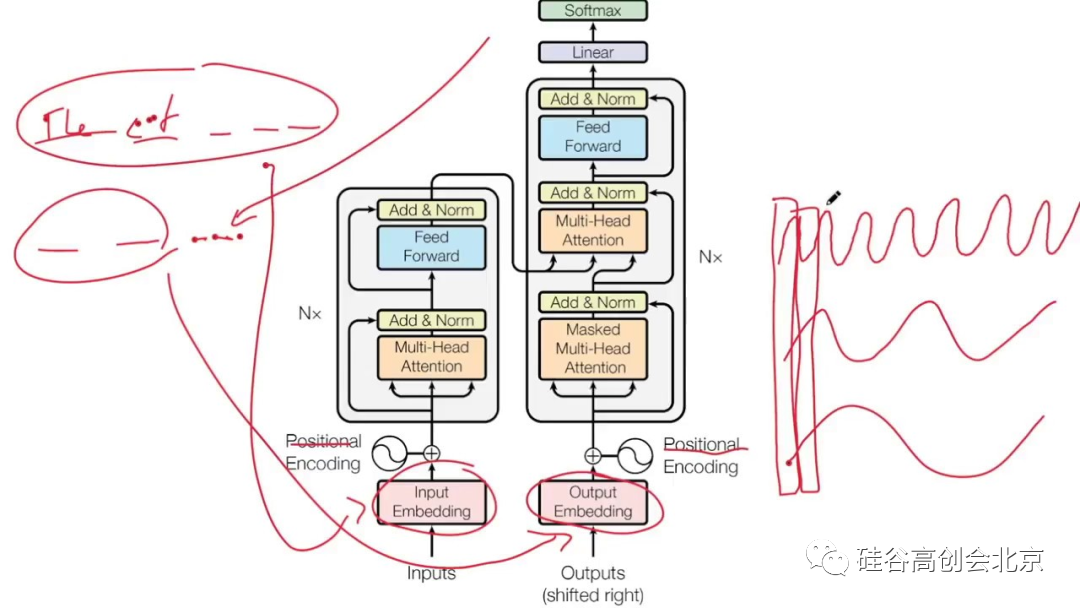
(论文链接:https://arxiv.org/abs/1706.03762)六年前,一篇名字有点浮夸的论文被上传到了预印版论文平台 arXiv 上,「xx is All You Need」这句话被 AI 领域的开发者们不断复述,甚至已经成了论文标题的潮流,而 Transformer 也不再是变形金刚的意思,它现在代表着 AI 领域最先进的技术。
六年后,回看当年的这篇论文,我们可以发现很多有趣或鲜为人知的地方,正如英伟达 AI 科学家 Jim Fan 所总结的那样。
一、「注意力机制」并不是 Transformer 作者所提出的Transformer 模型抛弃了传统的 CNN 和 RNN 单元,整个网络结构完全是由注意力机制组成。
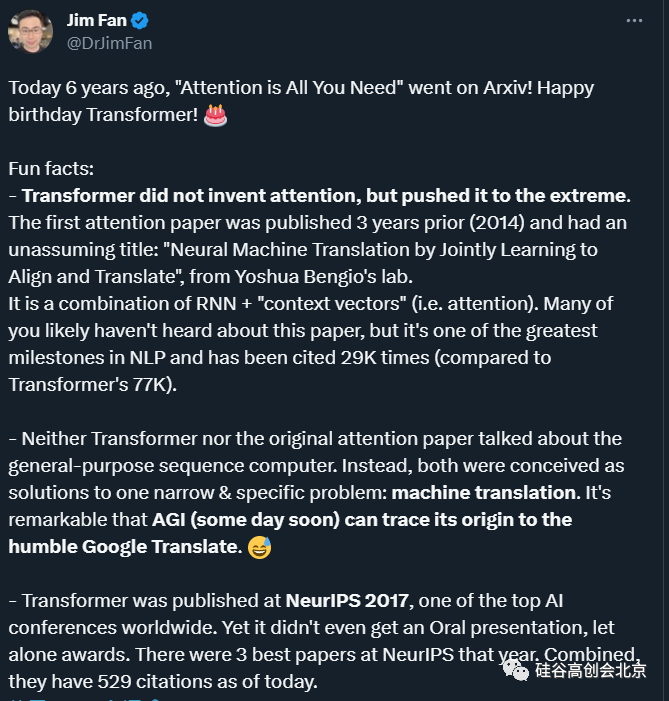
虽然 Transformer 论文的名字是《Attention is All You Need》,我们也因它而不断推崇注意力机制,但请注意一个有趣的事实:并不是 Transformer 的研究者发明了注意力,而是他们把这种机制推向了极致。
注意力机制(Attention Mechanism)是由深度学习先驱 Yoshua Bengio 带领的团队于 2014 年提出的:
《Neural Machine Translation by Jointly Learning to Align and Translate》,标题比较朴实。
在这篇 ICLR 2015 论文中,Bengio 等人提出了一种 RNN +「上下文向量」(即注意力)的组合。虽然它是 NLP 领域最伟大的里程碑之一,但相比 transformer,其知名度要低得多,Bengio 团队的论文至今已被引用 2.9 万次,Transformer 有 7.7 万次。
(图源网络)
AI 的注意力机制,自然是仿照人类的视觉注意力而来。人类大脑里有一种天生能力:当我们看一幅图时,先是快速扫过图片,然后锁定需要重点关注的目标区域。
如果不放过任何局部信息,必然会作很多无用功,不利于生存。同样地,在深度学习网络中引入类似的机制可以简化模型,加速计算。从本质上说,Attention 就是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。
近年来,注意力机制被广泛应用在深度学习的各个领域,如在计算机视觉方向用于捕捉图像上的感受野,或者 NLP 中用于定位关键 token 或者特征。大量实验证明,添加了注意力机制的模型在图像分类、分割、追踪、增强以及自然语言识别、理解、问答、翻译中任务中均取得了明显的性能提升。
引入了注意力机制的 Transformer 模型可以看做一种通用序列计算机(general-purpose sequence computer),注意力机制允许模型在处理输入序列时根据序列中不同位置的相关性分配不同的注意力权重,这使得 Transformer 能够捕捉到长距离的依赖关系和上下文信息,从而提高序列处理的效果。
但在当年,不论是 Transformer 还是最初的 attention 论文都没有谈到通用序列计算机。相反,作者们认为它是解决一个狭窄而具体的问题 —— 机器翻译的机制。所以未来的我们追溯起 AGI 的起源时,说不定可以追溯到「不起眼」的谷歌翻译。
二、虽然被 NeurIPS 2017 接收,但连个 Oral 都没拿到Transformer 这篇论文虽然现在影响力很大,但在当年的全球顶级 AI 会议 NeurIPS 2017 上,连个 Oral 都没拿到,更不用说拿到奖项了。当年大会共收到 3240 篇论文投稿,其中 678 篇被选为大会论文,Transformer 论文就是被接收的论文之一,在这些论文中,40 篇为 Oral 论文,112 篇为 Spotlight 论文,3 篇最佳论文,一篇 Test of time award 奖项,Transformer 无缘奖项。虽然无缘 NeurIPS 2017 论文奖项,但 Transformer 的影响力大家也是有目共睹的。Jim Fan 评价说:在一项有影响力的研究变得有影响力之前,人们很难意识到它的重要性,这不是评委的错。不过,也有论文足够幸运,能够第一时间被发现,比如何恺明等人提出的 ResNet,当年获得了 CVPR 2016 最佳论文,这一研究当之无愧,得到了 AI 顶会的正确认可。但在 2017 年那个当下,非常聪明的研究者也未必能够预测现在 LLM 带来的变革,就像 20 世纪 80 年代一样,很少有人能预见到 2012 年以来深度学习带来的海啸。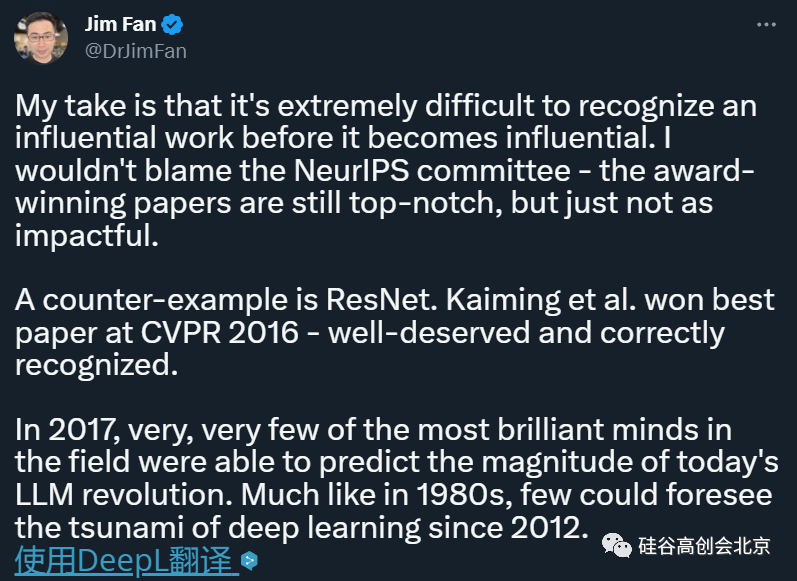
(图源网络)
当时这篇论文的作者共有 8 位,他们分别来自谷歌和多伦多大学,五年过去了,大部分论文作者都已离开了原机构。2022 年 4 月 26 日,一家名为「Adept」的公司官宣成立,共同创始人有 9 位,其中就包括 Transformer 论文作者中的两位 Ashish Vaswani 和 Niki Parmar。Ashish Vaswani 在南加州大学拿到博士学位,师从华人学者蒋伟(David Chiang)和黄亮(Liang Huang),主要研究现代深度学习在语言建模中的早期应用。2016 年,他加入了谷歌大脑并领导了 Transformer 的研究,2021 年离开谷歌。Niki Parmar 硕士毕业于南加州大学,2016 年加入谷歌。工作期间,她为谷歌搜索和广告研发了一些成功的问答和文本相似度模型。她领导了扩展 Transformer 模型的早期工作,将其扩展到了图像生成、计算机视觉等领域。2021 年,她也离开谷歌。在离开之后,两人参与创立了 Adept,并分别担任首席科学家(Ashish Vaswani)和首席技术官(Niki Parmar)。Adept 的愿景是创建一个被称为「人工智能队友」的 AI,该 AI 经过训练,可以使用各种不同的软件工具和 API。2023 年 3 月,Adept 宣布完成 3.5 亿美元的 B 轮融资,公司估值超过 10 亿美元,晋升独角兽。不过,在 Adept 公开融资的时候,Niki Parmar 和 Ashish Vaswani 已经离开了 Adept,并创立了自己的 AI 新公司。不过,这家新公司目前还处于保密阶段,我们无法获取该公司的详细信息。另一位论文作者 Noam Shazeer 是谷歌最重要的早期员工之一。他在 2000 年底加入谷歌,直到 2021 年最终离职,之后成为了一家初创企业的 CEO,名字叫做「Character.AI」。Character.AI 创始人除了 Noam Shazeer,还有一位是 Daniel De Freitas,他们都来自谷歌的 LaMDA 团队。此前,他们在谷歌构建了支持对话程序的语言模型 LaMDA。今年三月,Character.AI 宣布完成 1.5 亿美元融资,估值达到 10 亿美元,是为数不多有潜力与 ChatGPT 所属机构 OpenAI 竞争的初创公司之一,也是罕见的仅用 16 个月时间就成长为独角兽的公司。其应用程序 Character.AI 是一个神经语言模型聊天机器人,可以生成类似人类的文本响应并参与上下文对话。Character.AI 于 2023 年 5 月 23 日在 Apple App Store 和 Google Play Store 发布,第一周下载量超过 170 万次。2023 年 5 月,该服务增加了每月 9.99 美元的付费订阅,称为 c.ai+,该订阅允许用户优先聊天访问,获得更快的响应时间和早期访问新功能等特权。Aidan N. Gomez 早在 2019 年就已离开谷歌,之后担任 FOR.ai 研究员,现在是 Cohere 的联合创始人兼 CEO。Cohere 是一家生成式 AI 初创公司,于 2019 年成立,其核心业务包括提供 NLP 模型,并帮助企业改进人机交互。三位创始人分别为 Ivan Zhang、Nick Frosst 和 Aidan Gomez,其中 Gomez 和 Frosst 是谷歌大脑团队的前成员。2021 年 11 月,Google Cloud 宣布他们将与 Cohere 合作,Google Cloud 将使用其强大的基础设施为 Cohere 平台提供动力,而 Cohere 将使用 Cloud 的 TPU 来开发和部署其产品。值得注意的是,Cohere 刚刚获得 2.7 亿美元 C 轮融资,成为市值 22 亿美元的独角兽。Łukasz Kaiser在 2021 年离开谷歌,在谷歌工作了 7 年零 9 个月,现在是 OpenAI 一名研究员。在谷歌担任研究科学家期间,他参与了机器翻译、解析及其他算法和生成任务的 SOTA 神经模型设计,是 TensorFlow 系统、Tensor2Tensor 库的共同作者。Jakob Uszkoreit 于 2021 年离开谷歌,在谷歌工作时间长达 13 年,之后加入 Inceptive,成为联合创始人。Inceptive 是一家 AI 制药公司,致力于运用深度学习去设计 RNA 药物。在谷歌工作期间,Jakob Uszkoreit 参与了组建谷歌助理的语言理解团队,早期还曾从事过谷歌翻译的工作。Illia Polosukhin 于 2017 年离开谷歌,现在是 NEAR.AI(一家区块链底层技术公司)的联合创始人兼 CTO。唯一还留在谷歌的是 Llion Jones,今年是他在谷歌工作的第 9 年。如今,距离《 Attention Is All You Need 》论文发表已经过去 6 年了,原创作者们有的选择离开,有的选择继续留在谷歌,不管怎样,Transformer 的影响力还在继续。欢迎添加小编微信,链接一线创业者、投资人,进入全球高端科技创投交流群!工业和信息化部工业文化发展中心主办,北京高创汇智科技有限公司承办,北京大兴国际机场临空经济区管理委员会联合承办,北京大兴区投资促进服务中心支持,共同开展的“专精特新”企业创新特训营第一期在北京大兴成功举办!
欢迎各位朋友扫码添加工作人员微信(备注专精特新合作/报名),报名下一期“专精特新”企业创新特训营或成为城市事业合伙人。