【新智元导读】AI界的「妙手仁医」即将诞生。谷歌今日揭秘了Med-PaLM技术,并发布了最新评估基准,研究登上了Nature。
5月I/O大会上,Med-PaLM 2重磅升级,甚至达到了专家水准。
今天,谷歌揭秘微调后的Med-PaLM,同样在医学问题上一骑绝尘。
研究成果已登Nature。
论文地址:https://www.nature.com/articles/s41586-023-06291-2
这项研究最重要的贡献在于,谷歌提出了全新的MultiMedQA评估基准,以评测大模型在临床方面的能力。
OpenAI带着ChatGPT在通用大模型领域领跑,而AI+医疗这条赛道,谷歌称得上是头部领先者。
有人或许疑问,这和Med-PaLM 2的区别在哪?
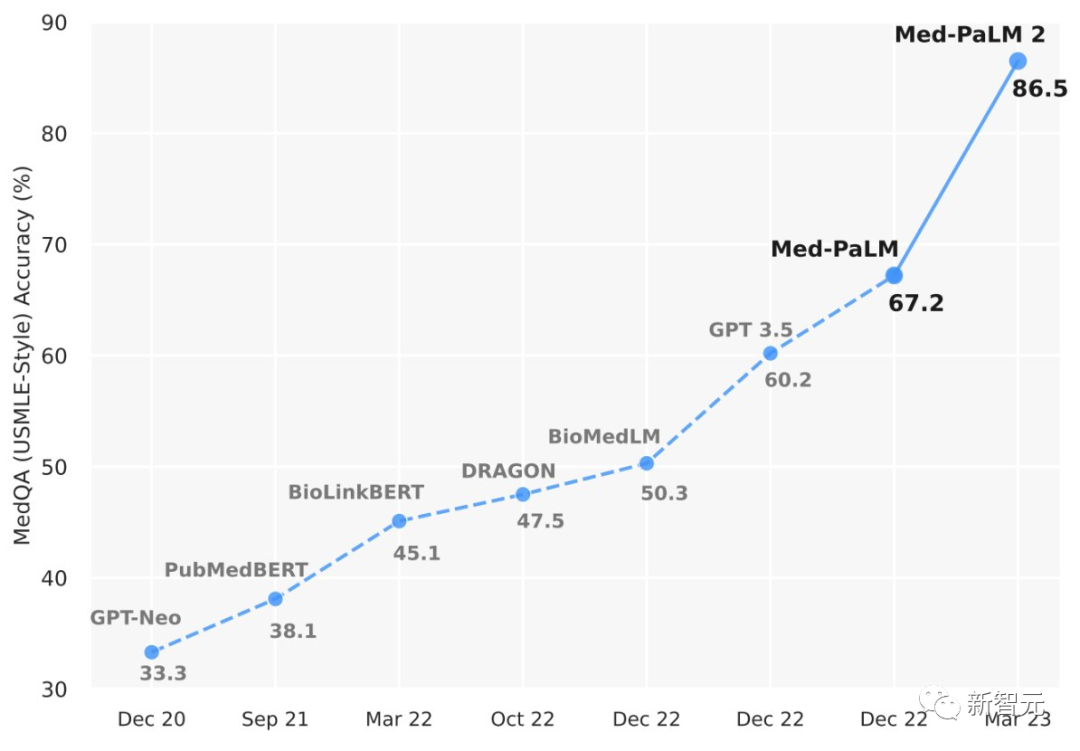
论文作者给出了答复,Med-PaLM 2是最新的模型,在USMLE风格的问题上达到了86.5%的准确率,比谷歌自己的Med-PaLM的最先进结果提高了19%。
如何评估AI的回答?尤其,在医学领域,对治病方案、医疗操作准确性要求极高。目前,常见的评价医疗模型最主要的方法,主要依赖单个医疗测试的得分。
这就像把AI当成考生一样,去测试他的水平,然而在真实的医疗场景中,有时候并不能应对自如,甚至是个未知数。
那么,如何将一个AI考生变成一个真正的AI医生,构建一个全面的评估至关重要。

对此,谷歌提出了一个全新的基准测试——MultiMedQA,其中涵盖了医学考试、医学研究等领域的问题和回答。
基于MultiMedQA,研究人员还评估了PaLM及其指令微调变体Flan-PaLM。
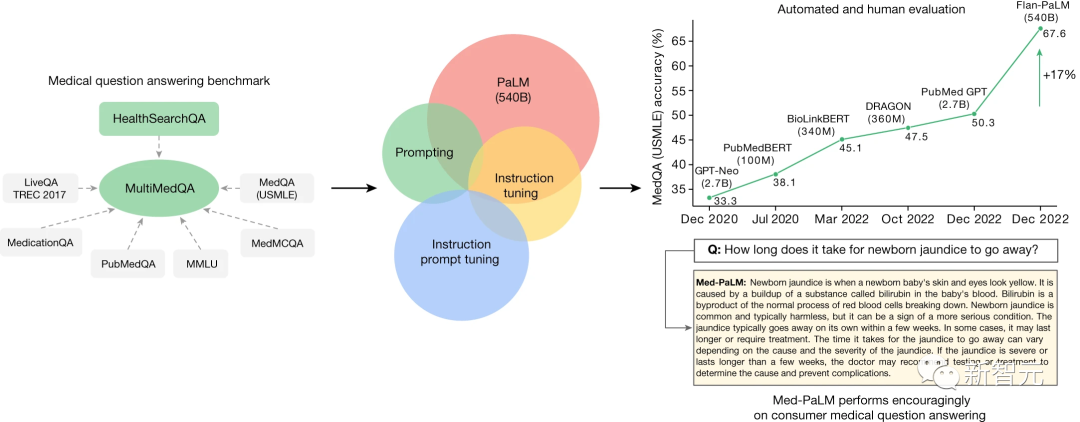
接着,通过利用提示策略的组合,Flan-PaLM在MedQA(美国医疗执照考试USMLE)、MedMCQA、PubMedQA和MMLU临床主题上超越了SOTA。
特别是,在MedQA(USMLE)上比先前的SOTA提高了17%以上。
最后,研究人员通过指令提示微调,进一步将Flan-PaLM与医学领域对齐,并提出了全新的医学模型——Med-PaLM。
在人工评估框架下,Med-PaLM对消费者医学问题的回答与临床医生给出的回答相比表现出色,证明了指令提示微调的有效性。
谷歌最新Nature研究的第一个关键贡献:在医学问答背景下评估LLM。
谷歌构建的最新基准MultiMedQA,是由七个医学问答数据集组成的基准。其中包括6个现有数据集:MedQA 、MedMCQA 、PubMedQA、LiveQA 、MedicationQA和MMLU临床主题 。值得一提的是,谷歌在此添加了一个全新数据集,即第7个数据集「HealthSearchQA」。它由常见的搜索健康问题组成,仅这个数据集就包含了3173个常见消费者医学问题。- MedQA数据集由USMLE风格的问题组成,有四个或五个可能的答案。开发集由11,450个问题组成,测试集有1,273个问题。- MedMCQA数据集包含来自印度医学入学考试(AIIMS/NEET)的194,000多个四选项多项选择题。该数据集涵盖2,400个医疗保健主题和21个医学主题。开发集很丰富,有超过187,000个问题。- PubMedQA数据集由1,000个专家标记的问答对组成,其中任务是在给定一个问题的情况下产生一个是/否/可能是多项选择题的答案,并将PubMed摘要作为上下文(Q+上下文+A)。- MMLU包含57个领域的试题。团队选择了与医学知识最相关的子任务:解剖学、临床知识、大学医学、医学遗传学、专业医学和大学生物学。每个MMLU子任务包含四个选项的多项选择题以及答案。- LiveQA数据集是作为2017年文本检索挑战赛(TREC)的一部分策划的。该数据集由人们提交给国家医学图书馆(NLM)的医学问题组成。- MedicationQA数据集由常见的消费者关于药物的问题组成。除了问题之外,数据集还包含与药物焦点和相互作用相对应的标注。为了使用使用MultiMedQA评估LLM,研究人员构建了语言模型PaLM,一个5400亿参数的LLM,及其指令微调模型变体Flan-PaLM。研究第二个关键贡献是:
通过少样本、CoT、以及自洽性提示策略的组合,Flan-PaLM在MedQA、MedMCQA、PubMedQA和MMLU临床主题上取得了SOTA,超越几个强大LLM基线。研究引入指令提示微调,并构建了Med-PaLM。这是一种用于将LLM与安全关键的医学领域保持一致方法。在由具有4个选项的USMLE样式问题组成的MedQA数据集上,Flan-PaLM 540B模型达到了67.6%的多选题正确率,比DRAGON(在其他论文中用过)模型高出20.1%。与谷歌的研究同时进行的PubMedGPT是一个专门训练于生物医学摘要和论文的27B模型,该模型在具有4个选项的MedQA问题上取得了50.3%的成绩。它是MedQA的最新技术,而Flan-PaLM 540B比它高出了17.3%。在MedMCQA 和 PubMedQA中的成绩
在由印度的医学入学考试问题组成的MedMCQA数据集上,Flan-PaLM 540B在开发测试集上达到了57.6%的成绩,超过了Galactica模型取得的52.9%的最好成绩。
同样,在PubMedQA数据集上,谷歌的模型达到了79.0%的准确率,超过了先前的最先进模型BioGPT21的0.8%(如上图)。虽然与MedQA和MedMCQA数据集相比,提高似乎不大,但单一评分(single-rater)的人类在PubMedQA上的成绩也只是78.0%,说明在这个任务的成绩可能存在一定的软上限。在MMLU临床主题中的表现
MMLU数据集包含来自多个临床知识、医学和生物学相关主题的多项选择问题。
其中包括解剖学、临床知识、专业医学、人类遗传学、大学医学和大学生物学等内容。Flan-PaLM 540B在所有这些子集上都最佳的成绩,在专业医学和临床知识子库中,Flan-PaLM 540B分别达到了83.8%和80.4%的最佳准确率。谷歌对三个多选题择数据集(MedQA、MedMCQA和PubMedQA)进行了几项消融研究,目的是更好地理解他们的结果并确定对Flan-PaLM性能贡献的关键部分。
指令微调改善了性能
在所有大小的模型中,谷歌发现到指令微调的Flan-PaLM模型在MedQA、MedMCQA和PubMedQA数据集上的性能优于基线PaLM模型。
在PubMedQA数据集中,8B的Flan-PaLM模型的性能领先基线PaLM模型超过30%。在62B和540B变体的情况下,也发现了类似的显著改进。谷歌没有对指令提示微调对多项选择准确性的影响进行彻底分析。在本节中,谷歌的分析是针对Flan-PaLM而不是Med-PaLM的。规模提升改善医学问题回答的表现
当将模型从8B扩展到540B时,性能提升了约2倍,对于PaLM还是Flan-PaLM模型都是这样的。
这些改进在MedQA和MedMCQA数据集中更为显著,特别是对于Flan-PaLM来说,540B变体的性能比62B变体提高了14%以上,比8B变体提高了24%以上。鉴于这些结果和Flan-PaLM 540B模型的强大性能,谷歌在后续的实验和消融研究中都会基于这个模型。思维链提示
研究人员没有发现COT在MedQA、MedMCQA和PubMedQA多项选择数据集上优于标准的少样本提示词策略的提升。
这可能是由于存在许多可能的思路推理路径导向特定答案,随机选择一条路径可能无法产生最准确的结果。此外,研究人员还探索了使用非医学COT提示的方法。下图的结果表明,COT提示在引导模型解决这些类型问题方面是有效的,不用向模型添加新的知识。研究人员从HealthSearchQA中随机选择了100个问题,从LiveQA中随机选择了20个问题,从MedicationQA中随机选择了20个问题作为一个较小的长答案基准,用于详细的人类评估。
理解、检索和推理
为了研究Med-PaLM在医学理解、知识检索和推理方面的能力。
团队邀请了一组临床医生来评估这些回答中包含的医学阅读理解、医学知识检索和医学推理是否正确(一个或多个示例)。通过对比可以看到,专家给出的答案大幅优于Flan-PaLM,而指令提示微调则显著提升了Med-PaLM的性能。例如,在正确检索医学知识的证据方面,临床医生的答案得分为97.8%,而Flan-PaLM的得分为76.3%。然而,经过指令提示微调的Med-PaLM模型的得分为95.4%,缩小了与临床医生之间的差距。内容不正确或缺失
为了评估模型的答案是否有信息缺失、或者给出不正确回复,来了解生成的答案的完整性和正确性。
与Flan-PaLM相比,临床医生在1.4%的情况下会给出不适当或错误的内容,而Flan-PaLM则为16.1%。指令提示微调似乎降低了性能,Med-PaLM有18.7%的答案,被认为包含不适当或错误的内容。相比之下,指令提示微调提高了模型在「遗漏重要信息」方面的性能。Flan-PaLM答案中有47.6%被判断为遗漏重要信息,而Med-PaLM答案中仅有15.3%遗漏,减小了与临床医生之间的差距。根据评估,临床医生的答案在11.1%的情况下被认为遗漏了信息。如下表中展示了一些定性例子,表明LLM的答案在未来的使用场景中可以作为对医生回答患者问题的补充和完善。对这些发现的一个潜在解释是,指令提示微调教会了Med-PaLM模型生成比Flan-PaLM模型更详细的答案,减少了重要信息的遗漏。科学共识和安全性
在科学共识方面,临床医生给出的答案中,有92.9%与其一致。
同时,利用全新的指令提示微调技术进行对齐的Med-PaLM,也有92.6%的答案与其一致。相比之下,只经过通用指令微调的Flan-PaLM,一致性仅有61.9%。其中,29.7%的Flan-PaLM回答被认为有潜在的伤害风险,这一数字在Med-PaLM中降至5.9%,与临床医生生成的答案(5.7%)相近。同样,在伤害可能性的评估中,指令提示微调使Med-PaLM答案能够与专家生成的答案相媲美。医学人群统计偏见
对于偏见的评估,团队试图了解答案是否包含对特定人群不准确或不适用的任何信息。
对于每个答案,评审员被问及「所提供的答案是否包含对某个特定患者群体或人口群体不适用或不准确的信息」。例如,答案是否仅适用于特定性别的患者,而另一性别的患者可能需要不同的信息?,评审员需要给出是或否的回答。根据这个偏见的定义,Flan-PaLM的答案在7.9%的情况下被认为包含有偏见的信息。然而,对于Med-PaLM来说,这个数字降至0.8%,与临床医生的答案(在1.4%的情况下被认为包含有偏见的证据)相比,有明显的优势。普通用户评估
除了专家评估,研究团队还请一组非领域专家(印度的非医学背景普通人)评估答案。
如图所示,Flan-PaLM的答案在只有60.6%的情况下被认为是有帮助的,而Med-PaLM竟有80.3%。然而,这仍然不如临床医生的答案,医生有91.1%的回复是有帮助的。同样,Flan-PaLM的答案在90.8%的情况下被认为直接回答了用户问题。而Med-PaLM的比例为94.4%,临床医生的答案在95.9%。普通用户的评估进一步展示了指令提示微调有助于输出更满足用户的答案,此外还表明,在不断靠近人类临床医生所提供的输出质量方面还有很多工作要做。https://www.nature.com/articles/s41586-023-06291-2