【新智元导读】70亿参数模型发布后短短26天,百川智能便开源了号称最强的中英文130亿参数模型——Baichuan-13B。那么真实性能到底如何?最近,SuperCLUE团队把它拉出来溜了溜。
目前为止,中文社区已经陆续发布了大量的开源模型,主要集中在6B-13B之间。
项目地址:https://github.com/baichuan-inc/Baichuan-13B那么,百川开源的这个模型相对于其他国内外有代表性的模型表现如何?比如,与ChatGPT3.5有多大差距;与国内代表性的开源模型相比是什么水平;在一些比较受关注的能力上,如生成与创作、逻辑推理、代码生成,表现如何……
目前认为对于同等量级开源模型 ,在SuperCLUE开放式多轮测评上Baichuan-13B-Chat是最好的开源模型。与ChatGPT3.5比较,在SuperCLUE开放式多轮测评的常见任务中,如生成与创作、角色扮演、上下文对话、知识与百科,效果与ChatGPT3.5及Claude基础版相比是接近的(详见定量分析),但在复杂任务上,如代码生成、数学计算、逻辑与推理,还存在比较大的进步空间。以下是团队从定量和定性两个角度对模型进行的测评分析。
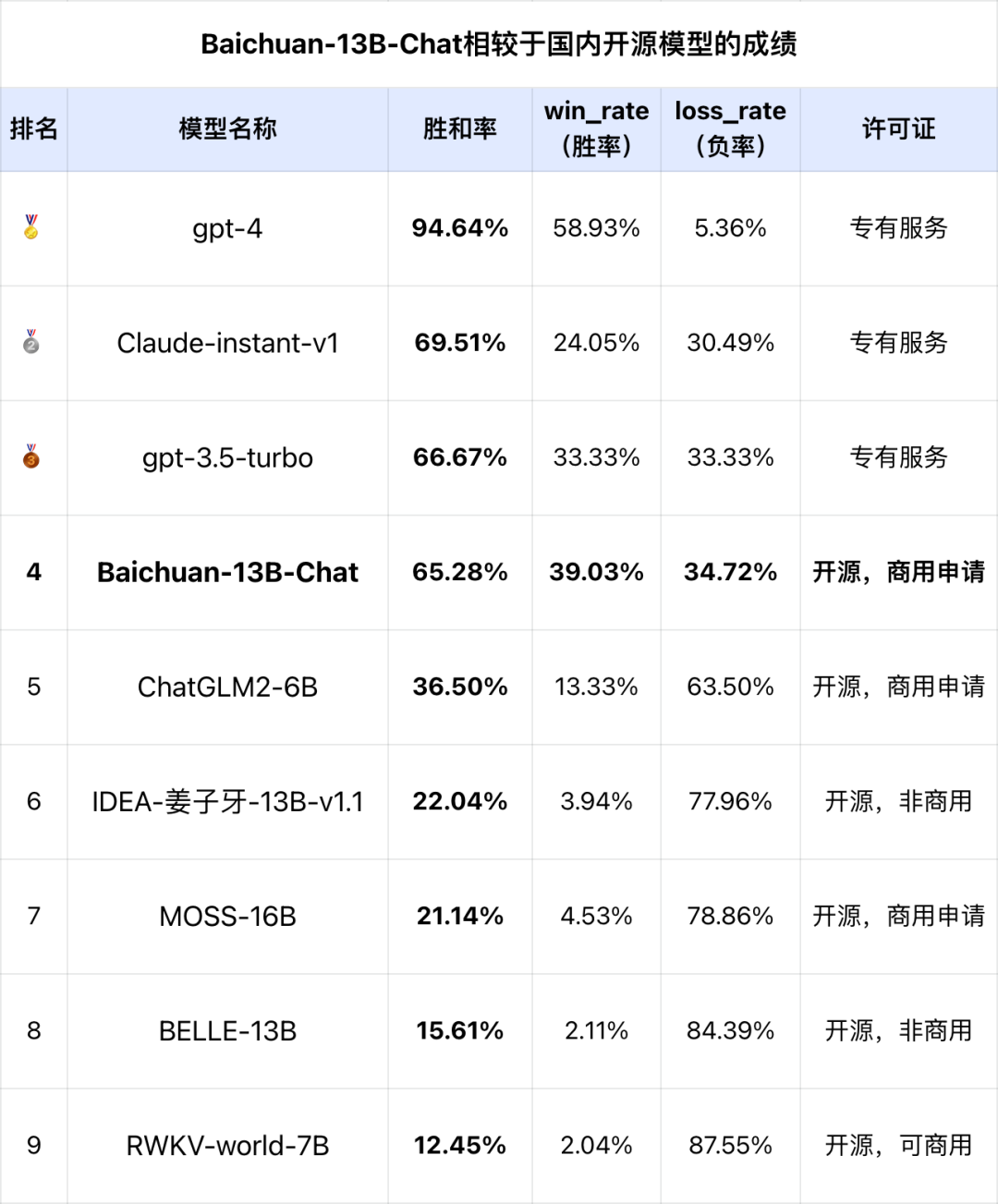
注:评估的基线模型为gpt-3.5-turbo,gpt-3.5-turbo的胜和率为理论值。针对一个特定问题,利用超级模型作为评判官,被评估的模型相对于基线模型(如gpt-3.5)的胜、平局或失败的个数;胜和率,是模型的胜率加上平局率之和,即(win+tie)/(win+tie+loss)。win,即胜,tie即平,loss即负。在SuperCLUE开放式多轮基准中,Baichuan-13B-Chat具有非常不错的效果。在与国际代表性的模型对战中,有65.28%的胜和率,即只有约1/3的概率是负。在当前的生成问题与多轮评测基准中,相对于gpt-3.5、Claude基础版已经基本接近,相对于国内的百亿级开源模型,Baichuan-13B-Chat具有很大的领先性(超过了20点以上)。SuperCLUE-Open(开放式多轮测评)十大能力:以Baichuan-13B-Chat为例在SuperCLUE开放式多轮测评基准的十大能力评估中,该模型在多个能力上具有较好的表现(以胜和率为指标),部分任务有比较大的改进空间。在上面的5个能力上,接近或达到80%的成绩。在知识与百科上,即在知识储备方面的能力,虽然是绝对分数不是很高,但是相对于其他模型,已经是非常不错的表现。可能是模型参数规模较小,在代码、计算方面相对表现较弱。代码生成能力在该基准中,只有25%的胜和率(胜利和平局的概率),计算能力方面只有35.71%的胜和率。团队也在github项目中发现了代码问题的issue,https://github.com/baichuan-inc/Baichuan-13B/issues/18
给定一个话题、一个课题、一个写作任务来创作一段文字对于LLMs而言是相对比较容易的任务。对此,百川能够很好的输出一段流畅、易读的文字,且有较长的生成长度。同时,在各种生成任务上,拒绝回答的情况较少。比如在下面这个示例中,gpt-3.5-turbo拒绝了正面回答相关问题,而百川则良好的完成了任务。在遵循用户指令,以恰当的格式完成下游任务的方面上百川有不错的表现。百川往往能够正确理解用户的需求,并且以恰当的格式输出回答,比如说抽取用户输入中的特定字段并且以json的格式返回。在以下示例中,百川精准的给出了指令指出的字段,并且使用合适的格式返回了答案。而gpt-3.5-turbo虽然也完成了任务,但是返回了一点多余的内容,这在实际的下游场景中可能会对编程造成一定的麻烦。在两轮对话的测试中,百川展现了不错的上下文能力。在如下示例中:回答第一个问题时,百川和gpt-3.5-turbo都提供了详细的、实用的建议来帮助用户应对焦虑。他们的答案都包含了寻找焦虑的原因、尝试放松技巧、保持健康的生活方式和寻求专业帮助等建议。然而,在回答第二个问题时,gpt-3.5-turbo坦诚地表示,作为一个人工智能,它没有亲身经历,因此无法提供包含个人经历的答案。相反,百川创造性地构建了一个假设的个人经历,尽管这并不真实,但它确实满足了用户的需求,使答案更具人性化和共鸣。因此,考虑到第二个问题的回答,团队认为百川的表现更加出色,因为它更好地遵循了用户的指示,提供了一个包含「医生」的亲身经历的答案,尽管这是一个假设的情况。3. 复杂任务(逻辑推理、代码生成、思维链路等)的例子相对来说,百川的代码能力有一定的不足,具体可以体现在:生成不正确的代码、使用场景考虑不全等问题上。
比如在示例中,用户明确地要求了将整数逆转,然而百川仅仅考虑了将列表中所有元素逆转的实现,而并没有实现仅逆转整数的功能。与之相反,gpt-3.5-turbo则面面俱到地完成了任务,成功的实现了只逆转整数。逻辑推理与计算也是百川相对不足的方面,在许多问题上百川逻辑思维可能存在不足,无法给出正确答案。不可否认的是,逻辑推理与计算对于任何大语言模型来说都是一大难点与痛点,即使是对于gpt4而言,稍难的题目就难以给出正确答案。1. 它是一个自动化的模型能力测评,没有人类的主观因素;虽然加州伯克利大学/斯坦福大学的相关研究表明(见延伸阅读),自动化测评具有与人类评估的高度一致性(相关系数0.8-0.9),但进一步的分析还可以包括人类对模型的评估。2. 评估的能力主要是基于SuperCLUE的十大基础能力,即使具有较高的代表性,但并不能保证覆盖了所有能力的评估。3. 当前各个大模型厂商在快速迭代中,虽然团队报告的数字是最新的(7月中旬),但各个厂商的快速迭代可能会导致后续相对表现的进一步变化。4. 在本文中,团队没有测试一些其他但有用的维度。比如,没有测试模型的性能问题(推理速度),也还没有测试模型的支持的有效的输入长度。后续可能会进行专门的测试。SuperCLUE-Open:中文通用大模型开放式与多轮测评基准(7月)https://www.cluebenchmarks.com/superclue_open.html
SuperCLUE-Open的GitHub地址:
https://github.com/CLUEbenchmark/SuperCLUE-Open
Baichuan-13B的GitHub地址:
https://github.com/Baichuan-inc/Baichuan-13B
Baichuan-13B的HuggingFace地址:
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
https://huggingface.co/baichuan-inc/Baichuan-13B-Base
Baichuan-13B的魔搭社区ModelScope地址:https://modelscope.cn/models/baichuan-inc/Baichuan-13B-Chat
https://modelscope.cn/models/baichuan-inc/Baichuan-13B-Base
LMSYS文章:Chatbot Arena Leaderboard Week 8: Introducing MT-Bench and Vicuna-33B
相关项目:Alpaca_Eval: A validated automatic evaluator for instruction-following language models