编者按:英特尔是半导体行业和计算创新领域的全球领先厂商。与合作伙伴一起,英特尔推动了人工智能、5G、智能边缘等转折性技术的创新和应用突破,驱动智能互联世界。不久前,英特尔正式发布了第四代英特尔®至强®可扩展处理器,旨在为增长最快的工作负载提升性能。那么,第四代至强®到底强在哪里?LiveVideoStackCon 2023上海站邀请到英特尔至强产品线软件架构师谢义为我们介绍:当面对算力瓶颈时,英特尔是如何利用CPU解决全链路智能编码的。

最近一年,关于AI和AIGC的讨论远比以往更加火热。大模型、多模态、AIGC工具……很多专家认为,AIGC一定会对整个编解码行业产生巨大的革新。本文会着重介绍目前用到的一些处理,例如降噪、超分和内容识别等。虽然技术角度看GPU是第一选择,但缺卡在业内已经是一个公开的秘密。即便不缺卡,一次性购入大量GPU卡,也有非常大的风险。但由于现今大模型接棒,毫无疑问CPU仍是市场内的第一选择。图中是一个视频转码推流的一般性流程图。主播将视频上传到上行CDN,然后再由视频处理中心进行各种前处理,包括内容理解,审核,编辑,增强和超分,然后进行编码,再推送到下行CDN,供观众观看。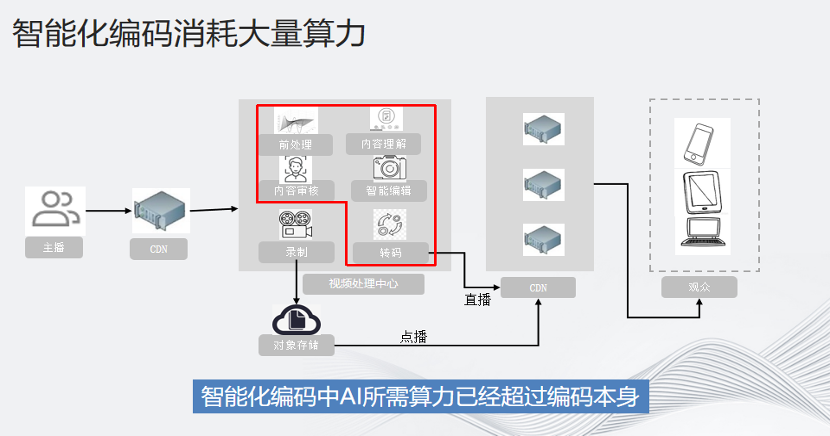
红色框部分都是和AI相关的部分。智能化编码中,AI所需算力已经超过编码本身。1080p的数据超成4K,编码只需要20几个物理核,但是如果要超分,就需要一张GPU卡。一张GPU卡5000块一个月,对比下来成本优势一目了然。根据相关视频企业公开的财报,视频转码和带宽的成本占到公司全年收入的10%左右。随着AIGC的发展,未来肯定不局限于10%,因此成本问题是我们的痛点之一。
CPU全链路智能化编码的优势就在于成本节约,运维简单。下面举一个更具体的例子:我们都知道转码方式有很多种,但CPU有两个不可替代的优势:1.高灵活性;2.高复用性。CPU的升级几乎没有成本,只需升级一下软件部分即可,以云为基础,申请一个虚拟主机,无论是docker还是container都可以随用随放,十分自由灵活,成本很低。由于超分部分对算力的要求非常高,需要通过GPU来辅助,但同时也会引发一些问题:客户将高要求的AI负载迁移到GPU上,将编码和前处理完全分离。这就像在一间屋子里解码——发送到另一间屋子进行前处理——再转回来编码。这不仅让流程变得冗长,也对运维造成了极大负担,数据的反复调度也造成了一定时延的增加。英特尔®第四代至强®可扩展处理器及AMX赋能智能化编码
接下来会介绍英特尔®第四代至强®可扩展处理器及其内置的AI加速器AMX,以及如何利用AMX和英特尔成熟的软件栈和工具链帮助视频编解码工作者,打造全链路智能化编码。据最新的统计数据,英特尔®至强®服务器在中国市场的数据中心的占有率保持在80%以上,可以说至强®服务器是数据中心的基石。第四代至强®一个重要的革新就是内置了数个硬件加速器,用于不同应用场景的性能加速,例如之前需要外置的PCIE插卡就已经内置在CPU内部。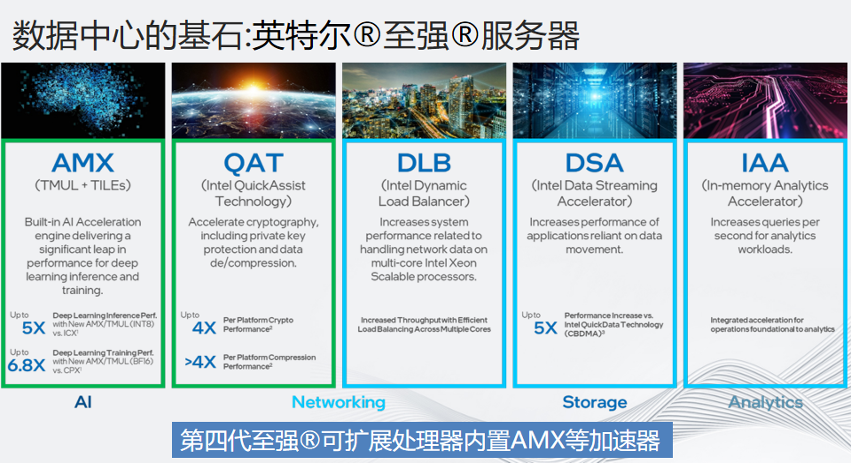
从左往右第一个AMX适用于AI;QAT负责压缩、解压和加解密;DLB负责Load Balance,CDN负责负载均衡,自动dispatch到闲散的资源上;DSA负责内存拷贝,不需要CPU参与,异步拷贝不仅速度快,而且不占用CPU内存;IAA负责存内分析,更多和数据库相关,IAA可以在不解压数据的情况下分析数据。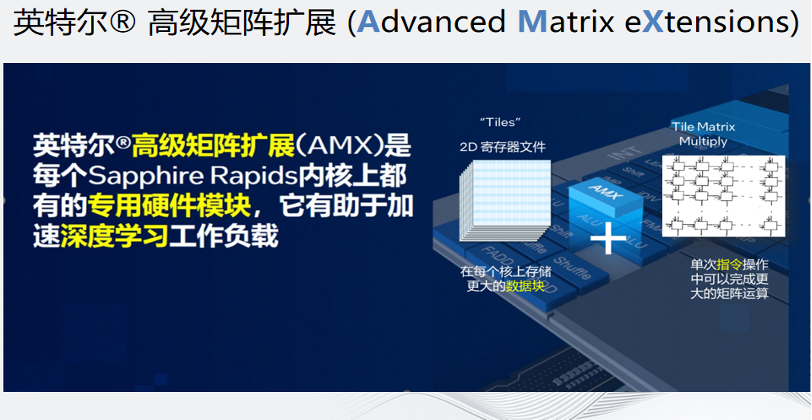
AMX的全称是Advanced Matrix eXensions,高级矩阵扩展指令集。它在AVX512的基础之上做了进一步的扩展。AMX有两个核心思想,一个是Tiles,一个是Timo。Tiles是物理上两地寄存器的叠加,16个AVX512叠加在一块。Timo是针对两地Tiles的矩阵运算。最新的至强®每一颗物力核上都有一个内置的AMX,充当AI 的加速卡。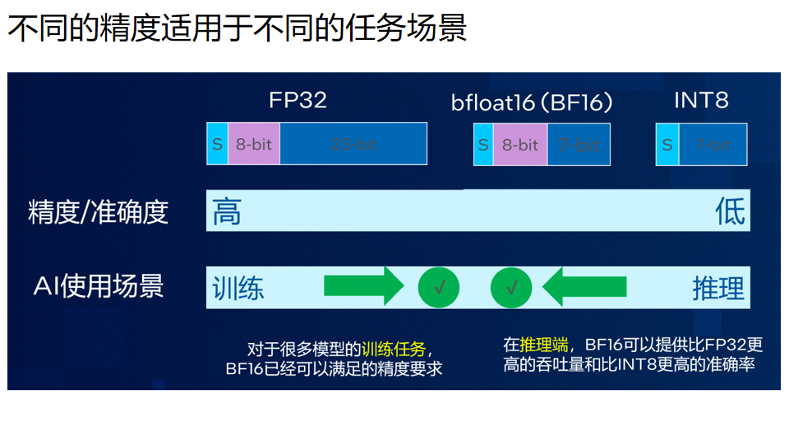
和大多数加速卡一样,AMX加速的是量化精度。目前第四代至强®支持的是BF16和INT8,未来也会很快支持FP8和FP16。BF16的表达范围和FP32一模一样,只是精度比FP32小一点。目前绝大多数的场景,BF16已经足够。对于训练来说FP16足矣,而推理则只需要INT8。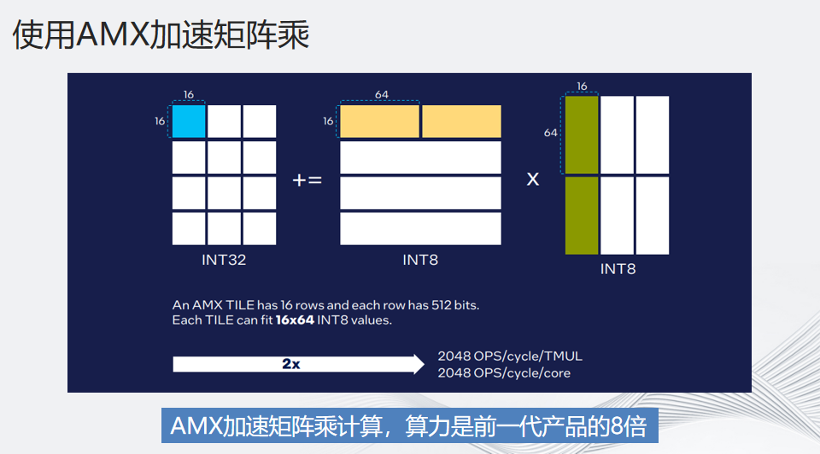
AMX是如何加速矩阵乘的呢?我们在做大的矩阵时可以把矩阵拆成16*64,然后一次性计算。如果算力不够,可以用oneDNN和MLKDNN处理,而AMX加速矩阵乘计算,算力是前一代产品的8倍。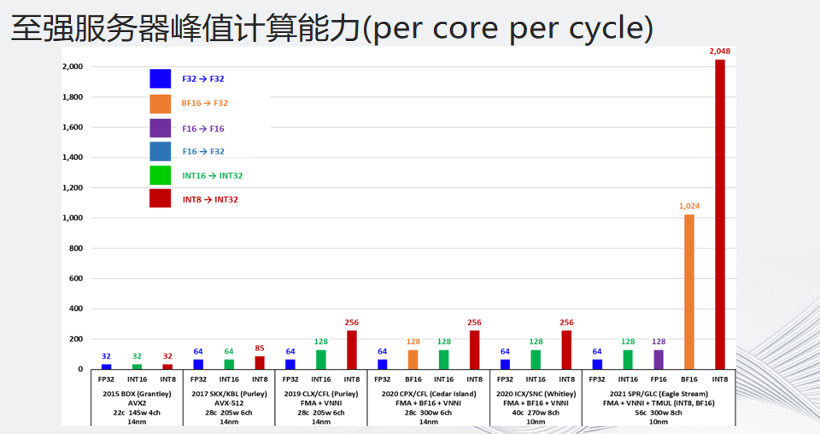
这张图是至强®服务器峰值计算能力的演进过程。从2019年开始的第二代至强®可扩展处理器支持VNNI,最新发布的第四代至强®可扩展处理器支持AMX,可以看到每个指令周期的计算能力得到8倍的提升。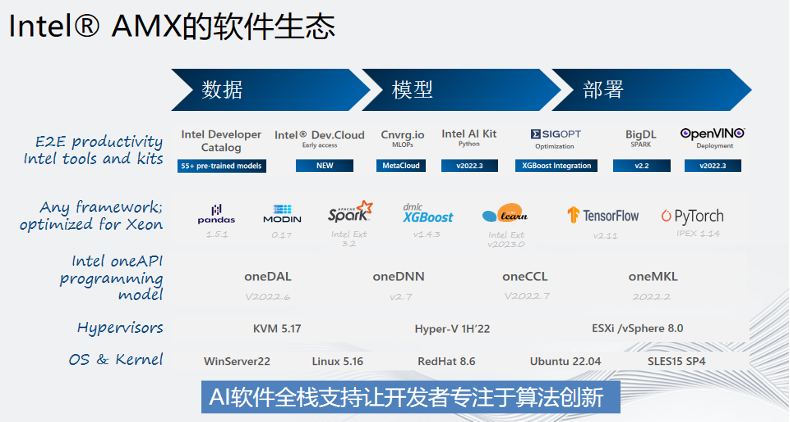
硬件性能只是一方面,软件生态某种意义上说对开发者来说更为关键。这是一张英特尔® AMX的软件生态图,从下往上,从最底层的操作系统到虚拟化KVM、HyperV,再到核心AI计算库都是英特尔开发的。在框架层面,主流的TF和PyTorch也都包含在内,除此之外英特尔还提供了丰富的推理工具。这些成熟的软件生态使得我们的开发者可以专注于算法创新,而不用考虑如何部署等细节,开箱即用。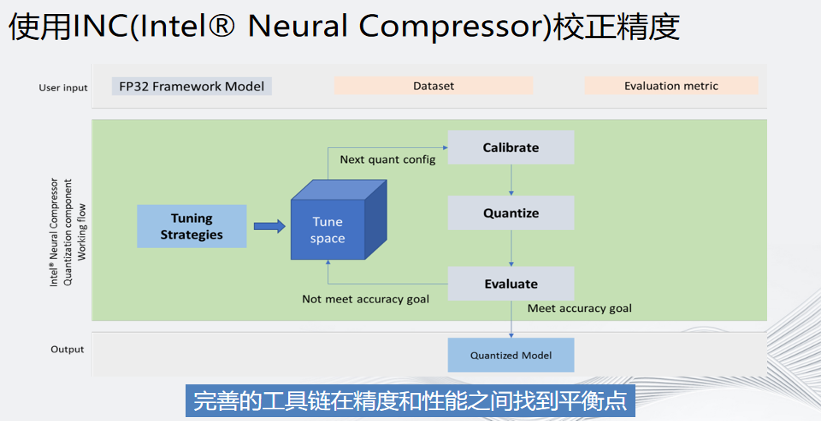
BF16和INT8的高算力对将AI从GPU迁到CPU之上确实有很大的帮助,但如何保证精度呢?英特尔有一个工具叫做INC,内置了很多专门用于精度的校正算法。作为开发者,只需要做三件事:输入模型、输入数据集和输入精度要求即可。INC会根据客户的输入进行tuning,直到有一个用户满意的算法。如果最终达不到设定的精度要求,还可以对某些层进行回滚,从而保证设定的精度可以达到要求。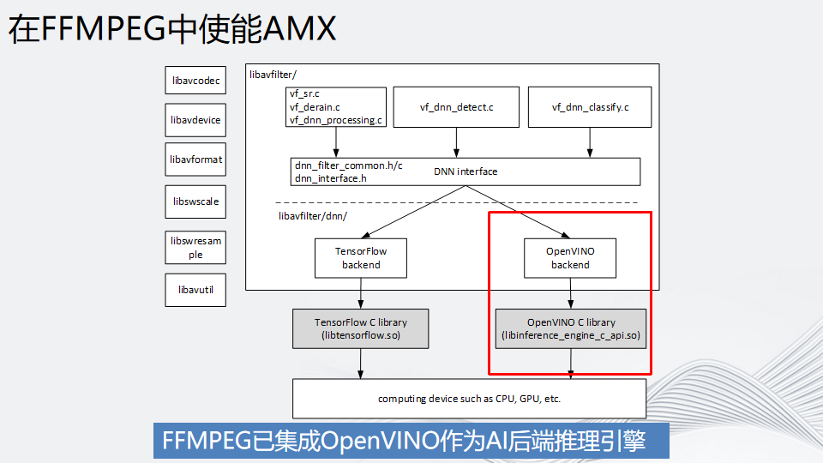
回到视频编解码领域,我们知道视频前处理是在FFmpeg解码之后,对YUV或者RGB数据进行处理,处理结束后再送到编码器x264或者x265编码。由于整个pipeline中,数据的处理速度并不一致,因此为了让整个过程的数据顺滑地流动起来,就需要做一部分的改造,比如解码后的raw data放入一个buffer队列中,AI推理异步从这个队列中取数据做推理,并把推理后的结果送到编码器中,这需要一定量针对FFmpeg的开发工作。幸运的是,英特尔已经帮用户做好了。FFmpeg中有一个英特尔的OpenVINO后端,用户直接使用就行。FFmpeg的DNN AI推理后端,目前只支持2个后端,一个是Tensorflow,另外一个就是英特尔的OpenVINO。总结:FFmpeg已经集成了OpenVINO作为AI 的后端推理引擎且英特尔有专门的团队去维护,大家可以放心使用。
这是一个和合作伙伴的实际案例。在视频增强和目标检测这两个场景下,使用了英特尔®第四代至强®可扩展处理器AMX优化的AI推理性能相对上一代平台分别提升了1.86倍和1.95倍。与此同时,精度损失被控制在可接受的范围,这也使得英特尔的客户在CPU上实现了全链路智能化编码,大幅降低了部署成本和运维成本。后记:本次,LiveVideoStackCon 2023上海站特设了MINI圆桌环节,特别邀请到了英特尔和互联网头部企业的技术大咖们。各位参与者围绕当下技术圈中备受关注的热门话题展开讨论,共同参与了趣味十足的“YES or NO”互动环节!各位与会者围绕当下技术圈中备受关注的热门话题展开讨论,共同探讨了行业内的新发展、新方向。我们相信,在各位技术人的不懈努力下,AI加速下的智能化编码一定会发展得越来越好。
