Koordinator 是阿里云基于过去我们建设的统一调度系统中积累的技术和实践经验,对外开源了新一代的调度系统。Koordinator 支持 Kubernetes 上多种工作负载的混部调度。它的目标是提高工作负载的运行时效率和可靠性(包括延迟敏感型负载和批处理任务)。Koordinator 不仅擅长混部场景,也同样支持大数据、AI 训练等任务调度场景。本文分享了使用 Koordinator 支持异构资源管理和任务调度场景的实践经验。
从 2022 年 11 月 ChatGPT 发布到现在,ChatGPT 所引起的关注、产生的影响可能已经超越了信息技术历史上的几乎所有热点。众多业界专家都被它征服,比如阿里云 CEO 张勇的看法是:“所有行业、应用、软件、服务,都值得基于大模型能力重做一遍。”NVIDIA CEO 黄仁勋称它带来了 AI 的 iPhone 时刻。ChatGPT 开启了新的时代,国内外的企业和科研机构纷纷跟进,几乎每周都有一个甚至多个新模型推出,从自然语言处理、计算机视觉到人工智能驱动的科学研究、生成式 AI 等,应用百花齐放;大模型成为业务提效和打开下一个增长点的关键。同样对于云计算、基础设施、分布式系统的需求也扑面而来。
为支撑百亿级、千亿级别参数量的大模型训练需求,云计算和基础设施需要提供更强大、可扩展的计算和存储资源。大模型训练依赖的的核心技术之一是分布式训练,分布式训练需要在多个计算节点之间传递大量的数据,因此需要一个带宽更高、延迟更低的高性能网络。为了发挥计算、存储和网络资源的最佳效能,保障训练效率,调度和资源管理系统需要设计更合理的策略。在此基础上,基础设施还需要在可靠性上持续增强,具备节点故障治愈和容错能力,确保训练任务的持续运行。大模型训练离不开异构计算设备,典型的就是我们熟知的 GPU。在 GPU 领域,NVIDIA 仍然占据着主导地位,其他厂商如 AMD 和国内的芯片制造商的机会在努力追赶。以 NVIDIA 为例,其强大的产品设计能力、扎实的技术实力和灵活的市场策略使其能够快速推出更优秀的芯片,但产品间的架构差异较大,例如 NVIDIA A100 型号和 NVIDIA H100 型号的系统架构差异十分明显,使用方式上也存在许多需要注意的细节,这给上层的调度系统和资源管理系统带来了不小的挑战。我们在阿里云支撑的大模型训练场景中,使用了 Koordinator 来解决基本的任务调度需求和异构设备资源管理需求。同时,使用 KubeDL 管理训练作业生命周期和训练作业排队调度需求。
Koordinator 不仅擅长混部调度场景,还针对大数据、AI 模型训练场景,提供了包括弹性 Quota 调度、Gang 调度等通用的任务调度能力。此外,它还具备精细化的资源调度管理能力,不仅支持中心化分配 GPU,还能感知硬件系统拓扑分配资源,同时支持 GPU&RDMA 的联合分配和设备共享能力。我们选择使用 KubeDL 来管理训练作业生命周期,是因为它不仅在支撑了内部大量 AI 领域相关场景,而且得益于其优秀的设计和实现都十分优秀,可运维性、可靠性和功能扩展性都非常出色,自身是一个统一的 controller,可以支持多种训练工作负载,如 TensorFlow、PyTorch、Mars 等。此外,它还可以适配不同调度器提供的 Gang 调度能力,可以帮助已经使用 KubeDL 项目的存量场景平滑的切换到 Koordinator;KubeDL 还内置了一个通用的作业排队机制,可以有效解决作业自身的调度需求。Koordinator 和 KubeDL 的强强联合,可以很好的解决大模型训练的调度需求。Job 是一种更高层次的抽象,通常具有特定的计算任务或操作。它可以分割成多个子任务并行完成,也可以拆分成多个子任务协作完成。通常 Job 不会依赖其他的工作负载,可以独立的运行。而且 Job 比较灵活,在时间维度、空间维度、或者资源方面的约束都比较少。
Job 同样需要经过调度程序调度,这也就意味着 Job 同样在调度时需要排队。那为什么需要排队呢?或者说我们可以通过排队解决哪些问题?是因为系统中的资源有限的,我们的预算也是有限的,而 Job 的数量和计算需求往往是无限的。如果不进行排队和调度,那些计算需求较高或者执行时间较长的 Job 就会占用大量的资源,导致其他 Job 无法获取到足够的资源进行计算,甚至可能导致集群系统崩溃。因此,为保证各个 Job 能够公平的获得资源,避免资源争夺和冲突,就需要对 Job 进行排队和调度。我们使用 KubeDL提供的通用的 Job 排队和调度机制解决这个问题。KubeDL 因为本身就内置支持了多种训练工作负载,因此它天然支持按照 Job 粒度进行调度;并且它具备多租户间的公平性保障机制,减少 Job 间的资源争夺和冲突,排队和调度的过程中,KubeDL 根据 Job 的计算需求、优先级、资源需求等因素进行评估和分配,确保每个 Job 都能够得到合适的资源进行计算。KubeDL 支持多种扩展插件,如 Filter 插件,Score 插件等,可以进一步扩展其功能和特性满足不同场景的需求。Job 排队要解决的核心问题之一是资源供给的公平性,一般在调度系统中都是通过弹性 Quota 机制来解决。弹性 Quota 机制要解决的几个核心问题:首先是保障公平性,不能让某一些任务的资源需求过高导致其他任务被饿死,应尽量让大部分任务都能得到资源;其次需要有一定的弹性能力,能够把空闲的额度共享给当下更需要资源的任务,同样还要能够在需要资源时,把共享出去的资源拿回来,这意味还需要提供具备灵活的策略满足不同场景的需求。Koordinator 实现了弹性 Quota 调度能力,可以保障租户间的公平性。我们在设计之初就考虑兼容 scheduler-plugins 社区项目中定义的 ElaticQuota CRD,这样方便存量的集群和用户可以平滑的过度到 Koordinator。另外,我们不仅是兼容 ElasticQuota 原有按照 Namespace 管理 Quota 的能力,还支持按照支持按照树形结构进行管理,可以跨 Namespace。这样的方式可以很好的支持一个复杂的组织的额度管理需求,比如一家公司里多个产品线,每个产品线的预算和使用情况都不一样,都可以转为 Quota 进行管理,并借助弹性 Quota,把暂时没有用到的空闲资源通过额度的形式临时共享给其他部门使用。当一个 Job 经过排队被调度后,Job Controller 会创建出一批子任务,对应到 K8s,就是一批 Pod。这些 Pod 往往需要协调一致的启动运行。这也就要求调度器在调度时一定要按照一组 Pod 分配资源,这一组 Pod 一定都可以那可以申请到资源或者一旦有一个 Pod 拿不到资源都认为是调度失败。这也就是调度器需要提供的 All-or-Nothing 调度语义。如果我们不这样按照一组调度,会出现因为多个作业在资源调度层面出现争抢,是有可能出现资源维度的死锁,即至少两个 Job 会出现拿不到资源的情况,即使原本空闲资源足够其中一个 Job 运行的,也会拿不到。比如下图中,Job A 和 Job B 同时创建一批 Pod,如果不在中间的 Scheduling Queue 进行排序而是随意的调度,就会出现 Job A 和 Job B 的 Pod 各持有了一部分节点的部分资源,如果此时集群资源紧张,很有可能 Job A 和 Job B 都可能拿不到资源。但如果排序后,我们尝试先让其中一个 Job 的 Pod 先一起尝试优先分配资源,那么至少保障一个 Job 可以运行。当一个 Job 切分的一组 Pod 非常大时,而集群内的资源又不是十分充足,或者 Quota 不是很多时,可以把这样的一组 Pod 切分成更多个子组,这个切割的大小以能运行任务为基础,假设一个 Job 要求最小切割粒度是每组 3 个 Pod,那么这个最小粒度,一般在调度域中称为 min available。具体到 AI 模型训练领域,一些特殊的 Job 比如 TFJob,它的子任务有两种角色,这两种角色在生产环境中,也是需要设置不同的 min available 的。这种不同角色的区分的场景还有可能要求每个角色的 min available 都满足时才可以认为符合 All-or-Nothing 语义。Koordinator 内置了 Coscheduling 调度能力,它兼容社区的 scheduler-plugins/coscheduling 定义 PodGroup CRD,还支持把多个 PodGroup 联合调度,这样就可以支持按角色设置 min available 场景。Koordinator 实现了一个 KubeDL Gang Scheduler 插件,这样就可以和 KubeDL 做集成一起支撑这类调度场景。K8s 是通过 kubelet 负责设备管理和分配,并和 device plugin 交互实现整套机制,这套机制在 K8s 早期还是够用的,其他厂商如 AMD 和国内的芯片制造商也抓住机会努力追赶。
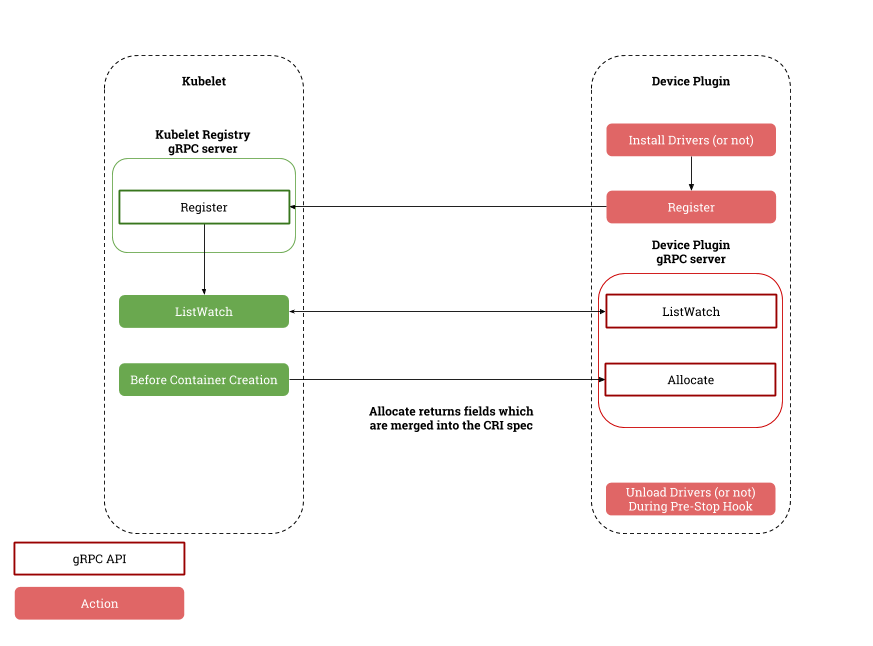
kubelet 与 device plugin 协作流程首先 K8s 只允许通过 kubelet 来分配设备,这样就导致无法获得全局最优的资源编排,也就是从根本上无法发挥资源效能。比如一个集群内有两台节点,都有相同的设备,剩余的可分配设备数量相等,但是实际上两个节点上的设备所在的硬件拓扑会导致 Pod 的运行时效果差异较大,没有调度器介入的情况下,是可能无法抵消这种差异的。其次是不支持类似 GPU 和 RDMA 联合分配的能力。大模型训练依赖高性能网络,而高性能网络的节点间通信需要用到 RDMA 协议和支持 RDMA 协议的网络设备,而这些设备又和 GPU 在节点上的系统拓扑层面是紧密协作的,比如下面这张图是 NVIDIA 的 A100 型号机型的硬件拓扑图,我们可以看到,PCIe Switch 下挂了 GPU 和高性能网卡,我们需要就近分配这两个设备,才能做到节点间通信的低延迟。而且这里比较有意思的是,当如果需要分配多个 GPU 时,如果涉及到了多个 PCIe Switch,就意味着需要分配多个网卡,这就和 K8s 的另一个限制有关系,即声明的资源协议是定量的,而不是随意变化的,也就是说用户实际上也不知道这个 Pod 需要多少支持 RDMA 的网卡,用户只知道要多少个 GPU 设备,并期望就近分配 RDMA 的网卡而已。
而且 kubelet 也不支持设备的初始化和清理功能,更不支持设备的共享机制,后者在训练场景一般用不到,但在线推理服务会用到。在线推理服务本身也有很明显的峰谷特征,很多时刻并不需要占用完整的 GPU 资源。K8s 这种节点的设备管理能力一定程度上已经落后时代了,虽然现在最新的版本里支持了 DRA 分配机制(类似于已有的 PVC 调度机制),但是这个机制首先只在最新版本的 K8s 才支持,但实际情况是还有大量存量集群在使用,并且升级到 K8s 最新版本也并不是一个小事情,所以我们得想其他办法。我们在 Koordinator 中提出了一种方案,可以解决这些问题,做到精细化的资源调度。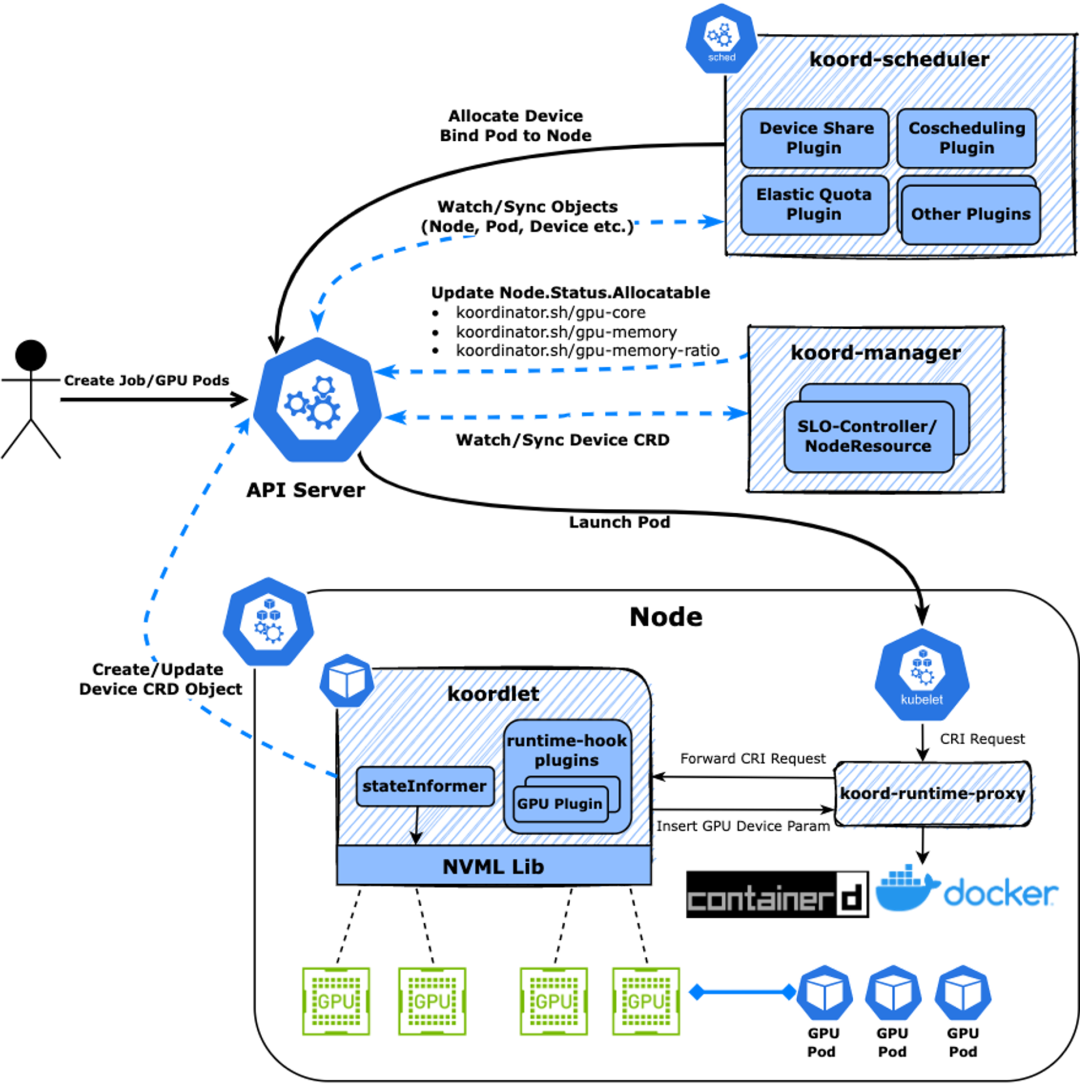
从上面的图中可以看到,用户创建的一个 Pod,由 koord-scheduler 调度器根据 koordlet 上报的 Device CRD 分配设备,并写入到 Pod Annotation 中,再经 kubelet 拉起 Sandbox 和 Container,这中间 kubelet 会发起 CRI 请求到 containerd/docker,但在 Koordinator 方案中,CRI 请求会被 koord-runtime-proxy 拦截并转发到 koordlet 内的 GPU 插件,感知 Pod Annotation 上的设备分配结果并生成必要的设备环境变量等信息返回给 koord-runtime-proxy,再最终把修改后的 CRI 请求转给 containerd/docker,最终再返回给 kubelet。这样就可以无缝的介入整个容器的生命周期实现自定义的逻辑。Koordinator Device CRD 用来描述节点的设备信息,包括 Device 的拓扑信息,这些信息可以指导调度器实现精细化的分配逻辑。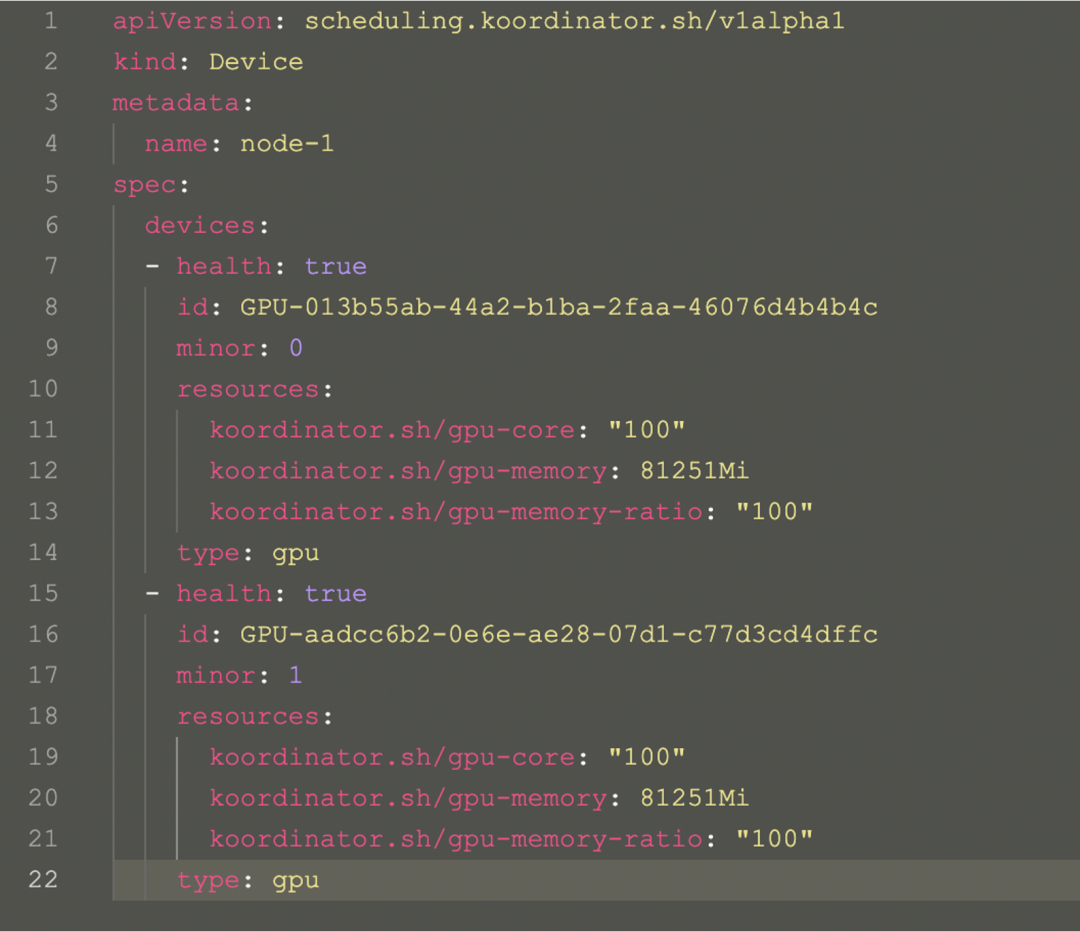
Koordinator Device 对象
前面提到了 Koordinator 单机侧依靠 koord-runtime-proxy 协作完成设备信息注入,我们自己也意识到,koord-runtime-proxy 这种方式其实不太好在大家的集群内落地。这涉及到修改 kubelet 的启动参数问题。所以 Koordinator 社区后续会引入 NRI/CDI 等机制解决这个场景的问题。这块工作正在和 Intel 相关团队共建。NRI/CDI 是 containerd 支持的一种插件化机制。其部署方式有点类似于大家熟悉的 CNI,支持在启动 Sandbox/Container 前后获得机会修改参数或者实现一些定制逻辑。这相当于是 containerd 内置的 runtimeproxy 机制。前面也提到,大模型训练不仅仅只用到了 GPU,还依赖 RDMA 网络设备。要确保 GPU 和 RDMA 之间的延迟尽可能的低,否则会因为设备间的延迟放大到整个分布式训练网络中,拖慢整体的训练效率。这就要求在分配 GPU 和 RDMA 时需要感知硬件拓扑,尽可能就近分配这种设备。尝试按照同 PCIe,同 NUMA Node,同 NUMA Socket 和 跨 NUMA 的顺序分配,延迟依次升高。而且我们还发现同一个硬件厂商的不同型号的 GPU,它们的硬件系统拓扑是不一样的,这就要求我们的调度器需要感知这些差异。比如下图是 NVIDIA A100 型号的 System Topology 和 NVIDIA H100 的一个简单的设备连接图。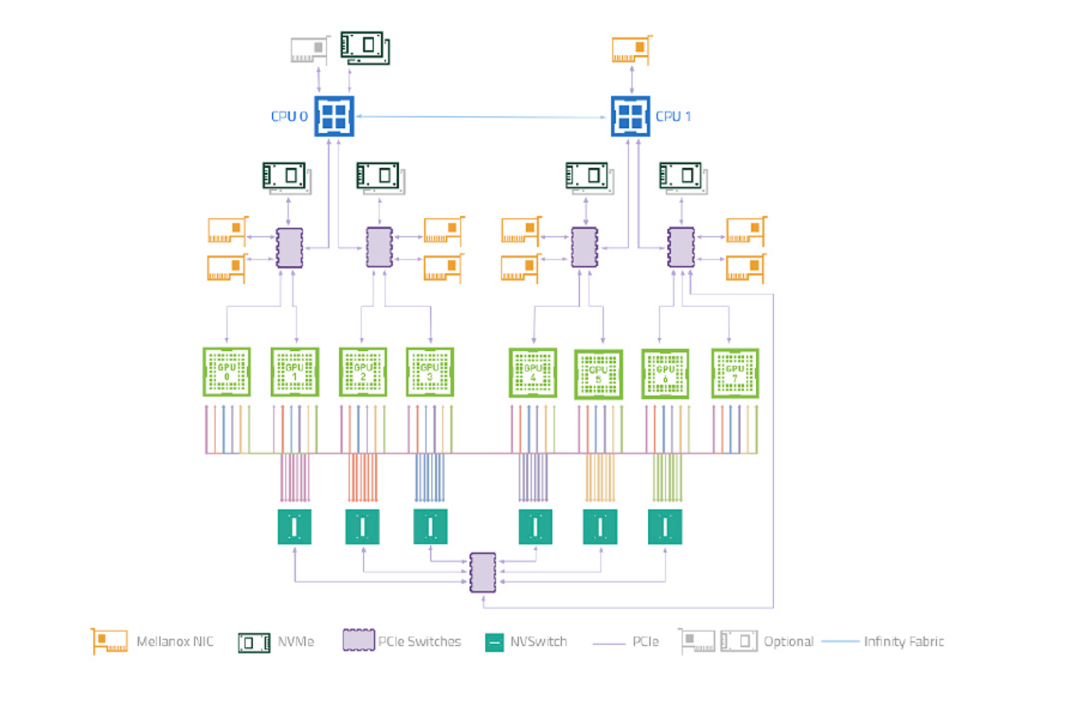
NVIDIA A100 System TopologyNVIDIA A100 GPU 之间的 NVLINK 联通方式和 NVIDIA H100 型号就不一样,NVSwitch 的数量也不一样,这种差异就会给使用方式带来很大的差异。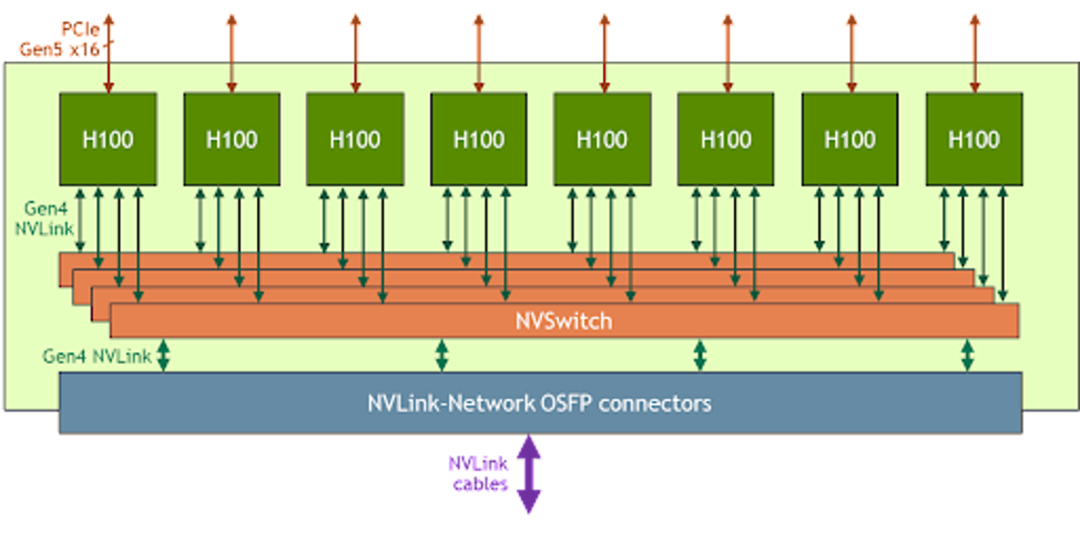
NVIDIA-based system 在多租模式下的差异
NVIDIA H100 GPU 在多租 VM 场景下的特殊之处,多个 GPU 之间联通需要操作 NVSwitch 才可以实现。在多租场景中,NVIDIA 为保障安全,会通过 NVSwitch 管理 NVLink 的隔离状态,并且要求只能由授信的软件操作 NVSwitch。这个授信软件是可以自定义的。NVIDIA 支持多种模式,一种是 Full Passthrough 模式,这种模式把 GPU 和 NVSwitch 都直通到 VM 的 Guest OS,这样做的好处是使用起来很简单,但代价是当 GPU VM 多了,NVLINK 的带宽会减少(原文:Reduced NVLink bandwidth for two and four GPU VMs)。另一种称为 Shared NVSwitch 多租户模式,它只要求把 GPU 直通到 Guest OS,然后通过一个特殊的 VM,称为 Service VM 管理 NVSwitch,并通过 ServiceVM 调用 NVIDIA Fabric Manager 激活 NVSwitch 实现 GPU 间通信。这种模式就不会出现因为 Full Passthrough 模式的弊端,但使用方式明显要更复杂一些。这种特殊的硬件架构和使用方式,还导致在分配 GPU 时有一些额外的要求。NVIDIA 定义了哪些 GPU 设备实例可以组合一起分配,比如用户申请分配 4个 GPU,那必须是按照规定的 1,2,3,4 号一起或者 5,6,7,8 一起分,否则就会导致 Pod 无法运行。这种特殊的分配方式的背后原因我们不得而知,但分析这些分配约束可以发现,厂商规定的这种组合关系正好符合硬件系统拓扑结构,也就是可以满足前面讲到的 GPU&RDMA 联合分配期望的分配结果。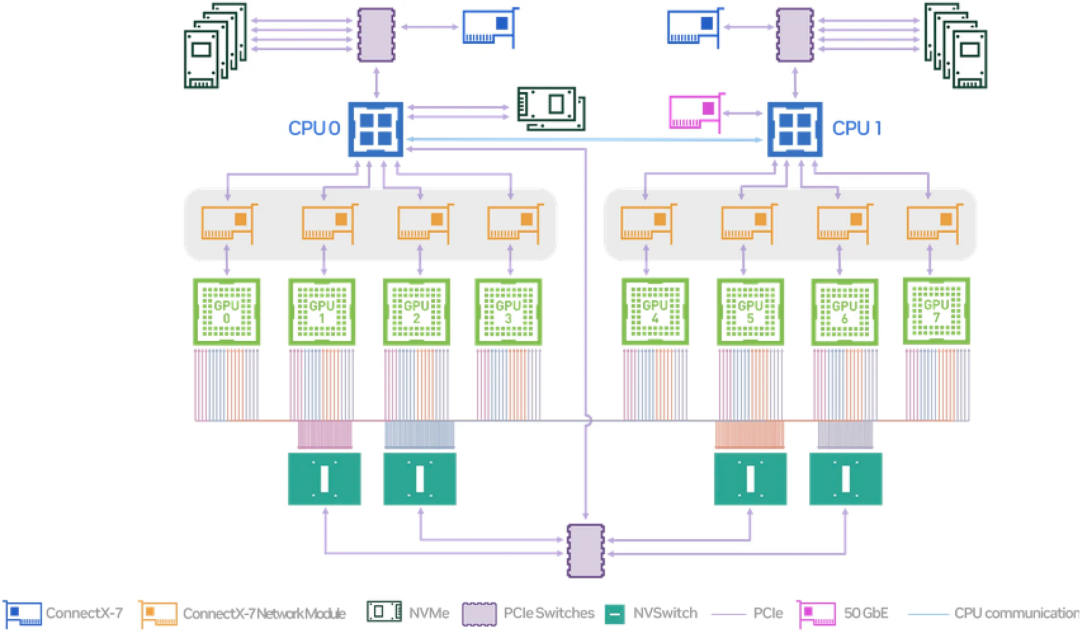
NVIDIA H100 System Topology
MySQL VS PostgreSQL 谁是世界第一?