今天,商汤宣布日日新大模型旗下自然语言应用“商量SenseChat”正式面向广大用户开放。用户已经可以通过访问https://chat.sensetime.com 注册使用。
几天前发布的最新财报中,商汤用了很大篇幅讲述在 AI 大模型领域取得的成绩。2023 年上半年,商汤实现营业收入 14.3 亿元,同比增长 1.3%。其中生成式 AI 相关收入实现 670.4% 的增长,对集团业务贡献从 2022 年的 10.4% 增至 20.3% ,已经成为最重要的新增长引擎。
值得关注的是,商汤商量 SenseChat 的基模型(foundation model)书生·浦语 InternLM-123B 由商汤与上海人工智能实验室联合多家国内顶级科研机构最新训练完成,在全球 51 个知名评测集(包括 MMLU , AGIEVAL , ARC , CEval , Race , GSM8K 等)共计 30 万道问题集合上测试成绩整体排名全球第二,在主要评测中 12 项成绩超越 GPT-4 ,排名第一。生成式 AI 的全面爆发,也在加速推动行业创新。根据弗若斯特沙利文发布的《 AI 大模型市场研究报告( 2023 )》,商汤在产品技术、战略愿景、生态开放构建等综合竞争力国内第一。一、大模型背后:技术为王
商汤集团核心业务板块收入的加速增长,尤其是生成式 AI 收入的暴增,离不开扎实的底层技术支持。今年 4 月 10 日,商汤推出大模型“日日新”,包括自然语言处理模型“商量”、文生图模型“秒画”和数字人视频生成平台“如影”等。其中,商量SenseChat,也是国内最早推出基于千亿参数大语言模型的聊天机器人产品之一。仅两个月后,商汤与上海人工智能实验室联合多家国内顶尖科研机构于 6 月发布首个综合能力超越 GPT-3.5-turbo(GPT3.5 最优秀的模型之一)的基模型书生·浦语大模型 InternLM-104B(1040 亿参数),使用 1.6 万亿 token 的多语言语料训练,支持语言达 20 多种。当时,InternLM 联合团队选取了 20 余项评测对其进行检验,其中包含全球最具影响力的四个综合性考试评测集,PK 对手包括 GLM-130B(开源)、LLaMA-65B(开源)、ChatGPT 和 GPT-4:由加州大学伯克利分校等高校构建的多任务考试评测集 MMLU;微软研究院推出的学科考试评测集 AGIEval(含中国高考、司法考试及美国 SAT、LSAT、GRE 和 GMAT 等);由上海交通大学、清华大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集 C-Eval;由复旦大学研究团队构建的高考题目评测集 Gaokao。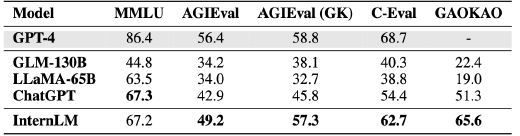 全面测试后,针对上述四个重要评测集的成绩对比如上,满分100分。
全面测试后,针对上述四个重要评测集的成绩对比如上,满分100分。
结果显示,InternLM 不仅显著超越 GLM-130B 和 LLaMA-65B 等学术开源模型,还在 AGIEval、C-Eval,以及 Gaokao 等多个综合性考试中领先 ChatGPT;在以美国考试为主的 MMLU 上表现和 ChatGPT 持平。综合性考试的成绩反映出 InternLM 知识掌握扎实,综合能力也很优秀。又过了两个月,在上万块 GPU 的支持下,经过多次试错调优,InternLM-123B 于 8 月完成研发,其能力实现飞跃式发展:语言、知识、理解、推理和学科五大能力均有显著提升。InternLM-123B 在主要评测中 12 项成绩排名第一,超越 GPT-4。其中,在评测集综合考试中 AGIEval 分数 57.8,超越 GPT-4 位列第一;知识问答 CommonSenseQA 评测分数 88.5 排名第一, NaturalQuestions 排名第二;InternLM-123B 在阅读理解 C3、CMRC、RACE (Middle)、RACE (High)、LAMBADA 五项评测中成绩全部居榜首;此外,InternLM-123B 在推理WinoGrande、StoryCloze、HellaSwag、StrategyQA、SIQA 几项评测中成绩排名第一。
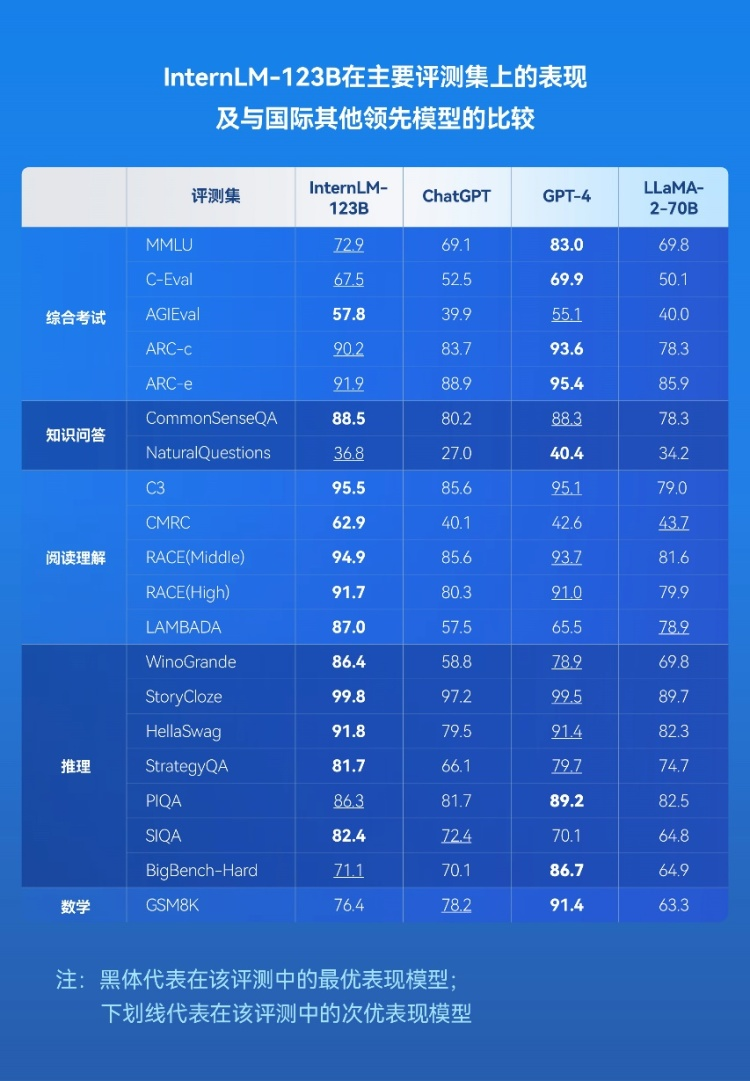 InternLM-123B 在 12 项权威评测中超越 GPT-4 位列第一。
InternLM-123B 在 12 项权威评测中超越 GPT-4 位列第一。
除了生成的内容更加准确、可靠,作为国内最早实现“工具调用”的大模型,InternLM-123B 最让人印象深刻的是处理更加复杂场景的能力更强:它会调用工具进行多步推理和计算。在调用插件工具的过程中,大语言模型可能无法一次性成功调用工具解决问题, InternLM-123B 还具备自主反思和修正错误的能力。比如,InternLM-123B 升级了代码解释器的调用能力,大模型可以调用代码解释器,在工具的帮助下完成复杂方程求解,提升解决复杂数学计算等任务的能力。除了代码解释器(比如使用 Python 解释器),InternLM-123B 还可以调用 API 和搜索这类常用工具,应对更加复杂的用户需求。你可以脑补、畅想这样一个情景:告诉 InternLM-123B 驱动的聊天助手,要去哪里旅行,什么时间出发。这位聊天助手会调用搜索找到相关网页,然后进入浏览器页面,主动搜索符合要求的出行方案,帮你搞定。其实,InternLM-123B 强大的工具调用能力为上层应用构建灵活的 AI 智能体(Agents)提供了底层支持。所谓 AI 智能体,在大模型语境下,可以理解成能自主理解、规划、执行复杂任务的系统。GPT-4 驱动的 Auto-GPT 已初见端倪:它不再是 ChatGPT ,而是一个比较完整的模型智能体,因为它可以通过大模型去调用各种工具,包括其他大模型。AI 智能体被业内认为是 AIGC 之后的下一个热点,也被认为是通向 AGI 的重要方向与趋势。今年 6 月,商汤、清华大学、上海人工智能实验室等提出了能够自主学习解决任务的通才 AI 智能体 Ghost in the
Minecraft (GITM)。新智能体能够完全解锁《我的世界》( Minecraft )主世界的整体科技树的全部 262 个物品(以往智能体方法包括 OpenAI 和 DeepMind 在内总共只解锁了 78 个),并可大大减少训练投入。同时,近年来,一些巨头(比如英伟达)也在通过 Minecraft 探索 AI 智能体,真人玩家能够完成游戏任务,智能体几乎都能完成。Open AI 最近也收购了一家 AI 公司,相当于买下了一个开源的 Minecraft。Meta 曾在 6 月宣布了一系列处于不同开发阶段的技术,其中一个也是 AI 智能体。二、“三位一体”,持续发力
能够在大模型上不断迭代,并持续保持领先,离不开商汤多年来“三位一体”——数据、算法和算力——上的持续发力。早在 2019 年,商汤便使用上千张 GPU 进行单任务训练,推出了 10 亿参数规模的视觉模型,算法效果达到了当时业界最佳。2021 年至 2022 年期间,商汤还训练并开源了 30 亿参数的通用视觉模型书生 INTERN。与算法模型持续联动的,还有底层算力上的不断投入与创新。商汤称,SenseCore 商汤 AI 大装置上线 GPU 数量由 2023 年 3 月底的 2.7 万块,提升至日前的约三万块,算力规模提升 20% 至 6 ExaFLOPS。同时,2023 年上半年,商汤共有超过 1000 个参数量数十亿至上千亿的大模型在大装置上完成训练,并实现了技术迭代。2021 年 6 月,商汤在接受机器之心采访时曾表示,待年底位于上海临港新片区的建筑群全部建成后, AI 计算峰值速度将达到 3740 Petaflops(1
petaflop 等于每秒一千万亿次浮点运算),可以在一天之内完整训练 OpenAI 的千亿参数模型 GPT-3。现在国内人工智能领域,商汤大装置所提供的高性能计算名列前茅,不仅为做算法研究的人员提供了充足的算力,使他们能够快速地进行实验试错,大装置中所积累的实用工具也缩短了创新的验证周期。不过,要做出大模型,除了算法经验和 GPU,也需要专业经验的积累和摸索。商汤也在这些方面积累了很久。比如,制作高性能模型对训练数据的体量和质量都有着极高的要求,而模型的价值观、安全性也受训练数据的影响。通俗点说,目前大模型的技术路径决定了拥有大量高质量文本语料也意味着自动获得了海量的标注质量高的数据。InternLM 性能领先,离不开体量业界领先的原始语料数据,更离不开强大的语料清洗和实验的能力。为对万亿 token 级别的数据进行高质量清洗,团队投入了数百台服务器搭载千卡 GPU 的计算资源,采用算法+人工的方式,对这些原始语料分门别类,精细化清洗,以确保其质量和安全。报告称,高质量数据的生产能力达到每月逾 2 万亿 token,预计年底高质量数据储备将突破 10 万亿 token,以支持更加强大的基模型的训练。此外,要保证大量 GPU 长时间稳定运行,需要经历许多试错。商汤科技自 2018 年起便致力于 AI 大模型的研发,有着数年的技术积淀和实践经验。早在 2019 年,商汤便具备了千卡并行的系统能力,使用上千张 GPU 卡进行单任务训练。4 月,杨帆接受媒体采访时曾谈到,训练时大模型常遇到“梯度爆炸”,或者硬件故障造成机器过载宕机,以前宕机频率是十分钟一次,商汤现在能做到千卡级系统一周一次,这也是不断调试的结果。GPU 大规模并行之后,还需不断调试并联方法,提高算力效率,商汤目前在千卡集群上能达到的最高效率是 90% 利用效率。值得一提的是,为满足客户的不同需求,全面覆盖业务场景,商汤还推出了多个行业大模型,并且和上海人工智能实验室联合开源了 InternLM-7B 。目前,InternLM-7B 的部分训练数据、训练代码及基模型权重已经向学术界及工业界免费开源,并支持免费商用。InternLM-7B 也登顶了多个模型测试榜单,是性能最好的轻量级基模型之一,在多个榜单中,表现甚至超过参数量更大的 LLaMA2-13B。另外,InternLM-20B 也将迎来开源。InternLM-20B 具备优秀的调用工具能力,同时,其适中的模型大小使得其运行成本更低,适合建构各类应用。其实商汤的AI大模型研发,是从 2018 年就开始的。在 2019 年,商汤就推出了 10 亿参数量规模的视觉模型,在视觉 AI 技术方面达到了全球领先。2021 年以来,商汤又陆续训练了百亿参数规模的超大视觉模型,以及 320 亿参数量的全球最大的通用视觉模型,并在自动驾驶、工业质检、医疗影像等多个领域得到广泛应用。可见商汤投入到大模型这条路径,乃至最终迈向 AGI 通用人工智能,可谓水到渠成。多年来,商汤始终坚持长期战略,持续投入到人工智能领域的重要前沿研究中,并不断取得成果。今年 6 月,商汤联合团队论文 Planning-oriented
Autonomous Driving,因提出的自动驾驶通用大模型 UniAD 获得 CVPR 2023 最佳论文,这不但是行业首个感知决策一体化自动驾驶大模型,也是 CVPR 史上第一篇以自动驾驶为主题的最佳论文。最新财报显示,商汤自动驾驶大模型将于第四季度准备就绪,用于量产。长远来看,大模型的格局此刻或许仍然风起云涌,但长期战略带来的持久影响将在未来,让我们都走得更加深远。