---- 本周为您解读 ⑥ 个值得细品的 AI & Robotics 业内要事 ----
Gemini 模型算力达 GPT-4 五倍,关于 Gemini 模型有哪些传闻?SemiAnalysis 的爆料,放出哪些重要信息?谷歌的算力储备历程回顾?新定义之 GPU 富人与 GPU 贫困者,「GPU 贫困者」应该关注哪些方向?...MLLM 对齐又有新进展?MLLM 的对齐与实现 AGI 有何联系?Less is More 有和对齐工作有和联系?RLHF 怎么办?...特斯拉 FSD V12 系统技术详解;FSD V12 系统为什么改用端到端方案,优势在哪?端到端技术方案有哪些不足?FSD V12 系统的训练基础是什么?目前自动驾驶技术分为哪两派?...LLM 为什么会产生幻觉?减少模型产生的幻觉有哪些方法?为什么会发生大模型「幻觉滚雪球」现象?为何上下文长度如此重要,且能在 LLM 中起到举足轻重的作用?目前有哪些可以加速 Transformer 并将上下文长度增加到 100K 的优化技术?… 5. 国内 11 个 LLM AI 产品陆续向公众大规模开放 是哪 8 家机构的 2C 大模型获批?对大模型赛道意味着什么?《生成式人工智能服务管理暂行办法》是做什么的?国内还有哪些相关管理办法?... 6. 《国资报告》杂志报道央企对大模型技术的采用情况 我国领先国资企业对大模型技术主要有哪些不同的采用方案?哪些央企或有机会以通用大模型赋能千行百业?......本期完整版通讯含以上 6 项专题解读 + 31 项本周 AI & Robotics 赛道要事速递,其中技术方面 9 项,国内方面 12 项,国外方面 10 项...
本期通讯总计 26772 字,可免费试读至 5 % 消耗 99 微信豆即可兑换完整本期解读(约合人民币 9.9 元) 要事解读 ① 谷歌赶超 GPT-4 之路:用算力猛怼?
事件:据 SemiAnalysis 分析师 Dylan Patel 和 Daniel Nishball 爆料,谷歌 Gemini 大模型算力为 GPT - 4 的五倍,同时谷歌拥有的 TPUv5 比 OpenAI、Meta、CoreWeave、甲骨文和亚马逊拥有的 GPU 总和还要多。这次谷歌 Gemini 的爆料都透露了什么?[13]Dylan Patel 曾在英特尔、AMD、高通等公司担任过从设计工程师到市场营销经理等的角色,其于今年 7 月 11 日曾曝光 GPT-4 的架构。以下解读基于多方信源汇总形成1、谷歌的下一代大模型 Gemini,算力已达 GPT-4 的 5 倍。2、谷歌 Gemini 已经开始在新的 TPUv5 Pod 上进行训练,算力高达~1e26 FLOPS,比训练 GPT-4 的算力还要大 5 倍。3、Gemini 可以访问多个 TPU pod 集群,具体来讲是在 7+7 pods 上进行训练。4、初代的 Gemini 应该是在 TPUv4 上训练的,并且这些 pod 并没有集成最大的芯片数——4096 个芯⽚,而是使用了较少的芯片数量,以保证芯片的可靠性和热插拔。如果所有 14 个 pod 都在合理的掩模场利用率(MFU)下使⽤了约 100 天,那么训练 Gemini 的硬件 FLOPS 将达到超过 1e26。5、⾕歌模型 FLOPS 利⽤率在 TPUv4 上⾮常好,即使在⼤规模训练中,也就是 Gemini 的第⼀次迭代,远远⾼于 GPT-4。尤其是,就模型架构优越方面,如增强多模态,更是如此。6、第⼀个在 TPUv5 上训练的 Gemini 在数据⽅⾯存在⼀些问题,所以不确定谷歌是否会发布。这个~1e26 模型可能就是,公开称为 Gemini 的模型。7、Gemini 集成大模型与 AI 生成,训练数据库为 Youtube 上 93.6 亿分钟的视频字幕,其总数据集大小约为 GPT-4 的两倍。8、Gemini 或使用 Moe 架构与投机采样技术,通过小模型提前生成 token 传输至大模型进行评估,提高模型总推理速度。9、谷歌手中的 TPUv5 数量超 OpenAI、Meta、CoreWeave、甲骨文和亚马逊拥有的 GPU 总和。10、在 2023 年底,谷歌的算力将达到 GPT-4 预训练 FLOPS 的五倍。而考虑谷歌现在的基建,到明年年底,这个数字或许会飙升至 100 倍。1、早在 2006 年,谷歌就开始提出了构建人工智能专用基础设施的想法,并于 2013 年将数据中心的数量增加一倍,以此大规模部署人工智能。2、谷歌最著名的项目 Nitro Program 于 2013 年发起,专注于开发芯片以优化通用 CPU 计算和存储。主要的目标是重新思考服务器的芯片设计,让其更适合谷歌的人工智能计算工作负载。3、自 2016 年以来,谷歌已经构建了 6 种不同的 AI 芯片,TPU、TPUv2、TPUv3、TPUv4i、TPUv4 和 TPUv5。谷歌主要设计这些芯片,并与 Broadcom 进行了不同数量的中后端协作,然后由台积电生产。4、谷歌拥有 TPUv4(PuVerAsh)、TPUv4 lite,以及内部使⽤的 GPU 的整个系列。实际上,谷歌拥有的 TPUv5 比 OpenAI、Meta、CoreWeave、甲骨文和亚马逊拥有的 GPU 总和还要多。5、今年 8 月 29 日,谷歌云在 Google Cloud Next'23 年度大会上推出了全新的 TPU 产品 Cloud TPU v5e。与 TPU v4 相比,TPU v5e 的成本不到 TPU v4 的一半,使更多公司有机会训练和部署更大、更复杂的 AI 模型。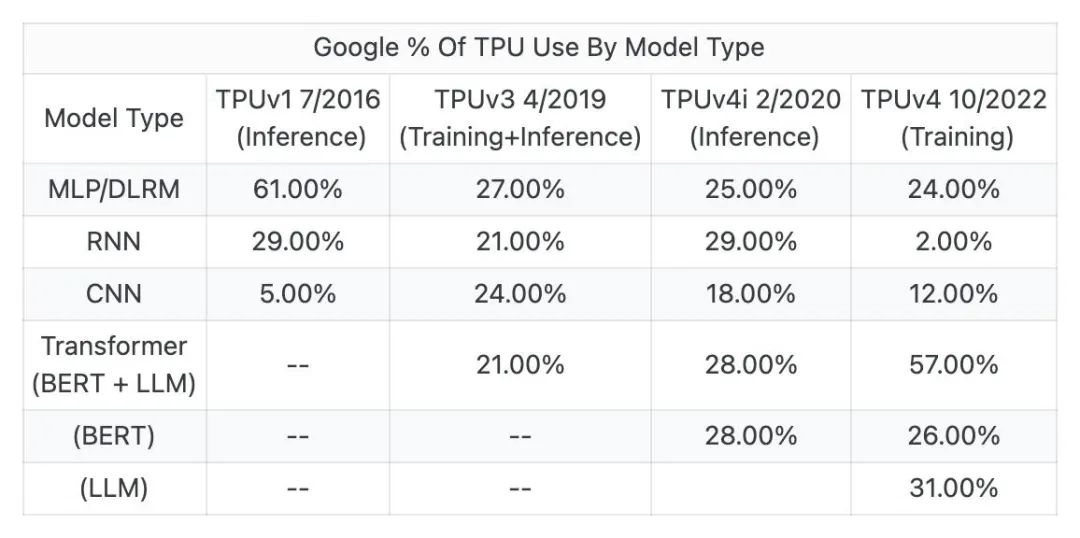
(本图基于 SemiAnalysis 爆料数据形成)「GPU 贫困」的小公司,如何在巨头找到自己的优势?2024 年底,GPU 总数可能会达到十万块。OpenAI、谷歌、Anthropic、Inflection、X、Meta 这些巨头或明星初创企业,手里有 20 多万块 A100/H100 芯片,平均下来,每位研究者分到的计算资源都很多。对「GPU 贫困」的小公司、团队及开源研究者来说,有以下业内建议汇总: