

以ChatGPT为代表的AIGC车载应用,已经推动汽车智能化迈入新风口。前不久,微软和奔驰宣布,双方将展开合作,将ChatGPT人工智能服务整合到汽车中,为搭载MBUX交互系统的车型车主提供更智能、更个性化的语音助手体验。吉利汽车也透露,目前公司已经具备了全栈自研的AI大模型技术,不仅覆盖绘画、音乐、语言等功能,也具备自动驾驶AI大模型能力,可实现十亿级别、百亿级、千亿级别数据大模型全覆盖。不过,AI大模型的实现需要强大算力来支撑训练和推理过程,因此AIGC车载应用对端侧推理芯片提出了更高的算力需求。叠加摩尔定律日趋放缓,甚至接近失效,AIGC车载应用面临尤为严峻的算力挑战。有业内企业统计,从2012年到2018年,训练AI算力增长了30万倍,但摩尔定律通用算力只有7倍增长,可见摩尔定律已难满足AIGC对算力的需求。“后摩尔时代,车载大算力芯片设计最大的挑战是如何找到综合异构集成算力的灵活可扩展芯片架构,以及高性能、低延迟、高可靠性的互连方式,而Chiplet及GPNPU是最佳技术路径。”芯砺智能创始人兼CEO张宏宇表示。可见,从AI芯片的核心NPU性能出发,类似GPU的NPU架构可以同时满足高速计算和掩盖数据存取延时,高速总线互连Chiplet可以使得多卡推理延迟变小。这也正是芯砺智能的核心技术优势,即赋能高速总线互连的多核推理在实际推理中表现如一颗大芯片。作为全球首家利用Chiplet技术研发车载算力芯片的企业,芯砺智能于2021年正式成立。针对车载芯片的特殊应用需求,芯砺智能不仅开创了独家车规级Chiplet Die-to-Die互连技术,还成功地在多国申请了独创的Die-to-Die互连IP专利。目前,芯砺智能的车规级Chiplet Die-to-Die互连IP已经完成流片。据其介绍,预计今年底将实现首颗车规级Chiplet SoC流片,2025年量产。在巨头林立的车载芯片市场和Chiplet技术生态圈,芯砺智能凭什么率先拿下车规级Chiplet大算力芯片入场券?天时地利人和,或许是最佳答案。
在“电动化”迈向“智能化”过程中,新能源汽车的智能属性并未完全被释放,而AIGC被智能汽车寄予厚望。一方面,以ChatGPT为代表的AIGC技术可实现智能座舱的拟人化与情感化,或将弥补汽车智能短板,赋予其更智能更丰富的座舱交互。例如语音助理化身为积极主动的真人AI虚拟副驾驶等主动式、多模态车载交互体验,正突破传统基于唤醒词的被动式交互,成为智能座舱的下一个竞技场,而这些功能的实现,需要依靠强大的芯片算力支持。另一方面,针对智能驾驶的感知能力提升,以BEV+Transformer 为代表的大模型可以提取特征向量,在统一的3D坐标系空间内做特征融合,并结合时序信息进行动态识别,最后进行多任务输出,如静态语义地图、动态检测等。不过,鉴于AIGC大模型和智能驾驶的车辆感知能力都是以Transformer 架构为基础,端侧部署需要针对Transformer进行优化。针对GEMM优化所产生的Transformer计算瓶颈,以及Self-attention的访存瓶颈,仍需要足够多的AI算力,支持AI模型的推理和部署。可见,汽车智能化的快速发展,带动车载芯片的算力需求(智能驾驶、智能座舱)呈井喷式发展。随着AIGC带动汽车智能化纵深发展,算力之殇日渐显著,若无法解决AI模型算力需求增长与摩尔定律的矛盾,势必将抑制大模型的上车应用和普及。而Chiplet技术,被认为是后摩尔时代半导体产业针对大算力芯片的最优解之一。据悉,Chiplet技术可以通过小芯片“搭积木”的方式完美地解决性能扩展的问题,此前主要被应用于服务器领域,但服务器上普遍采用的Chiplet技术并不能很好地满足车载市场的需求,因为后者既需要高性能、低成本,同时还要满足高安全性和可靠性。可以说,车载芯片的要求比服务器市场或任何其他消费类市场都要更高、更复杂。若要满足后摩尔时代车载芯片的多样化需求,还需通过创新型设计突破先进工艺技术瓶颈。顺应汽车智能化“天时”,针对车载大算力芯片需求,芯砺智能通过在 Chiplet 技术的落地及实践方面采取了一系列独创的设计,主要包含芯片架构及片间互连(D2D)两个方面。比如,在芯片架构方面,芯砺智能的Chiplet SoC既没有采用性能受限的移动计算架构,也没有采用高性能计算(HPC)架构,而是打造了基于异构集成的嵌入式高性能计算平台(eHPC),以应对汽车领域对高算力、低成本的车规级算力平台芯片需求。而针对串行互连和并行互连难以同时满足车载应用市场的低延迟、低成本要求这一痛点,芯砺智能凭借独创的基于流水线的设计,成功打造出全自研的Chiplet D2D互连IP,兼有并行互连技术的高带宽、低延迟和串行互连技术的高可靠性、低成本优势。具体而言,芯砺智能的D2D互连技术是一种将芯片内部总线串行化的总线扩展接口,其传输的是经过串行化的总线流水线,省略了一系列复杂的打包、拆包协议和同步操作,并最大限度地保留了并行总线的流水线结构。尤其是面向车载领域,当前先进封装还未能完全符合车规要求,芯砺智能Chiplet D2D 互连IP不仅支持车规级传统封装,还具备低延迟且高性价比的互连优势,可以加速信号处理流程,提高系统的反应速度。
不过,成立仅2年的芯砺智能,在Chiplet车载应用独领风骚并非一蹴而就。早在2012年,Chiplet技术还未爆火时,芯砺智能的创始团队成员就意识到,因为成本太高、可靠性不佳,基于先进封装的Chiplet技术未来很难被拓展到服务器以外的其他领域,于是着手研究一种低成本、高性能的互连技术。适逢AIGC加速上车以及电子电气架构的集中式变革,汽车芯片算力迎来大爆发契机,尤其是中国率先成为全球电动化、智能化热土,芯砺智能得以大展身手。未来,芯砺智能将基于D2D互连,不断地从处理器到内存之间的整个数据链路实现自主创新,推出一系列有差异化的IP,从而保持在技术上的领先优势。可以说,抓住了天时地利人和,凭借创始团队的长期积淀和努力,以及对Chiplet车载应用需求的敏锐判断,芯砺智能已经赢得了智能化下半场的入场券和先发优势。不过,面向AIGC车载应用等带来的智能化下半场机遇,大算力需求只是部分,关键还在于综合异构集成算力的加持,例如常见的图形加速算力GPU或AI加速算力NPU。尤其是在汽车更迭周期不断缩短、品牌差异化和多样化竞争趋势下,车载芯片的综合异构集成算力呈指数型增长,对芯片的需求量也逐渐飙升。而随着AI技术与汽车行业的深度融合,包括BEV+Transformer在智能驾驶领域的运用,以及DMS/OMS、AIGC等在智能座舱的应用,对AI加速算力提出了更高要求,以往采用的架构显然不适用。例如,DSP+加速器架构,将整个系统放在一颗芯片上,硬件模块大多根据特定功能需求定制,具有特性算法的高效性,但DSP+加速器一般不开放而是采用黑盒方案,难以适应智能汽车的差异化需求。而GPU架构,此前专用于图形加速计算,后来逐渐进化出通用属性,具备并行计算的通用性,支持所有算子融合,能够高效地处理海量数据,但利用率低,难以满足AIGC车载应用的高效计算需求。相比之下,从AI芯片的核心NPU的角度出发,芯砺智能的GPGPU类似的NPU架构,综合了GPU架构和DSP+加速器架构优势,可以同时满足智能驾驶智能座舱算法网络适用性以及效率深度优化需求,兼具灵活性、高效性和通用性,支持AI技术的发展和迭代。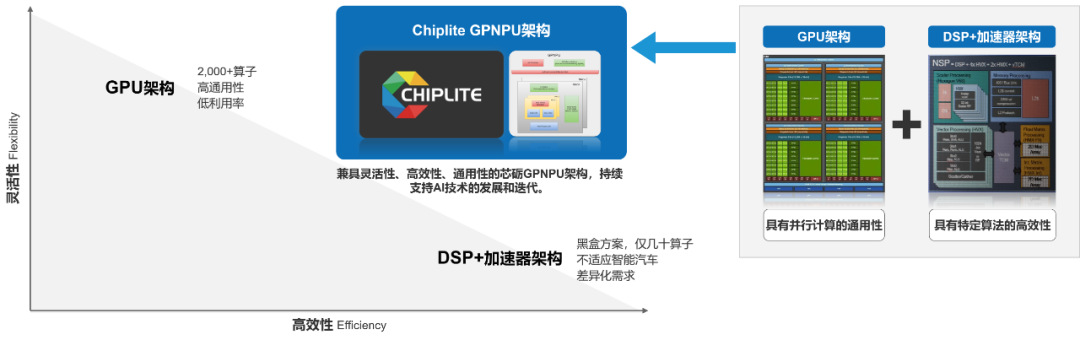
据悉,GPGPU并非一款具体芯片,而是一种概念,即利用图形加速器进行非图形渲染的高性能计算。前一个GP表示“通用目的”(General Purpose),后一个GP表示“图形处理”(Graphic Process),和U组合为GPU(图形处理器)。具体来看,依托Chiplet技术,以嵌入式高性能计算平台为设计基础,芯砺智能通过对NPU的快速迭代、CPU/GPU算力的灵活升级扩展,可实现不同CPU、GPU和NPU等算力单元的灵活组合与定制,满足智能汽车市场对车载芯片的差异化需求。可以说,无论是利用Chiplet解决AIGC车载应用算力痛点,还是自研灵活高效的NPU支持AI深度优化,足以看出芯砺智能做好了赢占汽车智能化下半场的准备。