获取高质量训练数据的主要难点在于企业往往不愿意、不能或者不敢分享他们的数据。作为一种隐私计算的新范式,「可控计算」让数据提供方能够控制自己的数据如何被使用,保障数据提供方的权益,有望推动大模型产业和更广泛的数据要素市场发展。
数据,作为决定机器学习模型性能的三大要素之一,正在成为制约大模型发展的瓶颈。正所谓「Garbage in, garbage out」[1],无论你的算法多么优秀,你的计算资源多么强大,模型的质量都直接取决于你用来训练模型的数据。随着各种开源大模型的涌现,数据的重要性进一步凸显,尤其是高质量的行业数据。彭博社基于开源的 GPT-3 框架打造金融大模型 BloombergGPT,证明了基于开源的大模型框架开发垂直行业大模型的可行性。事实上,面向垂直行业构建或定制闭源的轻量化大模型,也正是国内多数大模型创业公司所选择的路径。在这个赛道,高质量的垂直行业数据、基于专业知识的微调和对齐能力至关重要——BloombergGPT 基于彭博社积累了 40 多年的金融文档构建,训练语料库的 token 超过 7000 亿[2]。然而,获取高质量的数据并不容易。有研究指出,按照当前大模型吞噬数据的速率,高质量的公域语言数据,例如书籍、新闻报道、科学论文、维基百科等,将在 2026 年左右耗尽[3]。公开可用的中文高质量数据资源原本就相对较少,而国内的专业数据服务还在起步阶段,进行数据收集、清洗、标注和验证需要投入大量的人力和物力。据悉,国内某高校大模型团队,收集、清洗 3TB 高质量中文数据的成本,包括下载数据带宽、数据存储资源(未清洗的原始数据约为 100TB)、清洗数据的 CPU 资源成本总计约数十万元。随着大模型发展走向深度,要训练出满足产业需求、精度极高的垂直行业模型,一定需要更多的行业专业知识,甚至商业机密类型的私域数据。但是,出于隐私保护的要求,以及确权、收益划分存在的困难,企业往往不愿意、不能或者不敢分享他们的数据。有没有一种方案,既可以享受数据开放和共享的好处,又能保护数据的安全和隐私呢?隐私计算(Privacy-preserving Computation)能够在保证数据提供方不泄露原始数据的前提下,对数据进行分析、处理和使用,被视为促进数据要素流通和交易的关键技术[4],因此,将隐私计算用于保护大模型的数据安全,似乎成了一种自然的选择。隐私计算不是一种技术,而是一个技术体系。根据具体的实现,隐私计算主要分为以多方安全计算为代表的密码学路径、以可信执行环境为代表的机密计算路径,以及以联邦学习为代表的人工智能路径[5]。
不过,在实际应用中,隐私计算存在一些局限。例如,引入隐私计算 SDK 通常会对原有业务系统进行代码层面的修改[6]。如果是基于密码学的实现,加解密操作会让计算量呈几何级增长,同时密文计算需要更大的计算和存储资源以及通信负载[7]。此外,涉及超大规模数据量的大模型训练场景,现有的隐私计算方案还会遭遇一些新的问题。让我们首先看看联邦学习的困难。联邦学习的核心思想是「数据不动模型动」,这种去中心化的方式保证了敏感数据待在本地,无需暴露或传输。每个设备或服务器通过向中心服务器发送模型的更新,参与到训练过程中,而中心服务器则聚合并融合这些更新,从而改进全局模型[8]。然而,集中训练大模型已经是一件非常困难的事情,分布式的训练方法大大增加了系统的复杂性。我们还需要考虑模型在各个终端上训练时数据的异质性,以及如何安全地聚合所有设备的学习权重——对于大模型的训练,模型权重本身就是一项重要资产。此外,还必须防止攻击者从单个模型更新中推断出私有数据,而相应的防御措施会进一步增加训练开销。同态加密能够直接对加密数据进行计算,让数据「可用不可见」[9]。在处理或分析敏感数据并保证其机密性的场景中,同态加密是保护隐私的强大工具。这种技术不仅可以应用于大模型的训练,也能在保护用户输入(prompt)的机密性的同时进行推理。然而,相比于使用未加密数据进行大模型的训练和推理,使用加密数据要困难得多。同时,处理加密数据需要更多的计算,会指数级地增加处理时间,并进一步增加训练大模型已经非常高的算力需求。再来说说基于可信执行环境(TEE)的解决方案。大多 TEE 解决方案或产品都需要额外采购专门的设备,如多方安全计算节点、可信执行环境设备、密码加速卡等,无法适配已有的计算、存储资源,使得这种解决方案对许多中小企业来说并不现实。此外,目前 TEE 方案主要是基于 CPU 进行的,而大模型训练严重依靠 GPU。现阶段支持隐私计算的 GPU 方案还不成熟,反而造成了额外的风险[10]。总的来说,在多方协作计算的场景下,很多时候要求原始数据物理意义上的「不可见」并不合理。此外,由于加密过程给数据添加了噪声,在加密数据上进行训练或推理,也会造成模型性能损失和降低模型准确性。现有的隐私计算方案无论是性能和还是在 GPU 支持方面,都无法很好地适用于大模型训练场景,也阻碍了拥有高质量数据资源的企业和机构开放和共享信息,参与到大模型产业中来。「当我们把大模型产业看做从数据到应用的一个链条,会发现这个链条实际上是各种数据(包括原始数据,也包括以参数形式存在于模型中的数据)在不同主体间的流通链,而这个产业的商业模式则应该构建于这些流通的数据(或模型)是可以被交易的资产基础之上。」熠智科技的 CEO 汤载阳博士表示。「数据要素的流通涉及多个主体,而产业链的源头一定是数据提供方。也就是说,所有的业务其实都是由数据提供方来发起,只有数据提供方授权,交易才可能进行,所以应该优先保证数据提供方的权益。」目前市场上主流的隐私保护解决方案,如多方安全计算、可信执行环境和联邦学习,都聚焦数据使用方如何处理数据,汤载阳认为,我们需要从数据提供者的角度出发去看问题。熠智科技成立于 2019 年,定位于面向数据合作的隐私保护解决方案提供商。2021 年,公司入选了由中国信息通信研究院发起的「数据安全推进计划」(Data Security Initiative,DSI)首批参与单位,并被 DSI 认证为 9 家代表性隐私计算企业厂商之一。2022 年,熠智科技正式成为国内首个国际化自主可控隐私计算开源社区——开放群岛(Open Islands)开源社区成员单位,共同推动数据要素流通关键基础设施建设。针对目前大模型训练的数据困境,以及更广泛的数据要素流通问题,熠智科技从实践出发,提出了一种新的隐私计算解决方案——可控计算。「可控计算的核心关注点是以保护隐私的方式来发现和共享信息。我们解决的问题是在训练的过程中保证所用数据的安全,以及训练出来的模型不被恶意窃取。」汤载阳说。具体说,可控计算要求数据使用方在数据提供方定义的安全域中对数据进行加工和处理。
安全域在数据流通场景中的示例
安全域是一个逻辑上的概念,指由相应的密钥和加密算法保护的存储、计算单元。安全域由数据提供方定义和约束,但相应的存储、计算资源并不由数据提供方提供。物理上,安全域在数据使用方,但是由数据提供方所控制。除了原始数据,加工、处理后的中间数据和结果数据也在相同的安全域中。
在安全域中,数据可以是密文(不可见),也可以是明文(可见),在明文情况下,由于数据可见的范围是受控的,因此确保了数据在使用过程中的安全。复杂的密文计算导致的性能下降是限制隐私计算应用范围的一个重要因素,通过强调数据的可控,而不是一味追求不可见,可控计算解决了传统隐私计算方案对原有业务的侵入性,因此非常适合需要处理超大规模数据的大模型训练场景。企业可以选择将自己的数据存放在多个不同的安全域中,并给这些安全域设定不同的安全等级、使用权限或白名单。对于分布式应用,也可以在多个计算机节点乃至芯片上设定安全域。「安全域是可以串起来的,在数据流通的各个环节,数据提供方可以定义多个不同的安全域,让自己的数据只在这些安全域之间互相流转,最终这些串联的安全域就构建起了一个数据的网络。在这个网络上面,数据是可控的,对数据的流转、分析、处理等也可度量、可监管,数据的流通也可以做相应的变现。」汤载阳解释说。基于可控计算的思想,熠智科技推出了「DataVault」。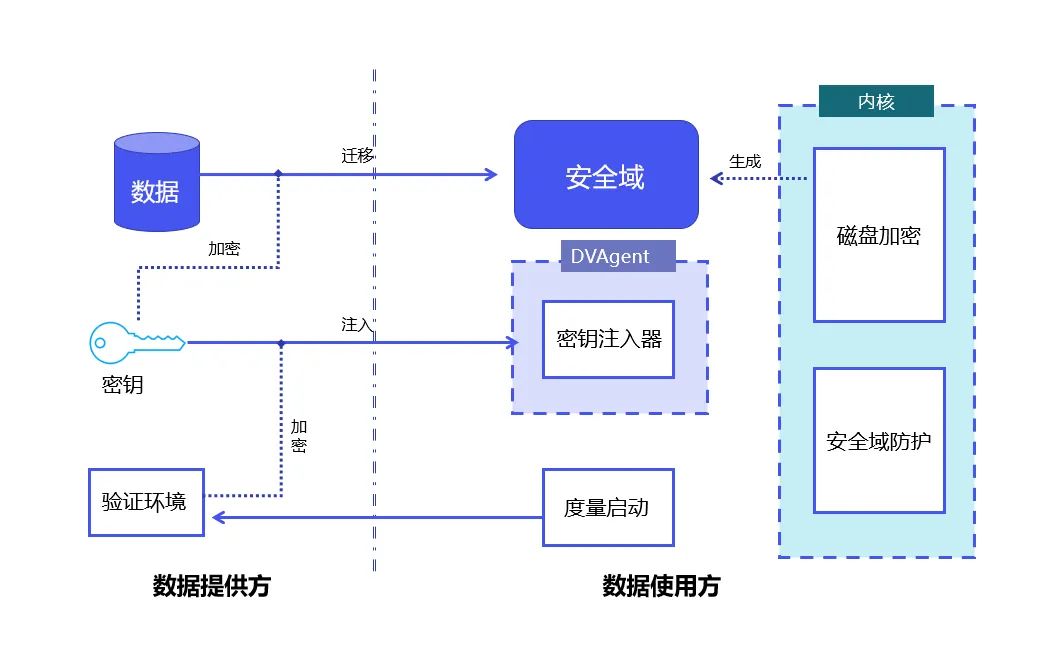
DataVault 原理:结合 Linux 度量启动和 Linux 全盘加密技术,实现数据在安全域内的可控、防护。
DataVault 将可信平台模块 TPM(Trusted Platform Module,其核心是提供基于硬件的安全相关功能)做为信任根,保护了系统的完整性;使用 Linux 安全模块 LSM( Linux Security Modules,Linux 内核中用于支持各种计算机安全模型的框架,其与任何单独的安全实现无关)技术,使安全域内的数据只在可控范围内使用。在此基础上,DataVault 使用 Linux 提供的全盘加密技术将数据置于安全域内,熠智科技自研了完整的密钥分发以及签名授权等密码协议,并做了大量工程上的优化,进一步保证了数据的可控。DataVault 支持多种专用加速卡,包括不同的 CPU、GPU、FPGA 等硬件,也支持多种数据处理框架、模型训练框架,且二进制兼容。更重要的是,它有着远低于其他隐私计算解决方案的性能损失,在大部分应用中,相比原生系统(即不用任何隐私计算技术),整体性能损失不超过 5%。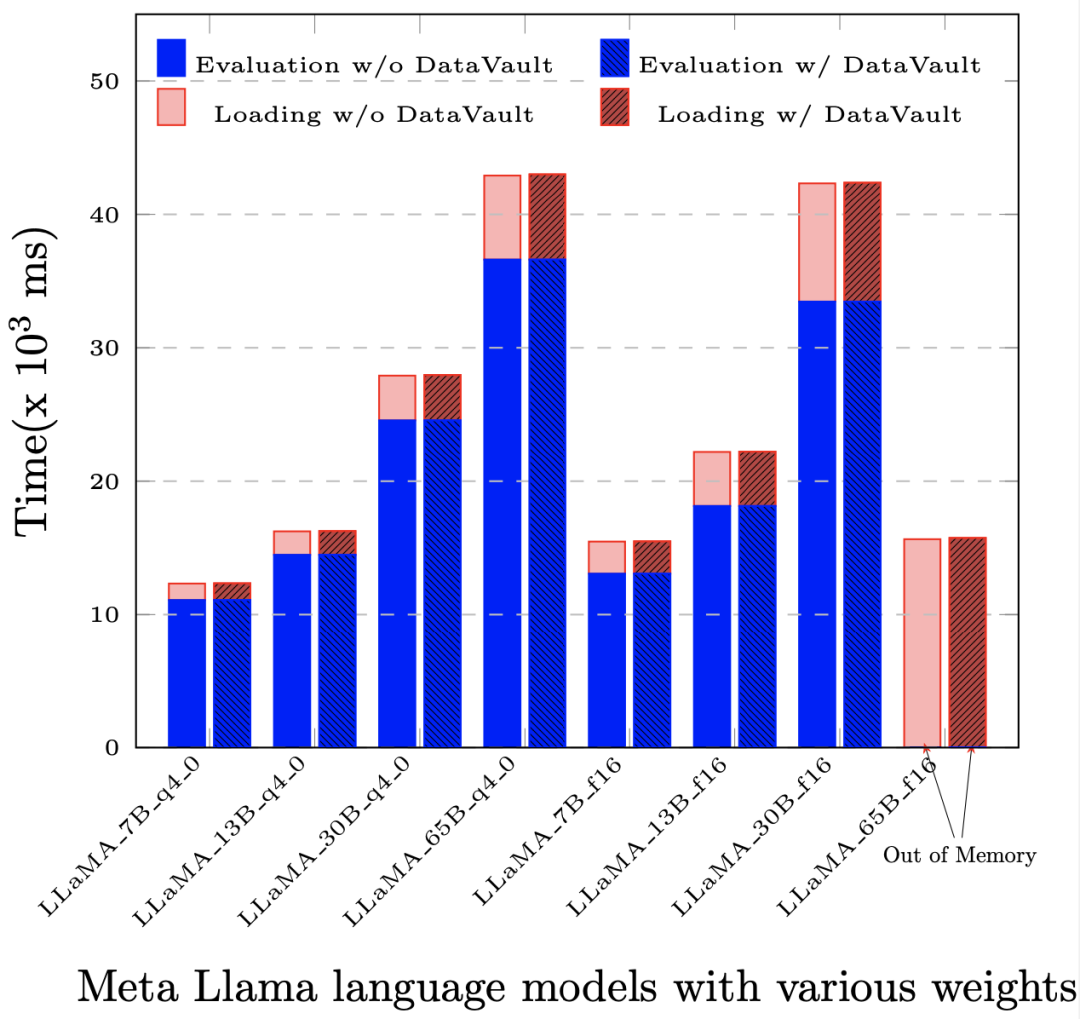
部署 DataVault 后,基于 LLaMA-65B 的评估(Evaluation)和提示评估(Prompt Evaluation)环节中,性能损失小于 1‰。
现在,熠智科技已与国家超级计算中心达成合作,在超算平台上部署面向 AI 应用的隐私保护高性能计算平台。基于 DataVault,算力使用方可以在计算平台上设定安全域,确保数据从存储节点转移到计算节点的全过程都只能在安全域之间移动,不离开设定的范围。除了确保数据在模型训练中的可控,基于 DataVault 解决方案,训练好的大模型本身作为一种数据资产,也可以得到保护并被安全地交易。目前,对于那些希望在本地部署大模型的企业,例如金融、医疗等高敏感数据机构,苦于缺少在本地运行大模型的基础设施,包括训练大模型的高成本高性能硬件,以及部署大模型后续的运维经验。而对于构建行业大模型的企业,他们则担心如果直接将模型交付给客户,模型本身和模型参数背后积累的行业数据和专业知识存在被二次贩卖的可能。作为对垂直行业大模型落地的一种探索,熠智科技也正与粤港澳大湾区数字经济研究院(IDEA 研究院)合作,双方联合打造了具有模型安全保护功能的大模型一体机。这种一体机内置了若干垂直行业大模型,配备大模型训推所需的基础算力资源,可以满足客户开箱即用的需求,其中熠智的可控计算组件 DataVault 可以确保这些内置模型仅在获得授权的情况下被使用,模型以及所有中间数据无法被外部环境窃取。作为一种新的隐私计算范式,熠智科技希望可控计算能为大模型行业和数据要素流通带来改变。「DataVault 只是一个轻量级的实现方案。随着技术和需求的变化,我们会持续更新,在数据要素流通市场有更多的尝试和贡献,也欢迎更多行业伙伴加入进来,共建可控计算社区。」汤载阳说。参考资料
[1] Rose, L. T., & Fischer, K. W. (2011). Garbage in, garbage out: Having useful data is everything. Measurement: Interdisciplinary Research & Perspective, 9(4), 222-226.
[2] 彭博推出BloombergGPT——专为金融行业从头打造的500亿参数大语言模型, https://www.bloombergchina.com/press/bloomberggpt-50-billion-parameter-llm-tuned-finance/
[3] Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning, https://doi.org/10.48550/arXiv.2211.04325
[4] 闫树, and 吕艾临. "隐私计算发展综述." 信息通信技术与政策 47, no. 6 (2021): 1
[5] 李凤华, 李晖, 牛犇, and 邱卫东. "隐私计算的学术内涵与研究趋势." 网络与信息安全学报 8, no. 6 (2022): 1-8.
[6]贾轩, 白玉真, and 马智华. "隐私计算应用场景综述." 信息通信技术与政策 48, no. 5 (2022): 45.
[7] 谭作文, and 张连福. "机器学习隐私保护研究综述." 软件学报 31, no. 7 (2020): 2127-2156.
[8] Konečný, Jakub, H. Brendan McMahan, Felix X. Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon. "Federated learning: Strategies for improving communication efficiency." arXiv preprint arXiv:1610.05492 (2016).
[9] Lee, Joon-Woo, HyungChul Kang, Yongwoo Lee, Woosuk Choi, Jieun Eom, Maxim Deryabin, Eunsang Lee, et al. "Privacy-preserving machine learning with fully homomorphic encryption for deep neural network." IEEE Access 10 (2022): 30039-30054.
[10] Mai, Haohui, Jiacheng Zhao, Hongren Zheng, Yiyang Zhao, Zibin Liu, Mingyu Gao, Cong Wang, Huimin Cui, Xiaobing Feng, and Christos Kozyrakis. "Honeycomb: Secure and Efficient {GPU} Executions via Static Validation." In 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), pp. 155-172. 2023.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]