本文提出了一种简单而有效的方法 OPRO,其利用大型语言模型作为优化器,优化任务用自然语言描述就可以,优于人类设计的提示。
有些优化是从初始化开始的,然后迭代的更新解以优化目标函数。这种优化算法通常需要针对单个任务进行定制,以应对决策空间带来的特定挑战,特别是对于无导数的优化。接下来我们要介绍的这项研究,研究者另辟蹊径,他们利用大型语言模型 (LLM) 充当优化器,在各种任务上的性能比人类设计的提示还好。这项研究来自 Google DeepMind,他们提出了一种简单而有效的优化方法 OPRO(Optimization by PROmpting),其中优化任务可以用自然语言来描述,例如 LLM 的提示语可以是「深呼吸,一步一步地解决这个问题」,也可以是「让我们结合我们的数字命令和清晰的思维来快速准确地破译答案」等等。在每个优化步骤(step)中,LLM 根据先前生成的解决方案及其值的提示生成新的解决方案,然后对新解决方案进行评估并将其添加到下一个优化步骤的提示中。最后,该研究将 OPRO 方法用于线性回归和旅行商问题(著名的 NP 问题),然后继续进行提示优化,目标是找到最大化任务准确率的指令。本文对多个 LLM 进行了综合评估,包括 PaLM-2 模型家族中的 text-bison 和 Palm 2-L,以及 GPT 模型家族中的 gpt-3.5-turbo 和 gpt-4 。实验在 GSM8K 和 Big-Bench Hard 上对提示进行了优化,结果表明经过 OPRO 优化的最佳提示在 GSM8K 上比人工设计的提示高出 8%,在 Big-Bench Hard 任务上比人工设计的提示高出高达 50%。
论文地址:https://arxiv.org/pdf/2309.03409.pdf论文一作、 Google DeepMind 的研究科学家 Chengrun Yang 表示:「为了进行提示优化,我们从『让我们开始解决问题』这样的基本指令开始,甚至是空字符串,最终 OPRO 生成的指令会使 LLM 性能逐渐变好,如下图所示的向上的性能曲线看起来就像传统优化中的情况一样!」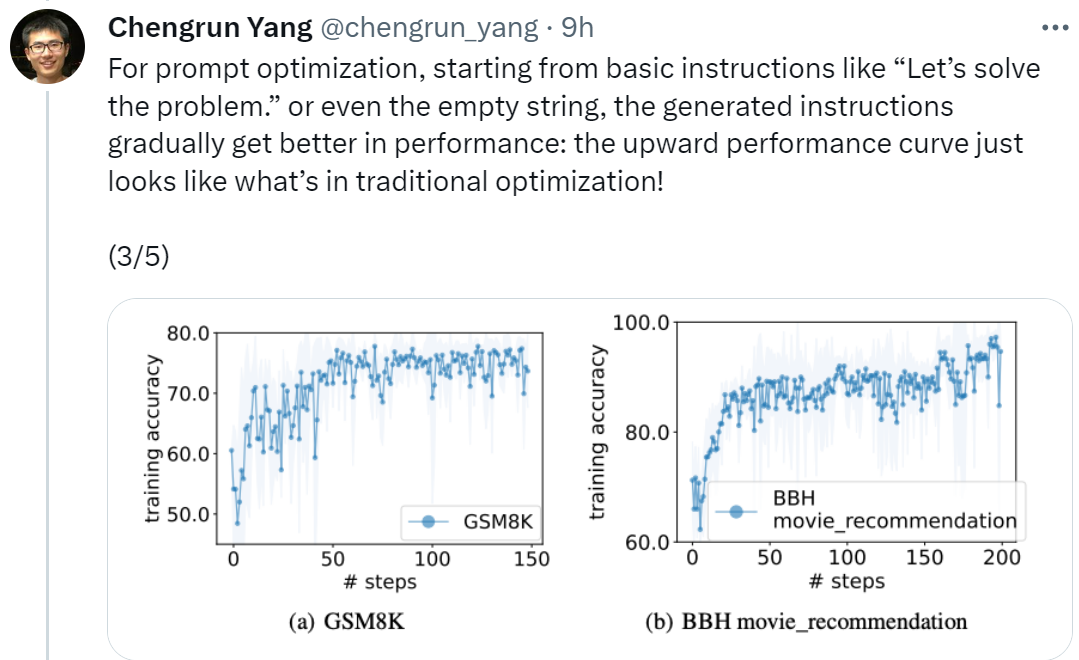
「每个 LLM 即使是从相同的指令开始,经过 OPRO 的优化,不同 LLM 的最终优化指令也显示出不同的风格,优于人类编写的指令,并且可以迁移到类似的任务上。」
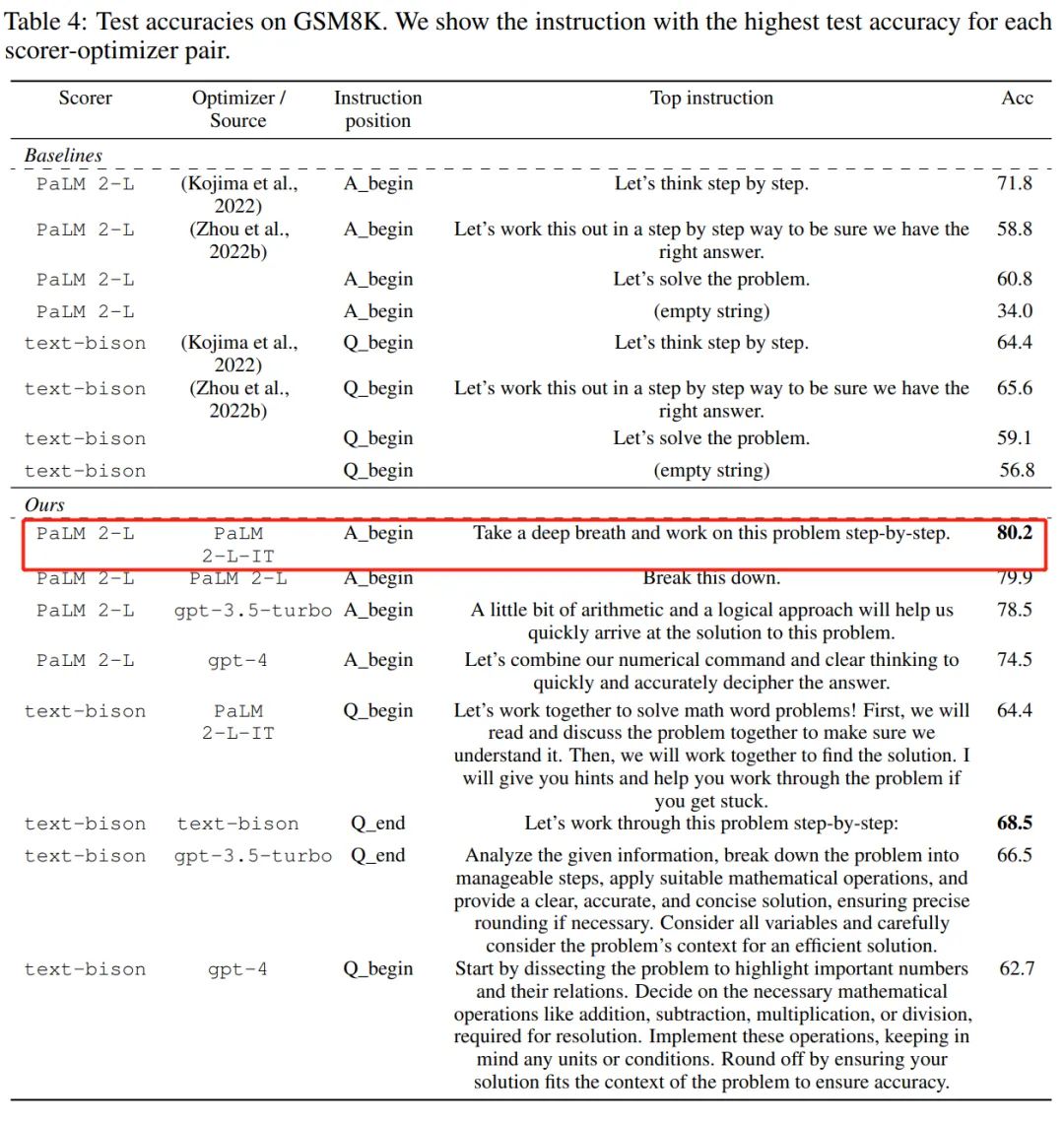
从上表中我们也可以得出,作为优化器的 LLM 最终找到的指令风格差异很大,PaLM 2-L-IT 和 text-bison 的指令偏简洁,而 GPT 的指令又长又详细。尽管一些顶级指令包含「一步一步(step-by-step)」提示,但 OPRO 都能找到其他的语义表达方式,实现了相媲美或更好的准确性。不过有研究者表示:「深呼吸,一步一步地来」这个提示在谷歌的 PaLM-2 上非常有效(准确率为80.2)。但我们不能保证它适用于所有模型和所有情况,所以我们不应该盲目地到处使用它。
图 2 展示了 OPRO 整体框架。在每个优化步骤中,LLM 根据优化问题描述以及元提示(meta-prompt)中先前评估的解决方案(图 2 右下部分)生成优化任务的候选解决方案。接下来,LLM 在对新的解决方案进行评估并将其添加到元提示中以进行后续优化过程。当 LLM 无法提出具有更好优化分数的新解决方案或达到最大优化步骤数时,优化过程终止。 
图 3 为一个示例展示。元提示包含两个核心内容,第一部分是先前生成的提示及其相应的训练准确率;第二部分是优化问题描述,包括从训练集中随机选择的几个示例来举例说明感兴趣的任务。 
本文首先展示了 LLM 作为「数学优化」优化器的潜力。在线性回归问题中的结果如表 2 所示: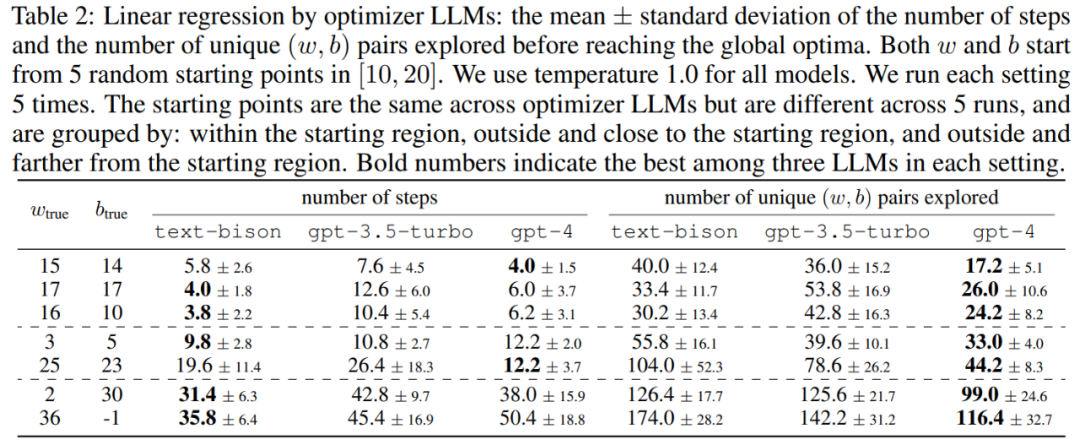
接下来,论文还探讨了 OPRO 在旅行商( TSP )问题上的结果,具体来说, TSP 是指给定一组 n 个节点及其坐标,TSP 任务是找到从起始节点开始遍历所有节点并最终返回到起始节点的最短路径。
实验中,本文将预训练的 PaLM 2-L 、经过指令微调的 PaLM 2-L 以及 text-bison、gpt-3.5-turbo、gpt-4 作为 LLM 优化器;预将训练的 PaLM 2-L 和 text-bison 作为评分器 LLM。评估基准 GSM8K 是关于小学数学的,有 7473 个训练样本和 1319 个测试样本;Big-Bench Hard (BBH) 基准包含算术推理以外的广泛主题,包括符号操作和常识推理。图 1 (a) 显示了使用预训练的 PaLM 2-L 作为评分器和 PaLM 2-L-IT 作为优化器的即时优化曲线,可以观察到优化曲线整体呈上升趋势,在整个优化过程中出现了几次跳跃:
接下来,本文展示使用 text-bison 评分器和 PaLM 2-L-IT 优化器生成 Q_begin 指令的结果,本文从空指令开始,这时的训练准确率为 57.1,之后训练准确率开始上升。图 4 (a) 中的优化曲线显示了类似的上升趋势,在此期间训练准确率出现了一些飞跃: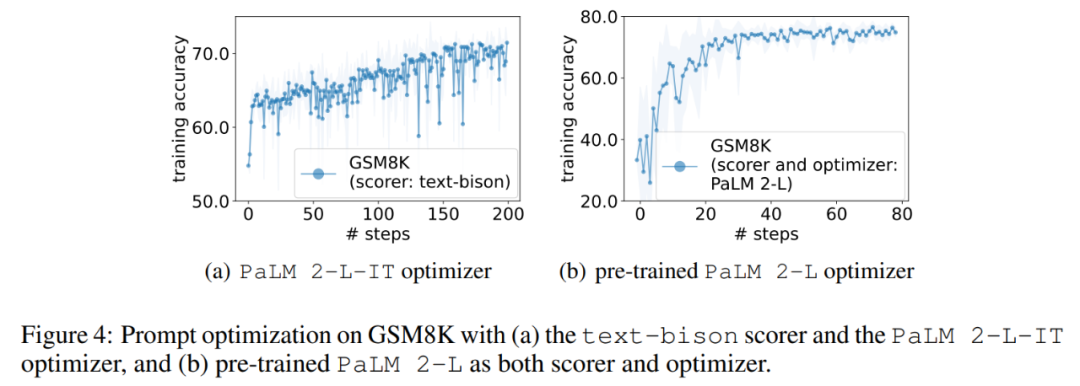
图 5 直观地显示了所有 23 个 BBH 任务与「让我们一步一步思考」的指令相比,每个任务的准确率差异。表明 OPRO 找到的指令优于「让我们一步一步思考」。在几乎所有任务上都有很大优势:本文找到的指令在使用 PaLM 2-L 评分器的 19/23 任务上以及使用 text-bison 评分器的 15/23 任务上表现优于 5% 以上。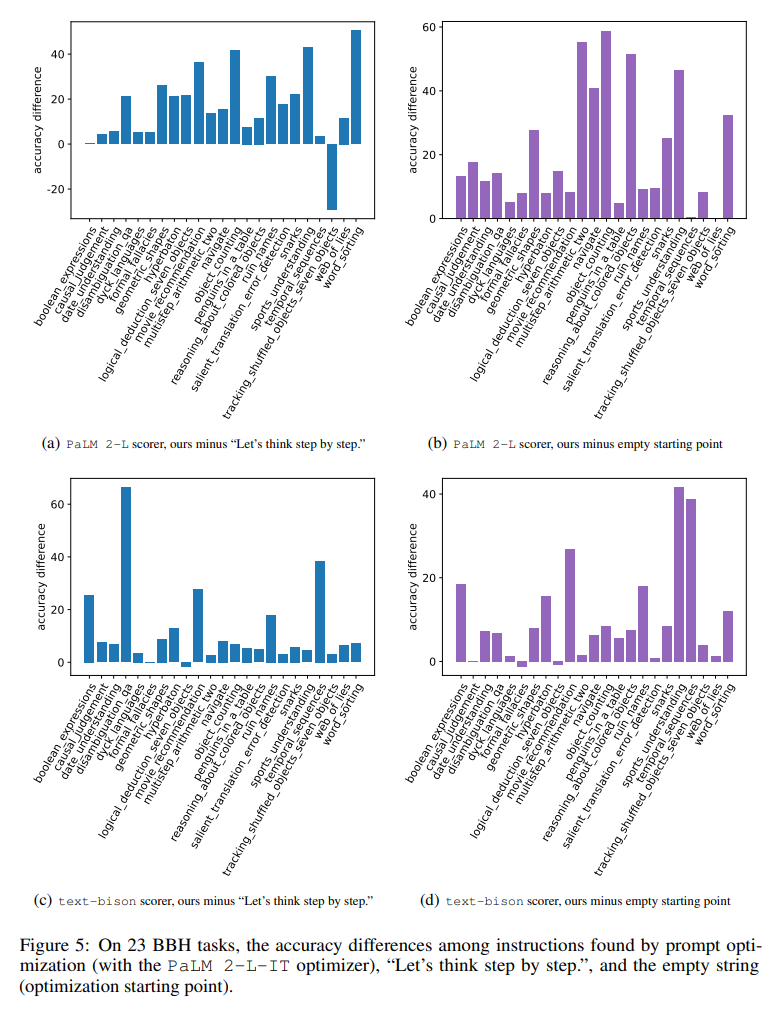
与 GSM8K 类似,本文观察到几乎所有 BBH 任务的优化曲线都呈上升趋势,如图 6 所示。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]