【新智元导读】这个开源工具,居然能用GPT-4代替人类去标注数据,效率比人类高了100倍,但成本只有1/7。
大模型满天飞的时代,AI行业最缺的是什么?毫无疑问一定是算(xian)力(ka)。老黄作为AI掘金者唯一的「铲子供应商」,早已赚得盆满钵满。除了GPU,还有什么是训练一个高效的大模型必不可少且同样难以获取的资源?高质量的数据。OpenAI正是借助基于人类标注的数据,才一举从众多大模型企业中脱颖而出,让ChatGPT成为了大模型竞争中阶段性的胜利者。但同时,OpenAI也因为使用非洲廉价的人工进行数据标注,被各种媒体口诛笔伐。
而那些参与数据标注的工人们,也因为长期暴露在有毒内容中,受到了不可逆的心理创伤。
卫报报道肯尼亚劳工指责数据标注工作给自己带来了不可逆的心理创伤总之,对于数据标注,一定需要找到一个新的方法,才能避免大量使用人工标注带来的包括道德风险在内的其他潜在麻烦。所以,包括谷歌,Anthropic在内的AI巨头和大型独角兽,都在进行数据标注自动化的探索。
谷歌最近的研究,开发了一个和人类标注能力相近的AI标注工具
Anthropic采用了Constitutional AI来处理数据,也获得了很好的对齐效果除了巨头们的尝试之外,最近,一家初创公司refuel,也上线了一个AI标注数据的开源处理工具:Autolabel。Autolabel:用AI标注数据,效率最高提升100倍
这个工具可以让有数据处理需求的用户,使用市面上主流的LLM(ChatGPT,Claude等)来对自己的数据集进行标注。refuel称,用自动化的方式标注数据,相比于人工标注,效率最高可以提高100倍,而成本只有人工成本的1/7!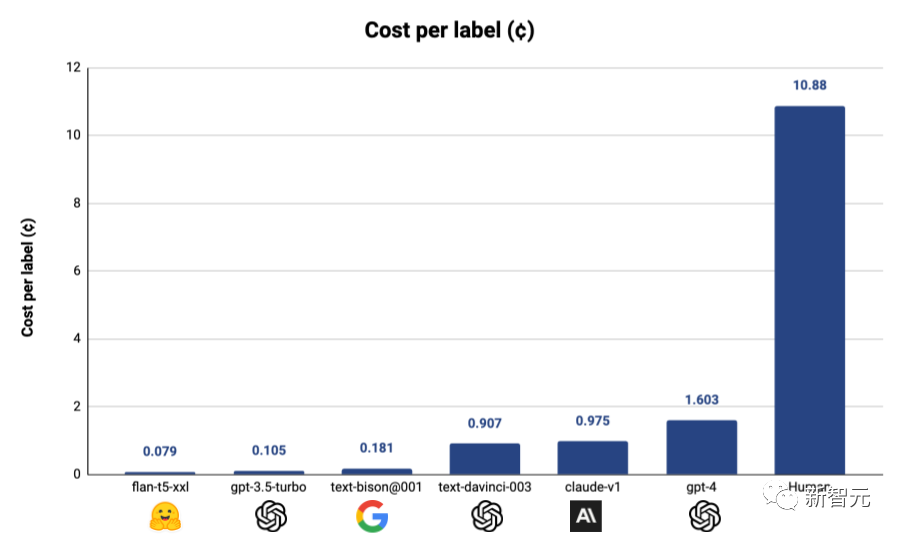
就算按照使用成本最高的GPT-4来算,采用Autolabel标注的成本只有使用人工标注的1/7,而如果使用其他更便宜的模型,成本还能进一步降低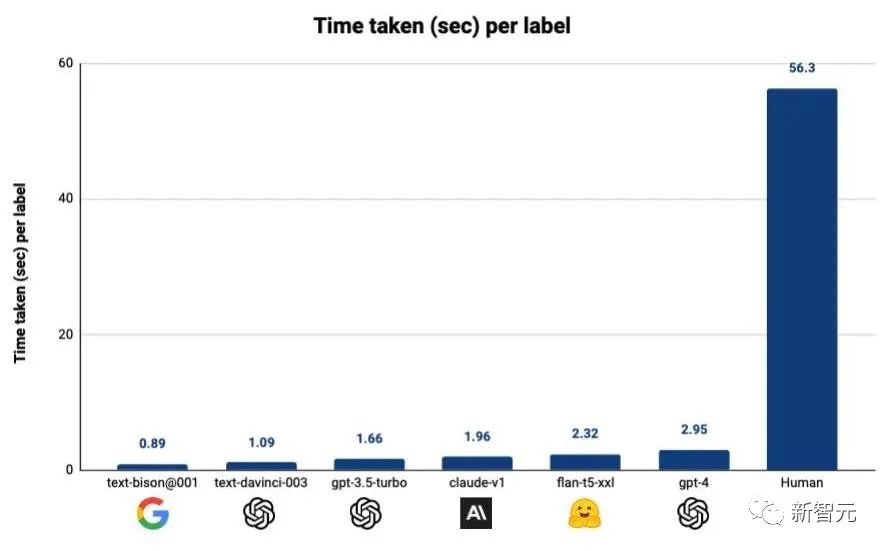
采用Autolabel+LLM的标注方式之后,标注效率更是大幅提升对于LLM标注质量的评估,Autolabel的开发者创立了一个基准测试,通过将不同的LLM的标注结果和基准测试中不同数据集中收纳的标准答案向比对,就能评估各个模型标注数据的质量。当Autolabel采用GPT-4进行标注时,获得了最高的准确率——88.4%,超过了人类标注结果的准确率86.2%。而且其他比GPT-4便宜得多的模型的标注准确率,相比GPT-4来说也不算低。开发者称,在比较简单的标注任务中采用便宜的模型,在困难的任务中采用GPT-4,将可以大大节省标注成本,同时几乎不影响标注的准确率。Autolabel支持对自然语言处理项目进行分类,命名实体识别,实体匹配和问答。支持主流的所有LLM提供商:OpenAI、Anthropic 和 Google Palm 等,并通过HuggingFace为开源和私有模型提供支持。用户可以尝试不同的提示策略,例如少样本和思维链提示。只要简单更新配置文件即可轻松估计标签置信度。Autolabel免除了编写复杂的指南,无尽地等待外部团队来提供数据支持的麻烦,用户能够在几分钟内开始标注数据。可以支持使用本地部署的私有模型在本地处理数据,所以对于数据隐私敏感度很高的用户来说,Autolabel提供了成本和门槛都很低的数据标注途径。
所以,不论是律所想要通过GPT-4来对法律文档进行分类,还是保险公司想要用私有模型对敏感的客户医疗数据进行分类或者筛查,都可以使用Autolabel进行高效地处理。Autolabel提供了一个简单的案例来展示了如何使用它进行评论有害性的标注过程。假设用户是一个社交媒体的内容审核团队,需要训练分类器来确定用户评论是否有毒。如果没有Autolabel,用户需要首先收集几千个示例,并由一组人工注释者对它们进行标注,可能需要几周的时间——熟悉标注方针,从小数据集到大数据集进行几次迭代,等等。而如果使用Autolabe可以在分钟内就对这个数据集进行标注。Autolabel安装
pip install 'refuel-autolabel[openai]'
将使用一个名为Civil Comments的数据集,该数据集可通过Autolabel获得。你可以在本地下载它,只需运行:from autolabel import get_dataget_data('civil_comments')
Downloading seed example dataset to "seed.csv"...100% [..............................................................................] 65757 / 65757Downloading test dataset to "test.csv"...100% [............................................................................] 610663 / 610663

首先,指定一个标签配置(参见下面的config对象)并创建一个LabelingAgent。接下来,通过运行agent.plan,使用config中指定的LLM对的数据集进行一次标注config = { "task_name": "ToxicCommentClassification", "task_type": "classification", "dataset": { "label_column": "label", }, "model": { "provider": "openai", "name": "gpt-3.5-turbo" }, "prompt": { "task_guidelines": "Does the provided comment contain 'toxic' language? Say toxic or not toxic.", "labels": [ "toxic", "not toxic" ], "example_template": "Input: {example}\nOutput: {label}" }}
如果要创建自定义配置,可以使用CLI或编写自己的配置。
from autolabel import LabelingAgent, AutolabelDataset
agent = LabelingAgent(config)ds = AutolabelDataset('test.csv', config = config)agent.plan(ds)
┌──────────────────────────┬─────────┐│ Total Estimated Cost │ $4.4442 ││ Number of Examples │ 2000 ││ Average cost per example │ $0.0022 │└──────────────────────────┴─────────┘───────────────────────────────────────────────── Prompt Example ──────────────────────────────────────────────────Does the provided comment contain 'toxic' language? Say toxic or not toxic.
You will return the answer with just one element: "the correct label"
Now I want you to label the following example:Input: [ Integrity means that you pay your debts.]. Does this apply to President Trump too?Output:
最后,进行数据标注:
ds = agent.run(ds, max_items=100)
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓┃ support ┃ threshold ┃ accuracy ┃ completion_rate ┃┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩│ 100 │ -inf │ 0.54 │ 1.0 │└─────────┴───────────┴──────────┴─────────────────┘
输出结果为54%的准确率不是很好,进一步改进的具体方法可以访问以下链接查看:
https://docs.refuel.ai/guide/overview/tutorial-classification/
在对Autolabel的基准测试中,包含了以下数据集: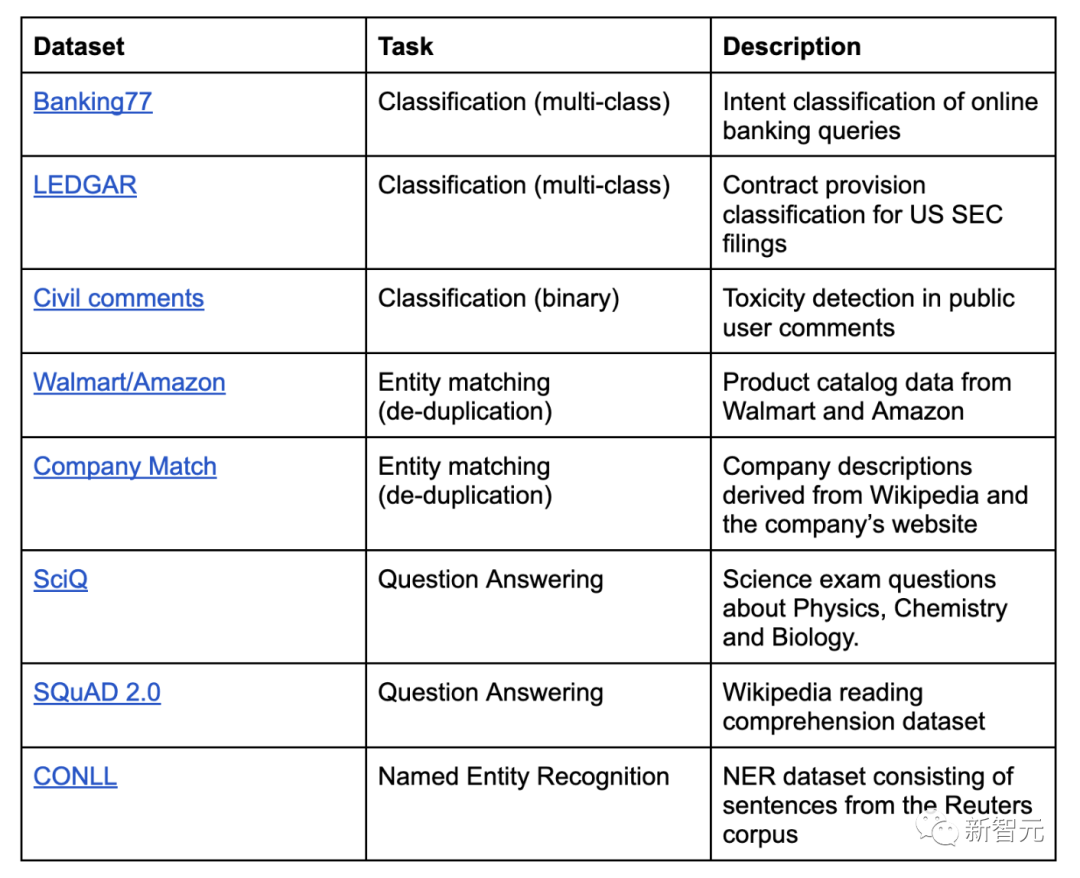

首先是标签质量,即生成的标签与真实标签之间的一致性;其次是周转时间,即以秒为单位时,生成标签所花费的时间;对于每个数据集,研究人员都将其拆分为种子集和测试集两部分。种子集包含200个示例,是从训练分区中随机采样构建的,用于置信度校准和一些少量的提示任务中。测试集包含2000个示例,采用了与种子集相同的构建方法,用于运行评估和报告所有基准测试的结果。在人工标注方面,研究团队从常用的数据标注第三方平台聘请了数据标注员,每个数据集都配有多个数据标注员。研究人员为数据标注员提供了标注指南,要求他们对种子集进行标注。然后对标注过的种子集进行评估,为数据标注员提供该数据集的基准真相作为参考,并要求他们检查自己的错误。随后,为数据标注员解释说明他们遇到的标签指南问题,最后对测试集进行标注。结果
标签质量衡量的是生成的标签(由人类或LLM标注者生成)与数据集中提供的基准真相的吻合程度。对于SQuAD数据集,研究人员用生成标签与基准真相之间的F1分数来衡量一致性,F1是问题解答的常用指标。对于SQuAD以外的数据集,研究人员用生成标签与基准真相之间的精确匹配来衡量一致性。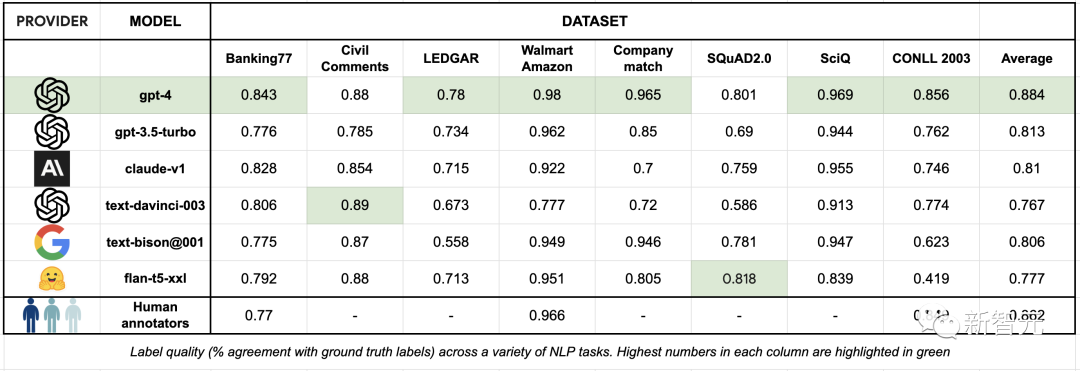
表3:各种NLP任务中的标签质量(与基准真相的一致率),每列中的最高数字以绿色标出可以看到,与熟练的人工数据标注员相比,最先进的LLM已经可以在相同甚至更好的水平上标注文本数据集,并且做到开箱即用,大大简化了繁琐的数据标注流程。GPT-4在一系列数据集中的标签质量都优于人类数据标注员。其他几个LLM的表现也在80%左右,但调用API的价格仅为GPT-4的十分之一。但由于LLM是在大量数据集上训练出来的,所以在评估LLM的过程中存在着数据泄露的可能。研究人员对此进行了例如集合的额外改进,可以将表现最好的的LLM(GPT-4、PaLM-2)与基准真相的一致性从89%提高到95%以上。对LLM最大的诟病之一就是幻觉。因此,当务之急是用一种与标签正确的可能性相关的方式来评估标签的质量。为了估计标签置信度,研究人员将LLM输出的token级日志概率平均化,而这种自我评估方法在各种预测任务中都很有效。对于提供对数概率的LLM(text-davinci-003),研究人员使用这些概率来估计置信度。对于其他LLM,则使用FLAN T5 XXL模型进行置信度估计。标签生成后,查询FLAN T5 XXL模型以获得生成的输出标注的概率分布,但前提是输入的提示信息与用于标签的信息相同。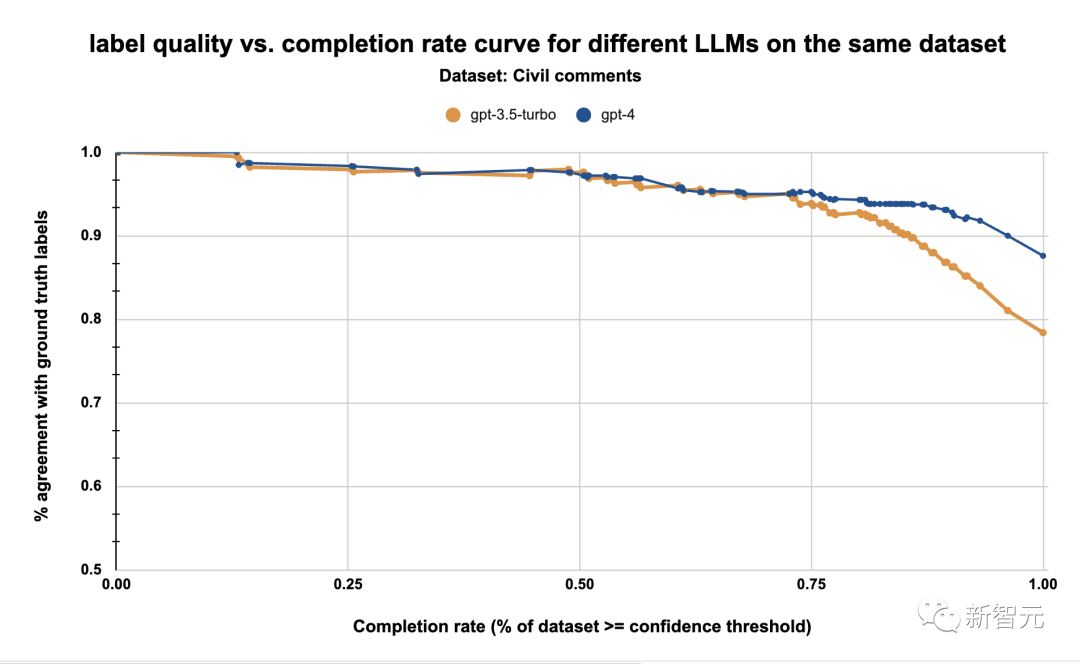
表4:同一数据集上gpt-3.5-turbo和gpt-4的标签质量与完成率在校准步骤中,研究人员利用估计置信度来了解标签质量和完成率之间的权衡。即研究人员为LLM确定了一个工作点,并拒绝所有低于该工作点阈值的标签。例如,上图显示,在95%的质量阈值下,我们可以使用GPT-4标注约77%的数据集。添加这一步的原因是token级日志概率在校准方面的效果不佳,如GPT-4技术报告中所强调的那样: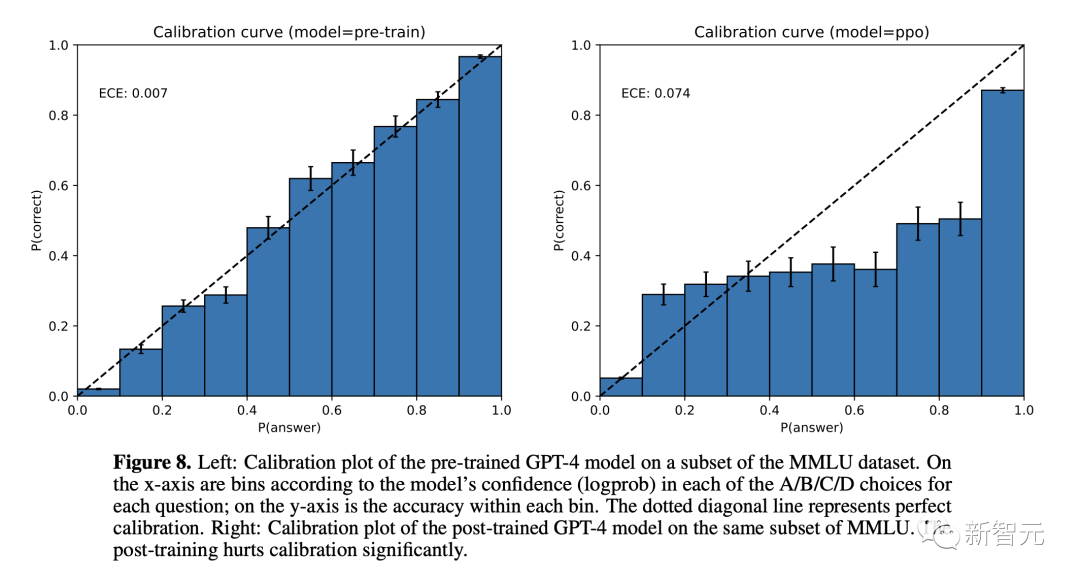
GPT-4模型的校准图:比较预训练和后RLHF版本的置信度和准确性使用上述置信度估算方法,并将置信度阈值设定为95%的标签质量(相比之下,人类标注者的标签质量为86%),得到了以下数据集和LLM的完成率: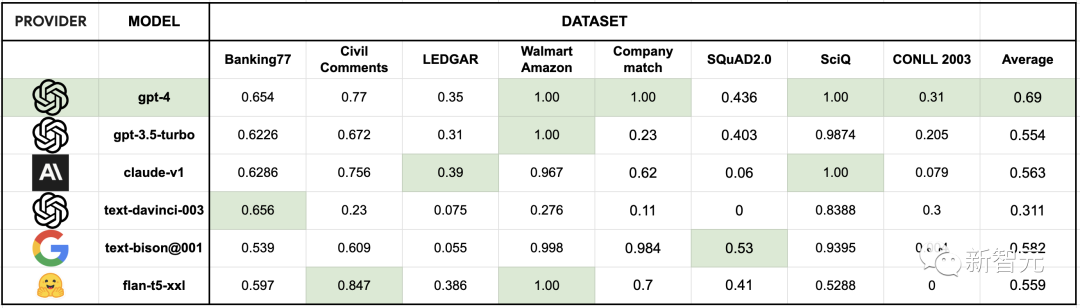
相比之下,人类标注者与基准真相的一致性为86.6%。从上图可以看到在所有数据集中,GPT-4的平均完成率最高,在8个数据集中,有3个数据集的标注质量超过了这一质量阈值。而其他多个模型(如text-bison@001、gpt-3.5-turbo、claude-v1和flan-t5-xxl)也实现了很好的性能:平均至少成功自动标注了50%的数据,但价格却只有GPT-4 API成本的1/10以下。
在接下来的几个月中,开发者承诺将向Autolabel添加大量新功能:https://www.refuel.ai/blog-posts/introducing-autolabel
