
“一波深度学习浪潮、七次世界冠军、两次转场与追随......” 他们不仅乘上了 AI 的浪潮,更创造了浪潮本身。
2007 年,颜水成飞赴南洋,第一次踏上新加坡的土地,走进新加坡国立大学(NUS)的校园。彼时,他将从美国伊利诺伊大学厄巴纳-香槟分校(UIUC)结束博士后生涯,与导师黄煦涛(Thomas Huang)教授辞别,进入找教职的阶段。1995 年,颜水成考入北京大学数学系后本硕博连读,博士期间一直在微软亚洲研究院(MSRA)实习,由时任副院长的张宏江博士指导。他对计算机视觉和多媒体分析十分痴迷,毕业后先去往香港中文大学多媒体实验室(MM Lab)跟随后来的商汤创始人汤晓鸥教授做博士后研究,一年半之后又赴美国伊利诺伊大学厄巴纳-香槟分校(UIUC),师从华人视觉鼻祖黄煦涛(Thomas Huang)教授做博士后。在黄煦涛的建议下,他在找教职时,将目标瞄准了亚洲的高校,先后面试了 NTU 与 NUS 两所新加坡大学。颜水成在新加坡待了一个星期,给自己充分的时间来考虑最终去向。最后要离开的前一天,他去到 NUS 的校园里,走走停停,来到未来办公室旁边的一处山坡,上面立着一棵枝繁叶茂的大树。颜水成就站在那棵树下,俯瞰着远处开阔的城市,感叹着“这个地方真是太美了”,便定下了来 NUS 的想法。那时的他没有想到,后来在 NUS 扎根下来,自己也长成了一棵枝繁叶茂的“大树”,他与学生们之间的故事也从这里展开。颜水成
三十出头的颜水成意气风发,很快着手组建了机器学习与视觉实验室(NUS-LV Lab),并定下了一个颇有野心的目标:
让全世界都知道新加坡NUS-LV Lab是一个世界一流的计算机视觉研究团队!那几年,整个实验室都处于全力向前高速奔跑的状态。颜水成对自己和对学生都要求极高,每周一对一的交流从不间断,学生第一篇稚嫩的论文会被他批得体无完肤。深夜时 MSN 上弹出来一条消息“Hi”,学生们就知道一场深夜讨论要来了,他们很惊诧,怎么导师比他们年轻人还能熬夜。正是在这样一种师生齐心的劲头下,每个学生最后都达到了颜水成对他们“well-trained”(受过良好训练)的期望。到了 2010 年,颜水成团队在全球范围内已经名声渐起,他开始琢磨,“光写文章还不行”,还要走到国际计算机视觉比赛的舞台上,跟全世界企业和高校的团队一较高下。他将目光瞄准了这一年的 Pascal VOC 挑战赛。那时候,由欧盟组织的 Pascal VOC 是最热门且含金量最高的视觉比赛,而李飞飞在同年发起的 ImageNet 挑战赛,才刚刚起步。陈强本科毕业于中国科学技术大学,其后在上海交通大学读硕士,在将视觉识别研究应用在安防领域的过程中,他深感传统的机器视觉技术无法真正解决识别问题,决定继续读博探索这个方向。陈强的硕士导师刘允才教授也曾师从黄煦涛,便把陈强推荐到了同门颜水成的门下。陈强
陈强具有很强的解决问题的思维,而且对打比赛充满激情,若是在比赛中获得冠军,也能更好的实践自己的理论研究。
因为在识别任务上有经验,陈强就专攻 Pascal VOC 的分类子项(Classification)。经过半年的准备,颜水成团队首战告捷,成为最早在该比赛中夺冠的亚洲团队。值得一提的是,颜水成在打比赛方面的传承实际是继承于黄煦涛。黄煦涛极其喜欢Pascal VOC和ImageNet两个比赛,曾多次夺得冠军。在 NUS,传承也从陈强那里开始了。在首次出战的这一年,颜水成门下进来两位新学生——董健和夏威,他们也加入了之后的比赛队伍,并连续两年夺冠。董健本科毕业于中国科学技术大学,与师兄程斌和陈强均是校友。董健编程能力很强,本科时出于业余爱好,曾开发过百万下载量的游戏。也正是在游戏开发中,产生了对 AI 的浓厚兴趣,决定跟从在AI领域有着深厚背景的颜水成。董健
夏威与董健是同住了四年的室友。夏威本科在华中科技大学数理实验班就读,在系里刘文予教授的实验室里做科研训练,参与过华科和朱松纯老师在湖北创立的莲花山实验室的一些合作项目,为后面在NUS开展正式的视觉研究打下了一些基础。颜水成(左)、夏威(右)
2011 年的 Pascal VOC,陈强和董健在这一年作为主力做物体分类子项,再次拿到了分类子项的冠军。这一年的物体分割子项(Segmentation)则由夏威主导,成绩位列第三名。那时团队也开始做检测任务,而各个任务之间都相互关联,尤其是在深度学习之前,做分割需要分类和检测任务中很多传统机器学习算法的支持,所以夏威也同时辅助做其它子项的比赛。如果说 2010 年的冠军是颜水成团队的一个小高峰,那么在 2012 年,他们则经历了一个彻底的大转折——全面转向深度学习。Pascal VOC 挑战赛在 2012 年迎来收官之战。董健和夏威作为主力,分别揽下了分类和分割两个赛道的冠军。至此,颜水成团队在分类子项上实现三连冠,总共拿下四个冠军。这也是传统视觉算法最后的辉煌。而另一边,同期举行的 ImageNet 挑战赛终于在这一年大放异彩。包括颜水成在内的所有人都没有预料到,一轮新的人工智能热潮会在那里被掀起。2018 年图灵奖得主、时任多伦多大学教授的 Geoffrey Hinton 团队提出深度卷积神经网络 AlexNet,在 ImageNet 挑战赛上一举夺魁,深度学习的大潮由此拉开序幕。颜水成是“AlexNet时刻”的见证者之一,他和组里的学生都大为震动。虽然那时团队在全球视觉比赛的舞台上已经屡获佳绩,但他们惊讶地发现,自己所用的传统方法与深度学习这个“新物种”相比,竟能有这么大的 Gap。颜水成对神经网络非常熟练,早在2000年,他就采用神经网络给北京一家企业做经济指标的预测模型,产品上线后客户反馈效果特别好。当时,Data-adaptive kernel 这样的想法他就曾在传统神经网络上尝试过。面对深度学习带来的巨大性能提升,颜水成果断下了决定:这是历史性的变革,ALL-IN!。自此,颜水成整个实验室的研究方向和工作重点都完全转到了深度学习,是继 Hinton 等先驱者之后第一批开始深度学习探索的实验室之一。同时基于新加坡的优势,颜水成的实验室应该也是亚洲最早拥有百卡级NVIDIA GPU的大学实验室。颜水成在多年后告诉雷峰网:“我不太相信某一代技术能解决所有问题,新一代技术出现一定能带来更大的机会。所以我保持着随时清零的心态,新东西如果真的好,那我就会马上把它往前推动。”正是这种心态,使得颜水成在之前的子空间、稀疏表示/低秩矩阵的两次浪潮中都收获颇丰,都有单篇引用过千的论文, 这一次则轮到了深度学习。他的学生后来都十分感激当时颜水成的决断:“最重要的是当时颜老师的技术视野。方向选择对了,打比赛拿名次就是水到渠成的事儿。”决定转型后,一个专门小组很快就成立了,为转战 2013 年的 ImageNet 挑战赛做准备。颜水成把复现 AlexNet 的任务交给了组里 11 级博士生林敏。林敏从北京大学元培班毕业,读生物科学专业,喜欢写些代码。进入 NUS 后,林敏先去了一个生物实验室轮转。那段时间,林敏白天做生物实验,晚上写代码,同时在网上学吴恩达的机器学习课程。后来他觉得二选一才能更专注,于是干脆转计算机。林敏
经过一番调研,林敏选修了颜水成的模式识别课,课后向颜水成请教一个问题,并毛遂自荐。寥寥数语中,颜水成发觉这位学生很有独到的想法,便收下了这位北大校友。
与陈强、董健、夏威三位师兄不同,林敏刚开始对打比赛并不感兴趣,他更喜欢做原创研究,研究品味十分挑剔,在师兄弟眼里是最“清高”的那一个,有时会对他们直言不讳“我们现在做的是 incremental(提升性)的东西,得做点 innovative (创新性)的。不过在导师眼里,尤其对于林敏而言,“挑剔”的另一面,是他对从 0 到 1 做出突破的偏好与能力。林敏成功复现出 AlexNet 的结果后,颜水成就拉他打比赛:“既然你复现了出来,那我们打今年的比赛。” 他欣然应允。然而,新旧事物之间并不总能迅速而平滑地更替,很多团队都在试图复现并超越 AlexNet,颜水成团队在这一年的分类任务上采取的方案,是在复现的基础上加以部分改动,同时沿用传统的方法。也就是说,是一个“大杂烩”。最终第二名的成绩,象征了传统视觉时代最后一次并不优雅的挣扎。而对“大杂烩”不很满意的林敏,也想要做一个全新的深度网络出来。问题是,这个网络要做成什么样?颜水成下了一个命题:做减法。在当时计算资源非常受限的大背景下,要用最小的资源达到最优的性能。从这个目标出发,林敏负责网络架构的设计,陈强则从视觉应用的角度与林敏讨论数据量的规模。他们最后提出了著名的网络结构 NIN(Network in Network),首次使用了 1×1 卷积。1×1 卷积这个绝妙的设计,是林敏的一次“妙手偶得之”。在构思网络结构那段时间,林敏在一次课上突然出现自发性气胸,住院一周。不过这丝毫未耽误他的进度,他没想到的是,躺在医院病床上的那一周,灵感全都迸发了出来。他读到了“生成对抗网络(GAN)之父” Ian Goodfellow 在那年发表的一篇论文。这篇论文提出名为 Maxout 的网络,在线性变化之外添加 Max(求最大值) 操作,从而改进了以往的常规卷积网络。林敏思来想去,寻到了 Maxout 在当时具有最高识别率的原因所在,那就是有了 Max 操作后,它就比广义线性模型更复杂了。他想到,如果再往前推进一点呢?能不能把它变得更复杂一些?比如,在每一个卷积层后面再添加一个 MLP(多层感知器)卷积层。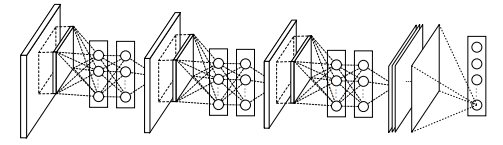
在最后实现的时候,他才惊喜地发现,太巧妙了,这正是 1×1 的卷积!加上一层 MLP 后,可以全连接地输出同样数量的特征图,不必改变输出的尺寸,卷积层之后又紧跟着神经元激活函数,所以在减少参数的同时,网络变深了,效果也进而得以提升。2014 年,NIN 的“考试”来了。董健和林敏作为主力,以 NIN 作为主干网络,在 ImageNet 检测子项“使用训练数据进行训练”场景上获得了冠军。当时实验室的另外一个博士生刘洛麒,正在想办法将深度学习应用到人脸领域。有了 NIN 的加持,很快他就将当时人脸识别和人脸检测最权威的基准 LFW 和 FDDB 的性能,刷到了当时世界最好的成绩。刘洛麒
同年,谷歌大脑团队推出的 GoogLeNet 也从 NIN 汲取灵感,采用 1x1 卷积,拿到了检测任务中“使用额外训练数据进行训练”场景的冠军,他们自称network in network in network。当时谷歌大脑的总监 Vincent Vanhoucke 和大神Jeff Dean在赛后当即给颜水成团队发了邮件表示祝贺。
不仅是 GoogLeNet,2015 年的冠军 ResNet 也使用了 1x1 卷积。NIN的核心1x1卷积成为后来几乎所有 CNN 模型变体的基础模块,极大地促进了深度学习的发展。Network in Network 的名字,背后还有一个小故事。颜水成和林敏通过邮件来回沟通了好几轮,其中有一个名字能缩写成MIN,很贴合林敏的名字,但全名不是很直白,最后颜水成建议Network in Network, 两人都觉得形象生动,就拍板下来了NIN(您)。后来2014比赛演讲的标题就设成了 NIN Good (您好)!投身深度学习浪潮的三年以来,这是颜水成和他的学生们真正意义上的第一次胜利。八年过去,颜水成在计算机视觉领域声名鹊起,团队每年在视觉顶会上的文章接受量非常耀眼。在视觉之外,他在多媒体领域的研究成果同样十分突出。从首次获得 Pascal VOC 冠军开始的四年里,颜水成团队开始收获他们在国际多媒体顶级会议 ACM Multimedia (ACM MM)上的奖项大满贯:2010 年最佳论文奖、2012 年最佳技术演示奖、2013 年最佳论文奖和最佳学生论文奖。首先做出技术落地尝试的是夏威。2012 年,一直盘算着创业的他,在打完分割任务的比赛后突发奇想,想将人体分割与分析(human parsing)技术用来落地,比如一键换衣、拍照搜衣服同款等。他专门跑去商学院修了一门创业课,带着创业项目申请了新加坡的一个 20 万新币的创业基金,但在倒数第二轮被毙掉了。没拿到钱的夏威颇为失意,也在这时有了日后去硅谷创业的念头。接着在第二年,颜水成带着他的一位博士生黄君实去阿里巴巴访问半年,并将他们的算法应用在在阿里电商平台上,协助第一个实现了拍照搜服饰同款的功能。看到技术真的变成了商业系统,他感觉打开了一片新的天地,也埋下了对技术落地的憧憬。黄君实
2015 年,颜水成真正觉得,时候到了。
这一年是整个视觉领域的转折点。孙剑在 MSRA 带领何恺明、张祥雨、任少卿凭借 ResNet 在 ImageNet 夺冠,掀起了一波更大的深度学习浪潮。机器学习的研究路子彻底成了实验科学,所谓“大力出奇迹”,谁有数据、算力,谁就是王道,而王道就掌握在工业界的少数几个巨头手中。一时间,许多学术界的顶尖学者开始奔向工业界,既是向往企业的“大力”,也是为了寻找技术落地的机会。吴恩达被余凯说服,在 2014 年去往百度任首席科学家。李飞飞则在 2016 年从斯坦福大学离职加入谷歌,孙剑也在这一年加盟旷视。有趣的是,吴恩达、余凯、李飞飞、孙剑等人与颜水成都是76年前后生人。他们经历了同样的时代:大学期间经历了90年代互联网浪潮的兴起;攻读博士时在AI低谷期的沉淀,反而成为了他们在AI时代到来时最宝贵的财富;当在各自领域深耕数年,学术研究已经达到了一个上限的时候,他们不约而同选择在技术落地上进行下一个突破。他们相互影响,成就了彼此。就在这个时候,有“红衣教主”之称的奇虎 360 董事长周鸿祎正在酝酿成立一个 AI 研究院,并从北京向颜水成抛来了橄榄枝。几乎每家老牌互联网大厂,都在那时纷纷投资深度学习,AI 研究院成为标配。颜水成在视觉研究上的耀眼履历自不必说,他的团队在比赛中多次夺冠,强大的技术研发与实践能力是周鸿祎尤为欣赏的地方。而从颜水成的视角,他看中的是 360 的场景。他那时发现,360 做智能硬件对视觉技术的需求很大,软硬件结合会是视觉的一个大趋势。此外,搜索、广告、金融、直播等AI和大数据紧密结合的应用场景,360也都兼而有之。这对于他和学生们来说,是一个大好机会。从学术界功成身退的颜水成就此北上,带着学生投身业界第一站,开始了技术落地的故事。如何在企业做 AI 研究院?颜水成定义了一个下限和上限。下限,是支持好内部业务,这也是研究院的立命所在。“哪里有 AI需求,我们就冲上去。” 这是颜水成所称的“万金油打法”。上限,是用技术去驱动甚至创造一个新业务和行业,在彼时的360,这项新业务就是IoT。颜水成很快转向“在商言商”的实用主义思维,将视觉研究置于商业逻辑的闭环内,与团队协同作战,打大仗。为打造智能硬件产品,颜水成与学生以及研究院的几十位研究员们,度过了许多个加班加点的攻坚之战。到 2018 年,他们已将人脸识别、语音识别、SLAM 等技术落地在非常多产品上。这年的双十一前夕,颜水成在 360 产品发布会上,推出 6 大“安全”智能硬件新品,以总价不足 3500 元的低价杀入了 IoT 市场,业界惊呼“性价比逆天”。颜水成在2018年10月30日 360 产品发布会上
决策智能也是颜水成技术落地的场景之一。这年 12 月,360 金融在纳斯达克敲响上市钟,颜水成的团队在大数据智能风控方面提供了支持。360 的广告、推荐业务也由深度学习技术作支撑。
2017 年,颜水成带领 360 与 NUS 的联队提出双通道网络 DPN,在 ImageNet 挑战赛上获得冠军,为这个举办了八年的赛事画上了圆满的句号,同时也成为PASCAL VOC和ImageNet 两项赛事收官之战的双料冠军团队。这次的灵魂人物是颜水成的学生陈云鹏,DPN的提出者,后来他也拒绝了Facebook的offer跟随颜水成来到中国。除了极高的准确率之外,DPN 的最大特点是低能耗,将 ResNet 的计算量降低了 57%,在实测中提速高达 300%。这其实也是结合工业界落地需求的必然结果。IoT 产品对资源利用率要求非常高,DPN 作为一个更轻量级的视觉模型,让 360 在视觉理解的赛道上迈出了更大一步。步入 2019 年,颜水成感觉在 360 使命已毕,决意开始新的征程。2018 年师门聚会:左起刘洛麒、董健、夏威、颜水成、陈强、黄君实、程斌(手机中照片为林敏)
他与学生们也就此暂别。
此时,林敏已于 2017 年11 月举家飞往加拿大,在深度学习“三巨头”之一Yushua Bengio 的Mila实验室做博士后,继续学术上新的探索。陈强离开的脚步比颜水成稍快了一些。念乡情的他回到老家上海,加入了“下沉市场三巨头”之一趣头条 ,在那里带AI算法团队。彼时他相信,互联网还有“增长”这个故事可讲。董健则在颜水成离开后继续留在了 360。由于对工程和业务落地更感兴趣,董健选择离开研究院,转而领导360智能工程部,负责公司级的AI基础设施建设和中台化AI能力输出,支持搜索、推荐、广告、金融和视觉等泛AI业务。而刘洛麒留在了360 AI 研究院,继续负责计算机视觉在 IoT 和互联网业务的落地。后来他加入美图,领导美图影像研究院(MT Lab),负责产品核心算法研发,并在新一轮AI大模型浪潮中,研发出国内首款懂美学的美图视觉大模型MiracleVision。黄君实则在360信息流产品部磨炼一段时间之后,加入了美团视觉智能中心,继续探索他的产研之路。毕业之后就创业的程斌,则开启了二次创业之路,其所在公司Fasion.AI是国内较早聚焦于AIGC及其商业化落地的初创团队。毕业后没有跟随团队加入360但却一直有着创业梦的夏威,则在毕业答辩之前就带着老师的祝福飞往旧金山湾区创业。他作为创始成员加入了华人留学生创办的 CV 公司 Orbeus,担任chief scientist,负责识别算法的研发。2015年底公司被亚马逊收购后,他随之加入了AWS AI,担任Principal Scientist,领导团队先后发布了AWS最早的几款Cloud AI产品Rekognition,Textract等。学生们各自求仁得仁,颜水成也重整行装,准备寻找技术落地的新土壤。2019 年 7 月,在老朋友朱珑的盛情相邀下,颜水成来到了“AI四小龙”之一的依图科技,出任 CTO,继续让 AI 技术在更多场景真正落地。那时的依图在人脸识别竞赛 NIST-FRVT 上已蝉联三年冠军,而依图的安防和医疗赛道,不仅能为颜水成将视觉落地提供场景,更与他对技术价值的想象十分吻合。这一次,颜水成给自己定义了两个命题,一是做好视觉研究,二是推动技术与业务的结合,进一步落地。在依图的一年多时间里,他都努力在实践这两个命题。2020 年4月25 日,颜水成的恩师黄煦涛过世。悲伤之余,颜水成开始静心思考如果再工作四十年,最应该做什么。他把答案落在了重回学术基础研究上,此后他的几次选择都离不开这次深度的思考。2021年1月,颜水成重回新加坡,正式出任 Sea 集团首席科学家,并负责从零建设和领导 Sea 人工智能实验室(SAIL)。林敏、陈强、董健等人则开始了他们第二次的追随,不同的是,加入 Sea 后,他们是各自沿着不同的轨道继续行驶。陈强和董健在工业界磨炼多年,加入了Shopee,现在仍在Shopee领导着业务线。一如既往学者范的林敏,则跟随颜水成同在 SAIL,探索 AI For Science 应用。颜水成提到这位学生总是夸赞不停,让他去推动一些新的方向。如今,林敏依旧在Sea担任着AI首席研究员,继续着他的学术研究之路。2023年年初,昆仑万维创始人周亚辉联系上颜水成,彼时的颜水成刚刚结束在 Sea的研究工作,准备去智源研究院访问一段时间。在颜水成眼中,智源研究院或许是中国最接近 Open AI 和 Deepmind 风格的团队,而恩师张宏江正是智源的创始人,他用「潜心磨剑」形容自己的这次游历与访问。历时半年,在智源的访问结束之后,颜水成再次整装重新出发。而年初周亚辉的出现,为这次重新出发更添了一份传奇色彩,早在颜水成决定去智源访问之时,周亚辉便提前预定了需要颜水成出任「AI掌门」。2023年9 月,颜水成正式加入昆仑万维,与周亚辉一起出任天工智能联席 CEO,并兼任昆仑万维 2050 全球研究院院长。如今,颜水成早已是新加坡工程院院士,同时当选 AAAI Fellow、ACM Fellow、IEEE Fellow 和 IAPR Fellow 等诸多荣誉,是中国计算机视觉领域的佼佼者。并且,他已经八次入选「汤森路透全球高被引学者」。毫无疑问,此时的颜水成选择再次入局工业界,是带着更大的底气与实力。于颜水成而言,他想在企业研究院进行长期性研究,做出新突破,把握住这波 AI 浪潮带来的新机遇。这些年来,颜水成和学生们每一次的选择都并非是随波逐流,而是对潮流的主动把握。在研究层面上,多年以来,颜水成一直追求学术界和工业界的双重满足(Double Satisfactions),在技术层面一直追求走在AI的浪尖上,在他看来目前的浪尖是Foundation Models,也正是AI最令人兴奋的时刻。他始终认为通用人工智能时代来临,未来拥有无限可能。在通用人工智能领域,从研究、研发到产品是完整的链条,缺一不可,只有将三者完全打通,研究才能发挥最大价值。昆仑万维愿意将研究、研发、产品三线合一,无疑是颜水成实现潮流创造之梦的绝佳平台。此外,昆仑万维承诺提供的研究环境,在颜水成看来,也是一个新的世外桃源之地。以前大量的AI PhD毕业生选择离开了新加坡,一个核心原因是缺少像硅谷那样支持最前沿AI基础研究的企业,昆仑万维2050研究院将是本地企业的起点,这样更多的新加坡毕业生可以选择留下来,同时也能吸引合适的研究者来到新加坡。昆仑万维2050研究院也将担当AI前沿研究的种子,更多的本地和海外企业如果跟进建立Labs, 新加坡就会建立完善的生态圈,为扎根新加坡、面向东南亚市场的企业提供强大的技术和信心支撑。目前,昆仑万维2050全球研究院还处于早期孵化阶段,但颜水成的抱负十分远大:他希望建立一支既懂学术、又懂商业,能够真正把研究、研发和产品结合在一起的优秀团队,帮助昆仑万维打造业界领先的人工智能团队,推动天工大模型及AIGC业务迈向一个新高度,加速AI产品的研发、落地及商业化。确保昆仑万维2050全球研究走在通往通用人工智能(AGI)正确的路径上,是颜水成在昆仑万维的新使命。关于方向,颜水成表示将逐步开展不同领域的研究:下一代Foundation Model的基础研究和研发;Agent的研发和智能体进化的研究;生物智能等前沿技术领域的探索。他的重点的方向会主要围绕下一代Foundation Model,研究方向也会从以前专注计算机视觉,更多地转向CV+NLP,多模态的研究。除了前文提及的董健、陈强、林敏仍在Shoppe外,颜水成的学生遍布全球AI行业,冯佳时现在是字节跳动智能内容创作基础研究团队负责人;刘洛麒现在担任着美图影像研究院(MT Lab)负责人;程斌也继续在创业道路上努力前行。颜水成现在则除了做研究之外,也在通过培养学生、指导他们融资,让学生们能够通过创业的方式在AI行业发光发热。回顾颜水成的学术与产业经历,狮城新加坡是一个重要据地。2007年,他第一次踏入新加坡,曾给恩师黄煦涛发邮件请教“how to be a good professor”,得到的回答是“Just be yourself”。他把这句话分享给了学生们,并阐释为“Confident、Unique、...”,怀着这种信念去挑战世界级比赛、发表顶级论文,并毅然带领学生们走向工业界。这些年兜兜转转,颜水成心中的信念和愿景始终不变,“希望像李开复那一代人那样做AI布道人,拉一些有号召力的人进来。”现在,颜水成可以重新出发了。 更多人工智能领域动态与故事,欢迎添加作者微信:lionceau2046,互通有无。
更多人工智能领域动态与故事,欢迎添加作者微信:lionceau2046,互通有无。