随着 Meta 的 Llama2 开源,开源模型,以及聚集大模型开发者的开源社区,正在发挥不可或缺的作用。
一个例子是,上个月 Hugging Face 得到了谷歌、亚马逊、英伟达、Salesforce、AMD、英特尔、IBM 和高通的共同投资。这些大公司共同出手的原因是:他们的员工正在积极使用 Hugging Face 平台。Hugging Face CEO 德兰格表示,「也许五年后,将拥有大约 1 亿 AI 构建者。如果所有人都整天使用 Hugging Face,我们显然会处于有利位置。」几个月以来,国内多家大模型厂商开始走开源路径,其中,阿里云是最积极的云厂商。本周,阿里云开源通义千问 140 亿参数模型 Qwen-14B,以及其对话模型 Qwen-14B-Chat。阿里云同时公布了其 AI 开发者社区——魔搭的最新数据。目前,魔搭社区已有 230 多万开发者,8500 万的模型下载量。据阿里云上季度财报,魔搭社区模型的下载量是 4500 万。也就是说,不到两个月,模型的下载量翻番。一个半月内,这已经是阿里云第三次推出免费可商用的开源模型。并且,与更大尺寸模型一同开源的,还有技术报告。与预训练、对齐等一系列模型训练过程有关的数据、方法都在报告中得以详细呈现。对此,阿里云 CTO 周靖人表示,这也是今天中国模型社区的第一次,「不单单开源我们的模型,把报告也分享给大家,能够让大家体验到模型各式各样的表现,更有效地帮助大家进行模型的应用。」同时,他认为,客观地从全方位的维度来衡量一个模型,把各种各样的指标公开,这些可以帮助开发者有效衡量:今天从哪个模型开始,让开发者参与起来。开源模型在多大程度上开源,这也是开发者最关心的问题,尤其是关于商业使用权和数据集的开放。此前,电气与电子工程师协会 IEEE 网站上,有学者质疑 Llama2 的开源属性。尽管 Meta 已经提供了经过训练的模型,但并未共享模型的训练数据或用于训练模型的代码。虽然第三方能够创建在模型上扩展的应用程序,但想要进一步研究 Llama2 的开发人员和研究人员无法复刻模型。在这一点上,开源社区和开源模型的开放性需要进一步被讨论。除了开源,周靖人在日前的 Qwen-14B 发布会上,接受了包括极客公园在内的多家媒体采访,透露了客户侧大模型的演进方向,阿里云闭源、开源两条腿走路背后的思考等问题。以下为阿里云 CTO 周靖人对话内容,经极客公园整理:问:从阿里云与客户的接触来看,目前在通用大模型的落地方面,哪些应用方向需求量较大?周靖人:把模型真正运用在实际场景里,还是需要有很多二次开发,甚至今天就要结合领域知识。如何能够解决领域的问题,是今天基础模型比较欠缺的地方。今天在一些特殊领域里,其实有很多专业知识,有很多的专业 know how,需要不断深挖这些领域,把这些核心能力跟比如开源的通义千问 7B 或者 14B 的模型有效地结合在一起,不断加深领域知识,变成这个领域的一个核心模型。具体还会遇到一些客户场景,客户有一些特殊的数据或者信息,还不便于公开。这时候,可以考虑通过知识增强的方式,prompt engineering(提示词工程),或者做一些记忆的模块,这一系列对整个模型的落地起到至关重要的作用。不久的将来,也会跟大家分享阿里云在这方面如何把模型的落地做成一个产品,从而有效帮助我们的开发者、ISV,甚至企业能够快速把模型的能力应用在实际的业务场景里面。周靖人:今天在模型应用里,可能更多是要做相关的模型拓展。包括今天根据各行各业的知识,或者今天如何能更有效地做相关的 fine-tune(模型精调)。在工具这一层,我们也收到大家的反馈,不断地去打磨,能够把我们模型的应用做到低门槛,同时更高效。问:通义千问实现全面开源,面临的最大挑战或困难是什么?周靖人:讲到模型的应用,不能说今天只做一个 foundation model(基础模型),(基础模型)跟我们实际的应用场景还会有很大距离。怎么能够帮助开发者、企业用好模型,这是今天很重要的一个环节。 来源:视觉中国我们做开源也是基于这样一个场景,真正实现目标,让 AI 更加普惠。这句话要实现是非常难的,很有挑战,需要我们跟行业伙伴共同合作。问:Qwen-14B 开源模型与之前的 Qwen-7B 相比,有哪些突破?周靖人:这两个模型处于不同的量级。今天随着模型参数的增加,模型的整体容量,包括它的能力都有不断地提升。如果直接把 7B 和 14B 这两个模型的级别做比较,14B 模型往往会比 7B 在某些领域,特别是在长尾的领域表现出更强的认知能力,甚至推理能力,包括算术等方面。这两款开源模型,基本上在各自领域,都领先于市场上大家耳熟能详的模型。甚至可以跨级别地做一些比较,千问 14B 的模型比很多更大规模模型的指标都有提升,但它的好处是比这些大的模型更加 compact。也就是说,它在模型微调方面,在模型的应用方面会更有性价比。魔搭作为一个开源的模型社区,希望给不同的开发者、不同的企业更多的选择。这是在 7B 的规模之上,要开进一步开源 14B 模型的初衷。至于怎么选择,很多时候要结合业务场景。不同的场景可以根据需求选择不一样规模的模型来应用在自己的开发环境里。
来源:视觉中国我们做开源也是基于这样一个场景,真正实现目标,让 AI 更加普惠。这句话要实现是非常难的,很有挑战,需要我们跟行业伙伴共同合作。问:Qwen-14B 开源模型与之前的 Qwen-7B 相比,有哪些突破?周靖人:这两个模型处于不同的量级。今天随着模型参数的增加,模型的整体容量,包括它的能力都有不断地提升。如果直接把 7B 和 14B 这两个模型的级别做比较,14B 模型往往会比 7B 在某些领域,特别是在长尾的领域表现出更强的认知能力,甚至推理能力,包括算术等方面。这两款开源模型,基本上在各自领域,都领先于市场上大家耳熟能详的模型。甚至可以跨级别地做一些比较,千问 14B 的模型比很多更大规模模型的指标都有提升,但它的好处是比这些大的模型更加 compact。也就是说,它在模型微调方面,在模型的应用方面会更有性价比。魔搭作为一个开源的模型社区,希望给不同的开发者、不同的企业更多的选择。这是在 7B 的规模之上,要开进一步开源 14B 模型的初衷。至于怎么选择,很多时候要结合业务场景。不同的场景可以根据需求选择不一样规模的模型来应用在自己的开发环境里。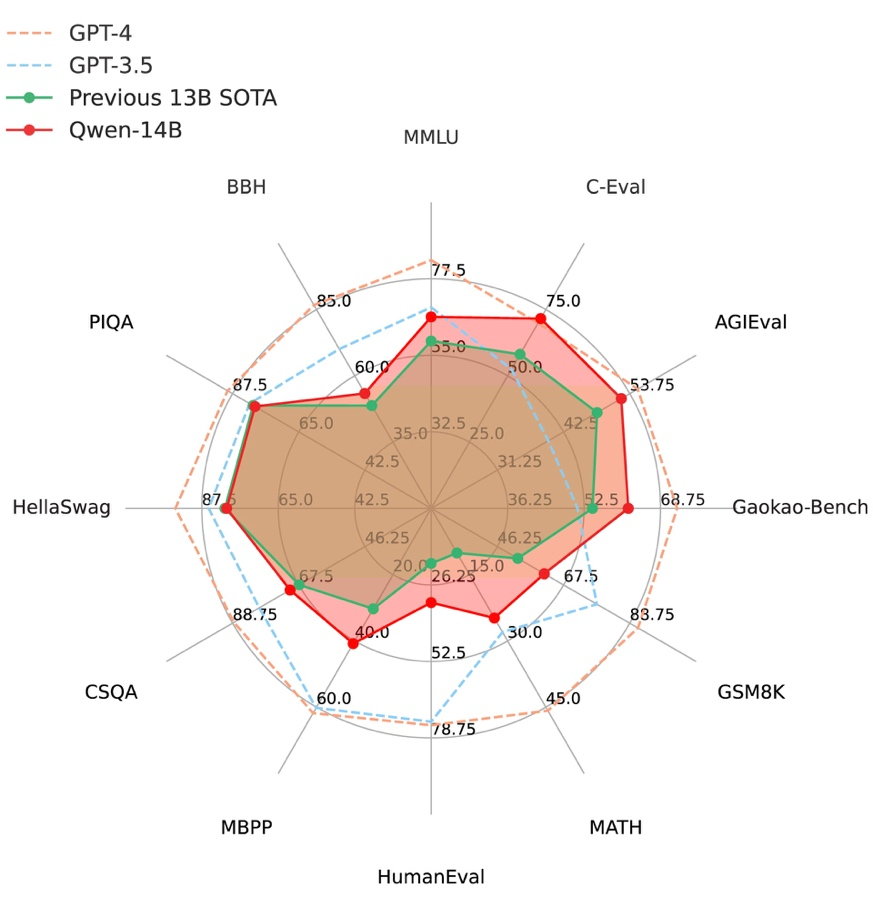 Qwen-14B 在十二个权威测评中全方位超越同规模 SOTA 大模型|图片来源:阿里云问:从模型应用层看,多大规模的模型最有市场,为什么?周靖人:不能一概而论,这也是我们会提供不同尺寸开源模型的原因。不同企业或者不同场景,涉及到的数据量或者对模型的要求不一样。甚至也跟我们模型服务的成本相关,今天越大规模的模型,固然在推理,在认知能力上更好,但是它的服务成本也会相应提升,在上面去做二次开发,做 fine-tune(模型精调),结合自己的知识增强等等,成本也会不断提升。每一个企业、开发者实际上要做一个选择,一方面是极致的性能,另一方面是一个极致的成本。他们会根据实际场景问题的复杂度,包括今天调用的频次、相关资源配比的情况,做出符合业务场景的选择。阿里云认为只有把选择权交给开发者,交给企业,才能更加有效地让我们的 AI 能力落地在各个业务场景里。问:通义千问开源版本和 API 调用两种模式如何平衡,是否是小参数的就开源?什么样的客户选开源,什么样的客户选 API 调用?未来开源、闭源模型会形成什么样的格局?周靖人:我们的开源版本,无论是 7B 还是 14B,都会在魔搭社区和 Hugging Face 等同步的开源。另外一方面,也会同步以 API 的形式,在阿里云灵积平台上,提供各种 API 服务。我觉得还是要回到初衷,如何让 AI 更普惠。应该问,以什么样的方式去支持开发者、企业,能够更加有效地让他们把模型的能力跟自己的业务场景有效结合在一起,去解决实际问题,所以其实不在乎今天到底是开源、闭源。今天从基础模型到应用场景,还有很长的路。我们希望在做开源的时候,能激发大家在业务创新的各方面突破,(让大家)有更多的自由空间,结合自己的应用场景做更加突破性的创新。只有有更多的创新后,才能让 AI 更好地落地。问:开源大模型,对闭源大模型相比,有什么样的补充?阿里云平台上,两种不同模型的落地,未来将是一个什么样的比例?哪些客户会更倾向于开源大模型?周靖人:今天闭源、开源都是一种手段,更多的是今天怎么能够让这些模型,快速应用在各种各样的场景里面。即使在闭源里面做产品化,也是为了让今天 AI 的使用门槛更低,让 AI 的能力更加普惠,这是我们的初衷。但是不同的场景有不一样的需求,一定不是 one size fits all,不是只有一个模型就可以服务所有,也不是只有一种方式。今天阿里云在支持整个魔搭社区的时候,不是只有通义的模型,还有很多开源社区的模型,还有很多合作伙伴的模型。他们的模型在很多方面有很多优势,我们希望大家共同来建设社区,能够真正意义上把模型的能力带到实际场景中。阿里云在这个过程中间,希望为大家提供基础的支持,不管是算力的支持还是模型服务的支持,这也是为什么阿里云积极参与到模型开源的路径上来。
Qwen-14B 在十二个权威测评中全方位超越同规模 SOTA 大模型|图片来源:阿里云问:从模型应用层看,多大规模的模型最有市场,为什么?周靖人:不能一概而论,这也是我们会提供不同尺寸开源模型的原因。不同企业或者不同场景,涉及到的数据量或者对模型的要求不一样。甚至也跟我们模型服务的成本相关,今天越大规模的模型,固然在推理,在认知能力上更好,但是它的服务成本也会相应提升,在上面去做二次开发,做 fine-tune(模型精调),结合自己的知识增强等等,成本也会不断提升。每一个企业、开发者实际上要做一个选择,一方面是极致的性能,另一方面是一个极致的成本。他们会根据实际场景问题的复杂度,包括今天调用的频次、相关资源配比的情况,做出符合业务场景的选择。阿里云认为只有把选择权交给开发者,交给企业,才能更加有效地让我们的 AI 能力落地在各个业务场景里。问:通义千问开源版本和 API 调用两种模式如何平衡,是否是小参数的就开源?什么样的客户选开源,什么样的客户选 API 调用?未来开源、闭源模型会形成什么样的格局?周靖人:我们的开源版本,无论是 7B 还是 14B,都会在魔搭社区和 Hugging Face 等同步的开源。另外一方面,也会同步以 API 的形式,在阿里云灵积平台上,提供各种 API 服务。我觉得还是要回到初衷,如何让 AI 更普惠。应该问,以什么样的方式去支持开发者、企业,能够更加有效地让他们把模型的能力跟自己的业务场景有效结合在一起,去解决实际问题,所以其实不在乎今天到底是开源、闭源。今天从基础模型到应用场景,还有很长的路。我们希望在做开源的时候,能激发大家在业务创新的各方面突破,(让大家)有更多的自由空间,结合自己的应用场景做更加突破性的创新。只有有更多的创新后,才能让 AI 更好地落地。问:开源大模型,对闭源大模型相比,有什么样的补充?阿里云平台上,两种不同模型的落地,未来将是一个什么样的比例?哪些客户会更倾向于开源大模型?周靖人:今天闭源、开源都是一种手段,更多的是今天怎么能够让这些模型,快速应用在各种各样的场景里面。即使在闭源里面做产品化,也是为了让今天 AI 的使用门槛更低,让 AI 的能力更加普惠,这是我们的初衷。但是不同的场景有不一样的需求,一定不是 one size fits all,不是只有一个模型就可以服务所有,也不是只有一种方式。今天阿里云在支持整个魔搭社区的时候,不是只有通义的模型,还有很多开源社区的模型,还有很多合作伙伴的模型。他们的模型在很多方面有很多优势,我们希望大家共同来建设社区,能够真正意义上把模型的能力带到实际场景中。阿里云在这个过程中间,希望为大家提供基础的支持,不管是算力的支持还是模型服务的支持,这也是为什么阿里云积极参与到模型开源的路径上来。 2023世界人工智能大会,阿里巴巴魔搭社区展台|图片来源:视觉中国问:阿里云更有兴趣培育开源大模型,还是对大模型之上做应用兴趣更大?周靖人:我们更有兴趣让 AI 蓬勃发展。今天要让整个 AI 的生态蓬勃发展,只做开源也不行,但不做开源更不行。问:商业化最后是不是还是通过应用挣钱?MaaS 的商业模式如何跑通?周靖人:今天涉及到模型有价值的服务,不管是通用的服务,还是定制化的服务,甚至一个通用的模型到一个具体的业务场景里,还有一定的技术过程,包括:怎么去收集本地数据、怎么拿一些反馈、怎么能够做一些知识增强,这些中间有很多商业想象的空间。但我们认为,今天在模型这部分,应该先注重生态,再注重商业化,而不是一开始就过度围绕商业化。把 AI 的社区、开发者的生态,茁壮培养起来,是我们当前所需要共同努力的首要问题。周靖人:像这次模型的开源,不单单是做模型的开源,同时,还是国内第一个来提供 technical report。这个论文一方面阐述了模型整个研发的过程;另一方面,也最客观地从全方位的维度来衡量一个模型,各种各样的指标都是公开透明的。这些都是帮助开发者有效衡量:今天从哪个模型开始。另一方面,有不少开发者也跟我们提要求,在跟他们积极互动的过程中,我们发现有这样一个生态后,很多开发者可以帮助其他开发者。另外,今天像通义千问模型,跟阿里云的相关 AI 产品、技术体系是有效联合在一起的。不管是要使用一个模型的服务,还是做 fine tune,做一些知识增强,阿里云都会有一系列产品和技术,帮助开发者进行模型应用。问:你觉得未来的云计算会有什么样的新形式?开源模型会不会成为云计算的标配?周靖人:云计算在这样一个 AI 时代里,肯定在不断变化,不断创新,包括模型的开发、模型的服务,一系列的技术体系在升级。我觉得开源模型会成为我们生态的一部分,但不一定会成为全部。就像今天在大数据里面有很多开源的产品,在数据库里面也有很多开源的产品。但是今天在整个云计算里,有的人会用开源的产品,可能用户自己的技术实力强,会做一些定制的开发;但更多的人会使用的是今天像 PaaS 这样一个产品,也就是说,会基于云计算上面的一系列产品,来进行服务。问:微软的大模型已集成在系统甚至 Bing 里下放给用户,在接近于完成培养用户习惯的阶段,并且行成了用户付费的闭环。阿里云如何看待这一问题?周靖人:并不是说今天我们做大模型,我们就要把端到端的所有的链路都要由阿里云来提供。站在云的视角,我们希望更多地被集成。也就是说,把模型能力提供给各行各业的服务商、软件商,让他们能够把整体产品技术的体系升级,服务好他的客户。但我们这个过程中间是需要作为云平台,要提前多走一步,希望把技术能力提供给我们的合作伙伴。
2023世界人工智能大会,阿里巴巴魔搭社区展台|图片来源:视觉中国问:阿里云更有兴趣培育开源大模型,还是对大模型之上做应用兴趣更大?周靖人:我们更有兴趣让 AI 蓬勃发展。今天要让整个 AI 的生态蓬勃发展,只做开源也不行,但不做开源更不行。问:商业化最后是不是还是通过应用挣钱?MaaS 的商业模式如何跑通?周靖人:今天涉及到模型有价值的服务,不管是通用的服务,还是定制化的服务,甚至一个通用的模型到一个具体的业务场景里,还有一定的技术过程,包括:怎么去收集本地数据、怎么拿一些反馈、怎么能够做一些知识增强,这些中间有很多商业想象的空间。但我们认为,今天在模型这部分,应该先注重生态,再注重商业化,而不是一开始就过度围绕商业化。把 AI 的社区、开发者的生态,茁壮培养起来,是我们当前所需要共同努力的首要问题。周靖人:像这次模型的开源,不单单是做模型的开源,同时,还是国内第一个来提供 technical report。这个论文一方面阐述了模型整个研发的过程;另一方面,也最客观地从全方位的维度来衡量一个模型,各种各样的指标都是公开透明的。这些都是帮助开发者有效衡量:今天从哪个模型开始。另一方面,有不少开发者也跟我们提要求,在跟他们积极互动的过程中,我们发现有这样一个生态后,很多开发者可以帮助其他开发者。另外,今天像通义千问模型,跟阿里云的相关 AI 产品、技术体系是有效联合在一起的。不管是要使用一个模型的服务,还是做 fine tune,做一些知识增强,阿里云都会有一系列产品和技术,帮助开发者进行模型应用。问:你觉得未来的云计算会有什么样的新形式?开源模型会不会成为云计算的标配?周靖人:云计算在这样一个 AI 时代里,肯定在不断变化,不断创新,包括模型的开发、模型的服务,一系列的技术体系在升级。我觉得开源模型会成为我们生态的一部分,但不一定会成为全部。就像今天在大数据里面有很多开源的产品,在数据库里面也有很多开源的产品。但是今天在整个云计算里,有的人会用开源的产品,可能用户自己的技术实力强,会做一些定制的开发;但更多的人会使用的是今天像 PaaS 这样一个产品,也就是说,会基于云计算上面的一系列产品,来进行服务。问:微软的大模型已集成在系统甚至 Bing 里下放给用户,在接近于完成培养用户习惯的阶段,并且行成了用户付费的闭环。阿里云如何看待这一问题?周靖人:并不是说今天我们做大模型,我们就要把端到端的所有的链路都要由阿里云来提供。站在云的视角,我们希望更多地被集成。也就是说,把模型能力提供给各行各业的服务商、软件商,让他们能够把整体产品技术的体系升级,服务好他的客户。但我们这个过程中间是需要作为云平台,要提前多走一步,希望把技术能力提供给我们的合作伙伴。 图片来源:视觉中国周靖人:今天模型的生态一定是要开放公开,有更多人来参与,但也要保持一个求真务实的状态。今天比较客观地评价一个模型的能力,也能让开发者参与起来。魔搭社区自始至终秉承着公开开放的理念,不管是模型开发者、创业者,还是头部企业,都能通过魔搭社区去触达更多的开发者,把他们的能力分享给社区,社区反过来给一些反馈。
图片来源:视觉中国周靖人:今天模型的生态一定是要开放公开,有更多人来参与,但也要保持一个求真务实的状态。今天比较客观地评价一个模型的能力,也能让开发者参与起来。魔搭社区自始至终秉承着公开开放的理念,不管是模型开发者、创业者,还是头部企业,都能通过魔搭社区去触达更多的开发者,把他们的能力分享给社区,社区反过来给一些反馈。
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO你如何看待
阿里云做开源这件事?
今天凌晨,扎克伯克在Meta Conference上发布了新产品AIs。AIs 基于 Llama 2开发,被赋予了28种性格,包括巴黎·希尔顿、肯豆·卡戴珊等28个名人的个性。