机器人是一种拥有无尽可能性的技术,尤其是当搭配了智能技术时。近段时间创造了许多变革性应用的大模型有望成为机器人的智慧大脑,帮助机器人感知和理解这个世界并制定决策和进行规划。近日,CMU 的 Yonatan Bisk 和 Google DeepMind 的夏斐(Fei Xia)领导的一个联合团队发布了一篇综述报告,介绍了基础模型在机器人领域的应用和发展情况。
开发能自主适应不同环境的机器人是人类一直以来的一个梦想,但这却是一条漫长且充满挑战的道路。之前,利用传统深度学习方法的机器人感知系统通常需要大量有标注数据来训练监督学习模型,而如果通过众包方式来标注大型数据集,成本又非常高。此外,由于经典监督学习方法的泛化能力有限,为了将这些模型部署到具体的场景或任务,这些训练得到的模型通常还需要精心设计的领域适应技术,而这又通常需要进一步的数据收集和标注步骤。类似地,经典的机器人规划和控制方法通常需要仔细地建模世界、智能体自身的动态和 / 或其它智能体的动态。这些模型通常针对各个具体环境或任务构建,而当情况有变时,就需要重新构建模型。这说明经典模型的迁移性能也有限。事实上,对于很多用例,构建有效模型的成本要么太高,要么完全无法办到。尽管基于深度(强化)学习的运动规划和控制方法有助于缓解这些问题,但它们仍旧会受到分布移位(distribution shift)和泛化能力降低的影响。虽然在开发通用型机器人系统上正面临诸多挑战,但自然语言处理(NLP)和计算机视觉(CV)领域近来却进展迅猛,其中包括用于 NLP 的大型语言模型(LLM)、用于高保真图像生成的扩散模型、用于零样本 / 少样本生成等 CV 任务的能力强大的视觉模型和视觉语言模型。所谓的「基础模型(foundation model)」其实就是大型预训练模型(LPTM)。它们具备强大的视觉和语言能力。近来这些模型也已经在机器人领域得到应用,并有望赋予机器人系统开放世界感知、任务规划甚至运动控制能力。除了将现有的视觉和 / 或语言基础模型用于机器人领域,也有研究团队正针对机器人任务开发基础模型,比如用于操控的动作模型或用于导航的运动规划模型。这些机器人基础模型展现出了强大的泛化能力,能适应不同的任务甚至具身方案。也有研究者直接将视觉 / 语言基础模型用于机器人任务,这展现出了将不同机器人模块融合成单一统一模型的可能性。尽管视觉和语言基础模型在机器人领域前景可期,全新的机器人基础模型也正在开发中,但机器人领域仍有许多挑战难以解决。从实际部署角度看,模型往往是不可复现的,无法泛化到不同的机器人形态(多具身泛化)或难以准确理解环境中的哪些行为是可行的(或可接受的)。此外大多数研究使用的都是基于 Transformer 的架构,关注的重点是对物体和场景的语义感知、任务层面的规划、控制。而机器人系统的其它部分则少有人研究,比如针对世界动态的基础模型或可以执行符号推理的基础模型。这些都需要跨领域泛化能力。最后,我们也需要更多大型真实世界数据以及支持多样化机器人任务的高保真度模拟器。这篇综述论文总结了机器人领域使用的基础模型,目标是理解基础模型能以怎样的方式帮助解决或缓解机器人领域的核心挑战。
论文地址:https://arxiv.org/pdf/2312.08782.pdf在这篇综述中,研究者使用的「用于机器人的基础模型(foundation models for robotics)」这一术语涵盖两个方面:(1) 用于机器人的现有的(主要)视觉和语言模型,主要是通过零样本和上下文学习;(2) 使用机器人生成的数据专门开发和利用机器人基础模型,以解决机器人任务。他们总结了用于机器人的基础模型的相关论文中的方法,并对这些论文的实验结果进行了元分析(meta-analysis)。

为了帮助读者更好地理解这篇综述的内容,该团队首先给出了一节预备知识内容。他们首先将介绍机器人学的基础知识以及当前最佳技术。这里主要聚焦于基础模型时代之前机器人领域使用的方法。这里简单说明一下,详情参阅原论文。 机器人的主要组件可分为感知、决策和规划、动作生成三大部分。该团队将机器人感知分为被动感知、主动感知和状态估计。在机器人决策和规划部分,研究者分经典规划方法和基于学习的规划方法进行了介绍。机器的动作生成也有经典控制方法和基于学习的控制方法。接下来该团队又会介绍基础模型并主要集中在 NLP 和 CV 领域,涉及的模型包括:LLM、VLM、视觉基础模型、文本条件式图像生成模型。这一节总结了典型机器人系统的不同模块所面临的五大核心挑战。图 3 给出了这五大挑战的分类情况。
机器人系统往往难以准确地感知和理解其环境。它们也没有能力将在一个任务上的训练成果泛化到另一个任务,这会进一步限制它们在真实世界中的实用性。此外,由于机器人硬件不同,将模型迁移用于不同形态的机器人也很困难。通过将基础模型用于机器人,可以部分地解决泛化问题。而在不同机器人形态上泛化这样更进一步的问题还有待解答。为了开发出可靠的机器人模型,大规模的高质量数据至关重要。人们已经在努力尝试从现实世界收集大规模数据集,包括自动价值、机器人操作轨迹等。并且从人类演示收集机器人数据的成本很高。而由于任务和环境的多样性,在现实世界收集足够且广泛的数据的过程还会更加复杂。此外,在现实世界收集数据还会有安全方面的疑虑。为了解决这些挑战,许多研究工作都尝试了在模拟环境中生成合成数据。这些模拟能提供真实感很强的虚拟世界,让机器人可以在接近真实的场景中学习和使用自己的技能。但是,使用模拟环境也有局限性,尤其是在物体的多样性方面,这使得所学到的技能难以直接用于真实世界情况。另外,在现实世界中,大规模收集数据非常困难,而要收集到训练基础模型所使用的互联网规模级的图像 / 文本数据,那就更困难了。一种颇具潜力的方法是协作式数据收集,即将不同实验室环境和机器人类型的数据收集到一起,如图 4a 所示。但是,该团队深度研究了 Open-X Embodiment Dataset,发现在数据类型可用性方面还存在一些局限性。
经典的规划和控制方法通常需要精心设计的环境和机器人模型。之前的基于学习的方法(如模仿学习和强化学习)是以端到端的方式训练策略,也就是直接根据感官输入获取控制输出,这样能避免构建和使用模型。这些方法能部分解决依赖明确模型的问题,但它们往往难以泛化用于不同的环境和任务。这就引出了两个问题:(1) 怎么学习能很好泛化的与模型无关的策略?(2) 怎么学习好的世界模型,以便应用经典的基于模型的方法?为了得到通用型智能体,一大关键挑战是理解任务规范并将其根植于机器人对世界的当前理解中。通常而言,这些任务规范由用户提供,但用户只能有限地理解机器人的认知和物理能力的局限性。这会带来很多问题,不仅包括能为这些任务规范提供什么样的最佳实践,而且还有起草这些规范是否足够自然和简单。基于机器人对自身能力的理解,理解和解决任务规范中的模糊性也充满挑战。为了在现实世界中部署机器人,一大关键挑战是处理环境和任务规范中固有的不确定性。根据来源的不同,不确定性可以分为认知不确定性(由缺乏知识导致不确定)和偶然不确定性(环境中固有的噪声)。不确定性量化(UQ)的成本可能会高得让研究和应用难以为继,也可能让下游任务无法被最优地解决。有鉴于基础模型大规模过度参数化的性质,为了在不牺牲模型泛化性能的同时实现可扩展性,提供能保留训练方案同时又尽可能不改变底层架构的 UQ 方法至关重要。设计能提供对自身行为的可靠置信度估计,并反过来智能地请求清晰说明反馈的机器人仍然是一个尚未解决的挑战。近来虽有一些进展,但要确保机器人有能力学习经验,从而在全新环境中微调自己的策略并确保安全,这一点依然充满挑战。这一节总结了用于机器人的基础模型的当前研究方法。该团队将机器人领域使用的基础模型分成了两大类:用于机器人的基础模型和机器人基础模型(RFM)。用于机器人的基础模型主要是指以零样本的方式将视觉和语言基础模型用于机器人,也就是说无需额外的微调或训练。机器人基础模型则可能使用视觉 - 语言预训练初始化来进行热启动和 / 或直接在机器人数据集上训练模型。
这一小节关注的是视觉和语言基础模型在机器人领域的零样本应用。这主要包括将 VLM 以零样本方式部署到机器人感知应用中,将 LLM 的上下文学习能力用于任务层面和运动层面的规划以及动作生成。图 6 展示了一些代表性的研究工作。

随着包含来自真实机器人的状态 - 动作对的机器人数据集的增长,机器人基础模型(RFM)类别同样变得越来越有可能成功。这些模型的特点是使用了机器人数据来训练模型解决机器人任务。这一小节将总结和讨论不同类型的 RFM。首先是能在单一机器人模块中执行一类任务的 RFM,这也被称为单目标机器人基础模型。比如能生成控制机器人的低层级动作的 RFM 或可以生成更高层运动规划的模型。之后会介绍能在多个机器人模块中执行任务的 RFM,也就是能执行感知、控制甚至非机器人任务的通用模型。前面列出了机器人领域面临的五大挑战。这一小节将介绍基础模型可以怎样帮助解决这些挑战。所有与视觉信息相关的基础模型(如 VFM、VLM 和 VGM)都可用于机器人的感知模块。而 LLM 的功能更多样,可用于规划和控制。机器人基础模型(RFM)通常用于规划和动作生成模块。表 1 总结了解决不同机器人挑战的基础模型。
从表中可以看到,所有基础模型都擅长泛化各种机器人模块的任务。LLM 尤其擅长任务规范。另一方面,RFM 擅长应对动态模型的挑战,因为大多数 RFM 都是无模型方法。对于机器人感知来说,泛化能力和模型的挑战是相互耦合的,因为如果感知模型已经具有很好的泛化能力,就不需要获取更多数据来执行领域适应或额外微调。另外,在安全挑战方面还缺乏研究,这会是一个重要的未来研究方向。仅依靠从语言和视觉数据集学到的知识是存在局限的。正如一些研究成果表明的那样,摩擦力和重量等一些概念无法仅通过这些模态轻松学习到。因此,为了让机器人智能体能更好地理解世界,研究社区不仅在适应来自语言和视觉领域的基础模型,也在推进开发用于训练和微调这些模型的大型多样化多模态机器人数据集。目前这些工作分为两大方向:从现实世界收集数据以及从模拟世界收集数据再将其迁移到现实世界。每个方向都各有优劣。其中从现实世界收集的数据集包括 RoboNet、Bridge Dataset V1、Bridge-V2、. Language-Table、RT-1 等。而常用的模拟器有 Habitat、AI2THOR、Mujoco、AirSim、Arrival Autonomous Racing Simulator、Issac Gym 等。该团队的另一大贡献是对本综述报告中提到的论文中的实验进行了元分析,这可以帮助作者理清以下问题:2. 训练模型使用了哪些数据集或模拟器?测试用的机器人平台有哪些?3. 研究社区使用了哪些基础模型?解决任务的效果如何?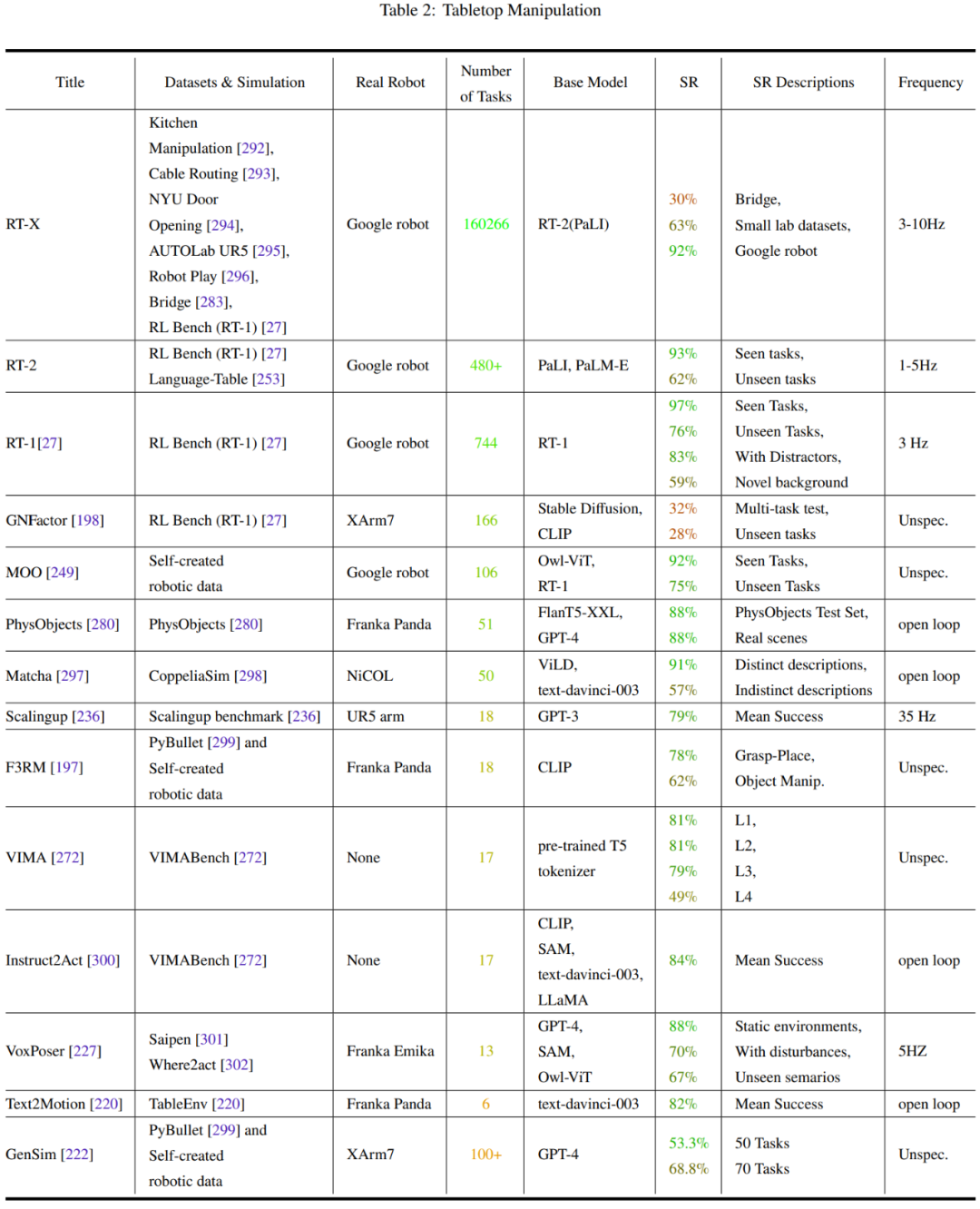






该团队总结了一些仍待解决的挑战和值得讨论的研究方向:
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]